目录
前段时间做了两个NodeJS全栈的小项目,两个小作品 GPT4共享平台和公众号项目ChatGPT学习助手。作为一个前端开发者第一次尝试做全栈开发,后端开发要考虑哪些问题?项目如何平稳的运行?项目虽然是失败了,但是也学到一些技术,今天有空打算系统梳理一下,把知识沉淀下来,另外这两个项目也算是我创业的一种尝试,有一些体会可以作为以后人生道路上的经验。
项目背景
裸辞、失业有快半年了,环境变化的太快,ChatGPT很火,就研究了下,花了一两周的时间,写了个英语学习助手,GitHub链接,由于投稿阮一峰周刊中标,约一周的时间就有100+star了,后来想想能不能变现?决定做一个项目试试看。
大约开发了三周左右,打通了微信登录,微信JSDSK,科学上网,音频播放,session、mysql等瓶颈问题。
后来发现github有个叫pandora的项目很火(但是源代码不开源),相当于部署了一个私人的ChatGPT,可以给多个人用,前期对GPT4的了解(推理能力更强、回答更准确、文生图、丰富的插件),觉得对GPT4感兴趣的人肯定不少,但是GPT4的价格又很贵,而且由于双向墙的存在,很多人想用却用不了。尽管国内也有很多大模型,但国内国外的大语言模型都不能根GPT4比。于是在自己博客上打了个广告,当有第二个第三个人找我时,决定开始尝试这个项目了。自己研究了下Pandora-Next的实现,大致思路是镜像了一份OPENAI的前端资源,拦截OpenAI的接口。另外作者通过github license key限制调用次数,另外由于未知原因一个服务器只能部署一个Pandora-Next项目,因为我做的这个共享平台是违背作者开源免费的精神,万一哪天作者封锁我,这个商业模式就不成立了。所以要解决潜在的过风险,要亲自破解OpenAI接口,花了几天时间解决了打通了第一个接口,Auth通了,其它接口只是时间而已,为了快速试错,还是决定基于Pandora-Next做拦截开发。
我在我的服务器上部署了Pandora-Next,这是第一版,通过网站密码限制访问, 我在知识星球某群拉了几个用户,加上之前博客上找我的,大约有七八个人,就一个账号而且只有20天期限,我卖的是半月卡,人均30。这算是前期调研方案通了,然后赶紧抓紧做这个的项目GPT4共享平台。
我大概用了两周多的时间,完成对pandora-next容器的拦截,接入了微信登录和微信支付的功能。然后预备了6个账号的钱,冲了3个Plus账号,然后在陌生的微信群QQ群打广告,效果很不不好,我又花了几天时间做了个邀请有礼的活动以及其它优化。
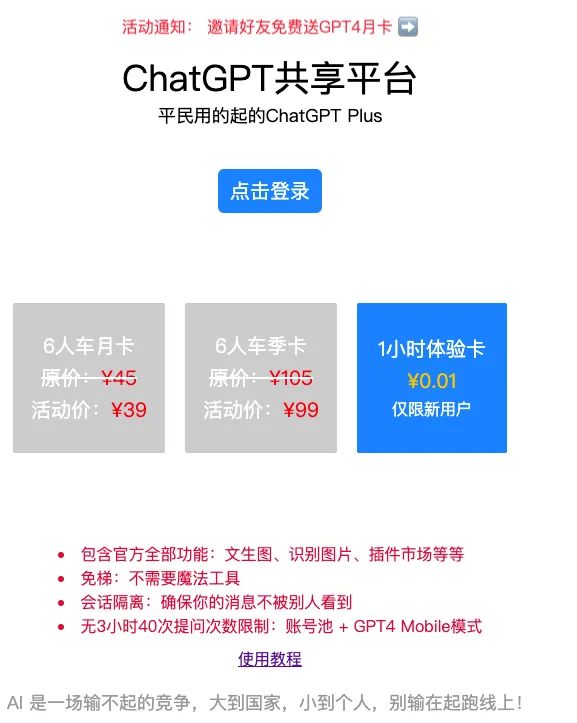

效果依旧不好,总共只拉到3~4个用户,,,我打算放弃了,另一个项目公众号学习助手也没有信心搞了了,毕竟ChatGPT3.5官方是免费用,而我使用APIKey要按量计费啊,收费就难推广,而GPT4的计费是3.5的15~30倍,且没有官方的文生图、插件、GPTS功能,考虑风险、现金流等没有信心在折腾下去了。但是还是收尾,要部署上线,算空窗期的小作品吧。
又花了约一周的时间把学习助手项目上线了,同时也是这一周,OPEN官方做了升级,检测到你是通过某平台使用GPT4会让你输入无尽的复杂的验证码校验,就算我也能破解,但我没时间,没现金流,养家糊口输不起,这算彻底放弃了,于是官网宣告项目失败,退还了几个用户的费用。

另一个项目 公众号学习助手 后来基于ChatGPT-Next-Web 删减了很过高度配置化的东西,加入了语音功能,我用它来学英语
故事到这里就结束了,我简单做一下总结。
- 做这个事情是有争议了,有些黑客,如果在漂亮国就是不正当竞争,但时,我失业有段时间了,加上股市巨亏(半仓恒生半仓中概),2023是我上半生最苦的一年(不多说了),想着如果能够月入几千缓解一下压力,以后有了工作,在关掉这个项目。另外我在多说一句,大家觉得漂亮国对咱们芯片AI及高科技的封锁对吗?中国的企业比漂亮国的企业有更好的营收和利润但估值却远远低于漂亮国的企业。
- 创业是九死一生的事情,个人觉的应该是那些经济上没有多少压力的人才能做的事情,普通人拖家带口输不起!你所想的任何赚钱的方法几乎都有人已经尝试,拿我上面的项目来说,微信里有已AI相关的小程序,也还有专门做账号共享的平台。
- 流量需要花钱购买的,我尝试在微信公众号热帖、视频网站留言 这些都是不可见的,需要博主审核才能展示,一些群也不能发广告,这是人家的的私域,即使你做的广告与他们的业务无关也不行,会被踢出去,QQ群不仅能把你踢出去还能撤销你的消息,不想花钱就得不到流量。
大家当个故事来听听,乐呵一下就行了,作为手艺人,正事是还要接着做手工艺品。
Koa后端开发
这里简单记录下后端开发遇到的一些问题,与前端的不同之处,作为一个前端着手后端开发的注意事项,有一些比较基础的知识点就不说了。
关于AI学习助手这个项目,我最初是使用使用koa独立搭建和开发的,只是看到了开源项目ChatGPT-Next-Web这个项目,才重新开发的。
koa-session
登录认证主流的一种方式是 cookie和session。cookie机制可以保持客户端状态,session用于标记cookie,这样对用户ID用户信息等进行加密,从而保证服务器安全。
由于服务器是单例模式,一个请求过来,我们需要从cookie找session,需要校验会话等,这些就是koa-session做的事情,它除了提供了便捷读写session的方法,还提供了中间件集成(如持久化存储)、安全性处理等事情。
数据持久化
session是存储在内存中的,如果服务器宕机,会导致用户数据丢失,所以需要一种机制先把数据存储在内存中,然后异步同步存储到硬盘上,服务器启动时再从硬盘中读取到内存。
数据持久化方案通尝是redis,它是一种键值存储型数据库,当然也有使用Mysql、MongoDB这种类型的数据库,我的服务器单核,为了节省内存选择了Mysql,对于小业务量其实没有什么影响。下面是一个koa项目集成koa-session和使用mysql持久化的案例
main.ts入口文件
tsimport Koa from 'koa'
import koaMySession from './koaMySession';
const app = new Koa()
app.use(koaMySession(app))
koaMySession.ts
tsimport session from 'koa-session-minimal'
import MysqlSession from 'koa-mysql-session'
const { DB_HOST, DB_PORT, DB_PASSWORD, DB_NAME, SESSION_KEY } = process.env
// 配置存储session信息的mysql
const store = new MysqlSession({
user: 'root',
password: DB_PASSWORD,
database: DB_NAME,
host: DB_HOST,
port: +DB_PORT
})
// 存放sessionId的cookie配置,根据情况自己设定
const cookie = {
maxAge: 30 * 24 * 3600 * 1000, // cookie有效时长(ms)
// expires: '' as unknown as Date, // cookie失效时间
path: '/', // 写cookie所在的路径
domain: 'warmplace.cn', // 写cookie所在的域名
httpOnly: true, // 是否只用于http请求中获取
overwrite: true, // 是否允许重写
secure: false,
sameSite: true,
signed: true
}
export default (app: any) => {
app.keys = [SESSION_KEY] // signed 好像不起作用
return session({
key: 'USER_SID',
store,
cookie
}, app)
}
- 使用起来也很简单修直接对
ctx.session.user对象进行读写
session数据会落库数据库

跨域问题,自己写了一个中间件
tsimport { type Context } from 'koa'
/**
* 关键点:
* 1、如果需要支持 cookies,
* Access-Control-Allow-Origin 不能设置为 *,
* 并且 Access-Control-Allow-Credentials 需要设置为 true
* (注意前端请求需要设置 withCredentials = true)
* 2、当 method = OPTIONS 时, 属于预检(复杂请求), 当为预检时, 可以直接返回空响应体, 对应的 http 状态码为 204
* 3、通过 Access-Control-Max-Age 可以设置预检结果的缓存, 单位(秒)
* 4、通过 Access-Control-Allow-Headers 设置需要支持的跨域请求头
* 5、通过 Access-Control-Allow-Methods 设置需要支持的跨域请求方法
*/
const koaCors = async (ctx: Context, next: any) => {
const { CORS } = process.env
if (CORS) {
ctx.set('Access-Control-Allow-Origin', CORS)
ctx.set('Access-Control-Allow-Methods', 'POST, GET, OPTIONS, DELETE, PUT')
ctx.set('Access-Control-Allow-Headers', 'X-Requested-With, User-Agent, Referer, Content-Type, Cache-Control, accesstoken')
ctx.set('Access-Control-Max-Age', '86400')
ctx.set('Access-Control-Allow-Credentials', 'true')
}
if (ctx.method !== 'OPTIONS') {
await next()
} else {
ctx.body = ''
ctx.status = 204
}
}
export default koaCors
在入口文件main.ts加载中间件app.use(koaCors)
前端静态资源
早期前后端不分离,html是由后端模版编译而成,NodeJS相关的类库有Pug(之前称为 Jade) 和EJS,然而我习惯了前后端分离的方案。可以借助koa-static-server或Nginx把前端资源静态出去。
一开始我想把把前后端打包后的资源整合在一个容器里,所以选择 koa-static-server方案,但是它是对资源的统一配置,不支持特定资源的单独配置,通常前端资源打包后有hash值,可以配置为强缓存,但是index.html不能强缓存,可以走协商缓存或不缓存,为此我写了一个中间件
tsimport { type Context } from 'koa'
import path from 'path'
import koaStaticServer from 'koa-static-server'
const options = {
// 前端资源打包后的文件夹
rootDir: path.join(__dirname, '../../build'),
rootPath: '/',
maxage: 1,
notFoundFile: './index.html'
}
const staticServer = koaStaticServer(options)
const warpStaticServer = async (ctx: Context, next: any) => {
if (ctx.method !== 'HEAD' && ctx.method !== 'GET') {
return next()
}
// index.html不缓存
const { pathname } = ctx.URL
if (!/\.(\w+)$/.test(pathname)) {
ctx.path = options.rootPath;
// options.maxage = 0;
(options as any).setHeaders = () => {
ctx.set({
'Cache-Control': 'no-store'// 不缓存
})
}
} else {
// options.maxage = maxage
delete (options as any).setHeaders
}
await staticServer(ctx as any, next)
}
export default warpStaticServer
另外补充一点,作为前端我们通常认为http协议的内容,比如304状态码,If-None-Match/Etag,不返回响应体 等我们不需要处理, 其实浏览器实现了一部分,还有一部分需要z在服务端编程,koa-static-server就是做了这些事情。
koa-body
koa-body是用来解析请求体的,包括表单类型、JSON类型、文件上传等。它根据请求头中的Context-Type自动选择相应的解析器,我们可以从ctx.request.body对象中读取
koa-router
koa-router 通常使用来处理API分发的,相当于Controller。接入示例如下
- 加载中间件
tsimport api from './routes'
app.use(api.routes())
routes.ts
tsimport user from './user'
import Router from 'koa-router'
const router = new Router()
router.prefix('/api/')
router.use(user.routes(), user.allowedMethods())
router.get('/', async ctx => {
ctx.body = 'api'
})
export default router
export { user }
user.ts
tsimport Router from 'koa-router'
const router = new Router()
router.prefix('/'); // 可以接着配置前缀
router.get('/checkLogin', (ctx) => {
ctx.body = '检查用户登录';
})
// 动态路由
router.get('/:id', (ctx) => {
const userId = ctx.params.id;
ctx.body = `User ID: ${userId}`;
})
export default router
日志监控
日志监控这一块有两个常用的类库 koa-logger和log4js
通常来时开发调试使用koa-logger,它会打印到控制台。
而log4js主要用于生产环境,它会记录的日志文件中。
logger.ts
tsimport log4js from "log4js";
log4js.configure({
appenders: {
cheese: {
type: "dateFile",
filename: "logs/cheese",
pattern: "-yyyy-MM-dd.log",
alwaysIncludePattern: true,
category: "normal",
},
complaint: { type: "file", filename: "logs/complaint.log" },
},
categories: {
default: { appenders: ["cheese"], level: "info" },
},
});
const logger = log4js.getLogger("cheese");
export default logger;
- 在需要记录日志的地方调用
logger方法
错误处理
错误处理,通常是使用koa-onerror,它会捕捉全局的错误,还能在生产环境下提供友好的界面展示。以下是一个接入示例
tsconst Koa = require('koa');
const onError = require('koa-onerror');
const app = new Koa();
// 错误处理中间件,应该在其他中间件之前使用
onError(app);
我们还可以自定义一个中间件处理错误
tsimport { type Context } from 'koa'
const koaError = async function (ctx: Context, next: any) {
try {
await next()
} catch (_err: any) {
const err = _err || new Error('Null or undefined error')
ctx.app.emit('error', err, ctx)
ctx.set('Cache-Control', 'no-cache, max-age=0')
ctx.status = err.status || 500
ctx.type = 'application/json'
const resp = err.response || {}
ctx.body = {
code: err.code,
error: resp.body || err.error,
message: err.message
}
// 在开发环境下,显示错误堆栈信息
if (process.env.NODE_ENV === 'development') {
ctx.body.stack = err.stack
}
}
}
export default koaError
数据库选型
对于小项目而言,有Mysql和MongoDB两个主流的数据库供选择选择,各有各的优缺点,MongoDB是JSON型数据库对JS友好,MySql是结构型数据,性能会更好,但要先设计表结构。
考虑我曾经有对Mysql系统学习,虽然工作中没用过,但是有记笔记,看看笔记能快速上手,有对Mysql整体全面的了解,在设计方面是也不会出现大的纰漏。
我没有使用ORM型类库,自己手写sql语句
关于sql 有空在单独写篇文章
服务器科学上网
我了解的服务器科学上网有三种方案,
- host配置
- 国内服务器安装VPN及代理软件, 比如
warp-cli和v2ray - 在cloudflare平台上配置Worker和自定义域名
- 购买国服务器(且不需要备案)
host配置,可以通过ping命令在国外服务器或开启了代理的电脑上获取IP地址。该方式解决的场景很有限,比如OPENAI的接口就不行,另外也不稳定。
安装warp-cli 设置为proxy模式,再通过 Node HTTP 代理或 v2ray 分流完成特定域名的科学上网,但是warp的流速很窄,没办法扩流。
我在cloudflare上购买了一个便宜的域名(约5美元一年),配置了worker和自定义域名,这样就可以调通OpenAI接口了
jsaddEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
async function handleRequest(request) {
// 目标 URL
const url = new URL(request.url)
// 更改域名(或路径)
url.host = 'api.openai.com'
// 创建新的请求对象
const newRequest = new Request(url, request)
// 转发请求到目标地址
return fetch(newRequest)
}
另有还有一种的方式最简单,就是购买海外服务器,但是海外服务器要通常都比国内贵。
NextJS全栈开发
NextJS是React服务端渲染的框架,也是一个全栈开发的框架。
因为ChatGPT-Next-Web项目是使用NextJS开发的,没办法我要学NextJS,不过我没有用它的服务端渲染方面的东西,只是用它来做一个全栈项目。
它的核心功能
| 功能点 | 描述 |
|---|---|
| 路由 | 路由基于文件系统的路由器构建在服务器组件之上,支持布局、嵌套路由、加载状态、错误处理等。 |
| 渲染器 | 渲染使用客户端和服务器组件进行客户端和服务器端渲染。使用 Next.js 在服务器上进一步优化静态和动态渲染。在 Edge 和 Node.js 运行时上进行流式传输。 |
| 数据获取 | 数据获取通过服务器组件中的 async/await 简化数据获取,以及用于请求记忆、数据缓存和重新验证的扩展获取 API |
| 样式 | 样式支持您首选的样式方法,包括 CSS 模块、Tailwind CSS 和 CSS-in-JS |
文件目录
txt|- public 静态资源 |- src 应用程序 |- app 应用路由器 |- pages 页面路由器 |- middleware.ts 中间件 |- next.config.js 应用配置文件 |- package.json
NextJS的路由
NextJS的路由是基于文件目录的,NextJS有页面路由器(旧)和APP路由器(新)
src/app文件结构如下
txt|- layout.tsx 应用入口,相当于html |- page.tsx 应用入口 |- loading.tsx |- not-found.tsx |- error.tsx |- folder 文件夹 路由片段 可嵌套 |- [folder] 动态路由片段 |- [...folder] 任意子路由匹配 |- [[...folder]] 可选的任意子路由
nextjs提供了 next/router,可以通过useRouter获取url上的query参数, 可以通过next/link和useRouter前端路由跳转, 但是重定向是要在next.config.js中配置。当然你也可以使用react-router-dom, 修改src/app/page.tsx即可,ChatGPT-Next-Web就是这样做的。
API路由
nextJS通过约定配置的方式定义路由
tsasync function handle(req: NextRequest) {
// 获取url参数
const { searchParams } = new URL(req.url);
const code = searchParams.get("code")!;
// 获取body参数示例
const body = await req.json();
const headers = new Headers();
// const headers = new Headers(oldHeaders);
headers.set('custome-header', 'custome-header-value')
// headers.delete("www-authenticate");
headers.append(
"Set-Cookie",
`user_session=${_res2.openid}; Max-Age=${maxAge}; ${domainStr}; Path=/; SameSite=Lax${secureStr}`,
);
const resp = {...};
return NextResponse.json(resp, {
headers,
status: 200, // 状态码
statusText: "success",
});
}
async function handler2(
req: NextApiRequest,
res: NextApiResponse
) {
try {
const result = await someAsyncOperation()
res.status(200).json({ result })
} catch (err) {
res.status(500).json({ error: 'failed to load data' })
}
}
// 配置支持的请求方法
export const POST = handle;
// export const GET = handle;
// 定义接口配置
export const config = {
api: {
bodyParser: {
sizeLimit: '1mb',
},
responseLimit: false,
},
maxDuration: 5,
}
// 定义运行环境,默认是nodejs
// edge指的是Vercel 的 Edge 环境, 有一些限制,例如不能执行文件系统操作
export const runtime = "edge";
中间件
中间件允许您在请求完成之前运行代码。然后,根据传入的请求,您可以通过重写、重定向、修改请求或响应标头或直接响应来修改响应。
中间件在缓存内容和路由匹配之前运行。
tsimport { NextResponse } from 'next/server'
import type { NextRequest } from 'next/server'
// This function can be marked `async` if using `await` inside
export function middleware(request: NextRequest) {
return NextResponse.redirect(new URL('/home', request.url))
}
// See "Matching Paths" below to learn more
export const config = {
matcher: '/about/:path*',
}
注意
中间件目前仅支持 Edge 运行时。无法使用 Node.js 运行时。
也就是说无法使用 path、mysql等相关api
安全问题
有开发经验的同学都了解,前端故障往往是小问题,后端故障是大问题,安全无小事,所以前期尝试宁可界面low一点粗糙一点,也不能有安全问题。在做GPT4共享平台的时候,我充分考虑了一些安全问题,比如扫码登录、sql注入、内存泄漏、支付问题、权限校验等问题,这里记录一下我的设计思路
扫码登录二维码
GPT4共享平台支持PC和移动端登录。
移动端是通过微信扫码登录,接入的是微信公众号网页授权登录;
但是PC网站登录要接入微信开发平台才能实现微信登录,接入步骤与实现与微信公众号网页登录几乎一样。但是要添一堆资料,当然这是小事情,重点是要微信开放平台认证还要花费300元(之前公众号认证已花费了300)。
我想到了一种变通方案,使用微信公众号的网页登录进行中转。具体步骤如下:
- PC网页上点击 “登录” 弹出二维码,二维码url中含有一个特殊的标志
loginID,此时会轮训用户是否扫码并点击登录 - 用户使用手机微信客户端扫码二维码,打开了一个新网页,用户点击登录,获得微信的
code,然后ajax提交,服务端通过code换取用户信息存储到内存中 - PC网页轮训,通过
loginID拿到用户信息,完成登录。
为了防止别人伪造loginID, loginID是在服务端加密生成,原文含有每个规律比如固定前缀或者前缀小于某个数,此外loginID还具有时效性,没错就用的时间戳。
还要防止内存泄漏,检测到PC端登录完成会回收内存中的用户对象,如果loginID的过了时效,也会回收内存中的用户对象。
还有就是用户购买了会员可能会把账号分享给别人用,所以做了限制,只允许两台设备登录。原理很简单,每登录一次就往sql表中插入一条记录,访问接口时校验是不是最近两次登录颁发的token,如果不是要重新登录。
权限校验防白嫖
限制两台设备登录是防止用户白嫖我的一种方式。此外还要处理会员到期后要重定向到购票页面,这个走的定时任务,在服务端销毁token。
邀请码生成
与loginID的生成类似,邀请码也是用时间戳生成的,只不过直接使用时间戳生成的话会有规律,前面的字母一致,因此我对时间戳做了反转,这样十进制转换为36进制,就看不出规律了,另外邀请码不能太长,因此截取了时间戳的中间部分。这样邀请码是 1~6位,对邀请码长度的校验也防止了sql注入
sql注入
sql注入是指用户输入的数据(值)当成了sql程序来执行了,这样一步一步推敲你的sql版本,表结构,数据等。为此所有依赖客户端标记查询的地方都做了校验, 如token、loginID等进行了正则校验。
关于sql注入的预防,感兴趣的可以看我的另一篇文章
支付问题
我接入了微信支付,微信支付把安全做到了极致!我们做Web开发使用HTTPS协议即可以防止消息被监听。我们假设一种极端场景浏览器证书的颁发机构和DNS厂商合伙还是可以监听到我们的消息,那么微信支付就是重塑一套安全体系,相当于双层加密(第一层是HTTPS)。
我们先来梳理一下密码学的知识,这个微信支付接入来说非常重要的基础知识。
密码学知识
- 加密技术的底层原理是 异或运算,通过分组使得短密码对长内容加密。普通分组ECB加密无法完全隐藏数据特征;CBC分组对数据分块串行加密隐藏了数据特征,但串行效率低,无法利用多核CPU优势;CTR分组模式通过某种算法产生一个密钥流,这样就可以并行加密了;为了解决网络传输数据丢失问题还需要MAC哈希算法校验消息的完整性。这就是对称加密的大致原理。
- 哈希算法也叫摘要算法,对于任意长度经过hash运算得到固定长度的摘要,也叫数据指纹,如果原文有任意微小改动,都会导致摘要内容大变,因此摘要算法用于保证原文不被篡改。
- 使用对称加密前提是对方要提前知道密码,或者想办法把密钥安全的传输过去,这就用到了非对称加密技术。明文使用私钥加密得到密文,密文使用公钥解密得到明文,但由于公钥是公开的,则需要两对非对称加密密钥,我给你消息,使用你的公钥加密,你给我发消息使用我的公钥加密。
- 公钥加密,私钥解密的作用是加密信息
- 私钥加密,公钥解密的作用是身份认证
- 由于非对称加密非常消耗性能,所以通常是使用非对称加密协商出对称加密的密钥,之后使用对称加密算法传输消息。
我们来看一个例子,Bob给Pat写信,如何保证信的内容不配篡改呢?
- Bob对信的内容进行hash运算,得到摘要,然后使用自己的私钥加密摘要得到签名,将签名和信件发送给Pat
- Pat收到信件使用Bob的公钥对签名解密得到摘要1,然后在使用和Bob相同的hash算法对信件进行hash运算得到摘要2,如果摘要1和摘要2一样则信件的内容就没有被篡改过,这个过程也叫验签
虽然信件不能被篡改,但是可以冒充Bob给Pat写信,具体如下:
Doug给Pat写信,给了Pat自己的公钥,但是欺骗Pat说自己是Bob,这也是Bob的公钥,Pat使用公钥和hash算法验证签名证明了信件没有改动,但他不知道对方是不是Bob。
解决这个问题就需要用到数字证书 来防止公钥的伪造
数字证书包含的信息
- 公钥:Bob的公钥
- 所有者:Bob
- 颁发者:CA(证书认证机构)
- 有效期:证书的使用期限
- 签名哈希算法:指定摘要算法,用来计算证书的摘要
- 指纹:证书的摘要,保证证书的完整性,保证证书不被篡改
- 签名算法:用于生成签名,确保证书是由CA签发
- 序列号:证书的唯一标识
Bob来到证书机构,提供了自己基本信息(公钥、有效期、所有者等信息)
CA用指定的hash算法对上述内容进行Hash运算得到摘要(也叫指纹),然后CA再用自己的私钥加密摘要得到签名,将签名和证书一起发给Bob
Bob拿到数字证书后,再给Pat写信就放心了,他只要写信的时候附带上这个数字证书即可
Pat收到信件,先取出数字证书,和前面的验签流程一样,验证数字证书合法,取出里面的Bob的公钥,再次对信的内容进行验证前面
Doug没有办法伪装成Bob了,因为数字证书中定义了证书所有者,他去证书机构获取数字证书必须提供真实身份信息。
那么Doug如果偷偷的得到Bob的数字证书会怎样呢?
Doug就可以伪装Bob给Pat写信了,所以数字证书丢失就要去证书机构吊销。
那么引入数字证书还是不够安全啊?我们来看一下浏览器怎样解决的。 浏览器HTTPS协议在握手时会生成三个随机数,前两次握手服务器客户端各自产生一个随机数,并协商其它信息(加密套件、协议版本)。第二次握手服务器把自己的证书发给客户端,客户端拿到证书请求CA机构验证证书的合法性及有效期,然后取出服务器公钥,再产生一个随机数,这个三个随机数使用某种算法加密得到MasterSecret,再使用公钥加密随机数发给服务器,服务器使用私钥解密第三个随机数,加上前面两个随机数就可以合成MasterSecret,之后就使用这个密码进行对称加密传输数据。
那么中间人可以提前请求服务器得到该服务器的公钥,可以对通信进行监听吗?
不可以,因为第三个随机数的存在,即使中间人得到服务器公钥,由于没有服务器私钥所以就无法解密这个随机数,就无法解密服务器和客户端的消息。
虽然不能破解消息的内容,但是可以把消息保存下来,将来有一天破解了服务器私钥,不就可以读取历史消息内容了吗?(消息的前向保密性)
为此浏览器又设计密钥交换协议,早期时使用DH密钥交换协议,后来使用更先进的ECDH密钥交换协议。 浏览器和客户端各自生成一对公私钥对,分别把公钥发送给对方,t再利用椭圆曲线的特性合成MasterSecret,(椭圆曲线公式 a和b 就是公钥 x和y对应私钥,利于椭圆曲线的“+”特性,合成MasterSecret)。尽管中间人破解了服务器私钥,但由于每次新开会话,客户端会重新生成一对公私钥,中间人依旧无法破解历史消息的内容。
微信支付
前面解释这么多密码学知识都是为了理解微信支付做铺垫。
微信支付有两个版本APIV2和APIV3 接入文档
主要区别如下

微信没有提供关于NodeJS的SDK,社区提供了一个版本wechatpay-node-v3-ts 但是文档比较简陋,为了深入理解原理,我是直接将源码copy到我的项目里使用的,这样也能断点调试了。
接入微信支付前的准备工作
- 申请证书商户证书
- 平台证书(平台证书是有有效期的,所以需要一个定时任务更新证书)
- APIV3密钥, 这个是对称加密的密钥
微信支付的流程图
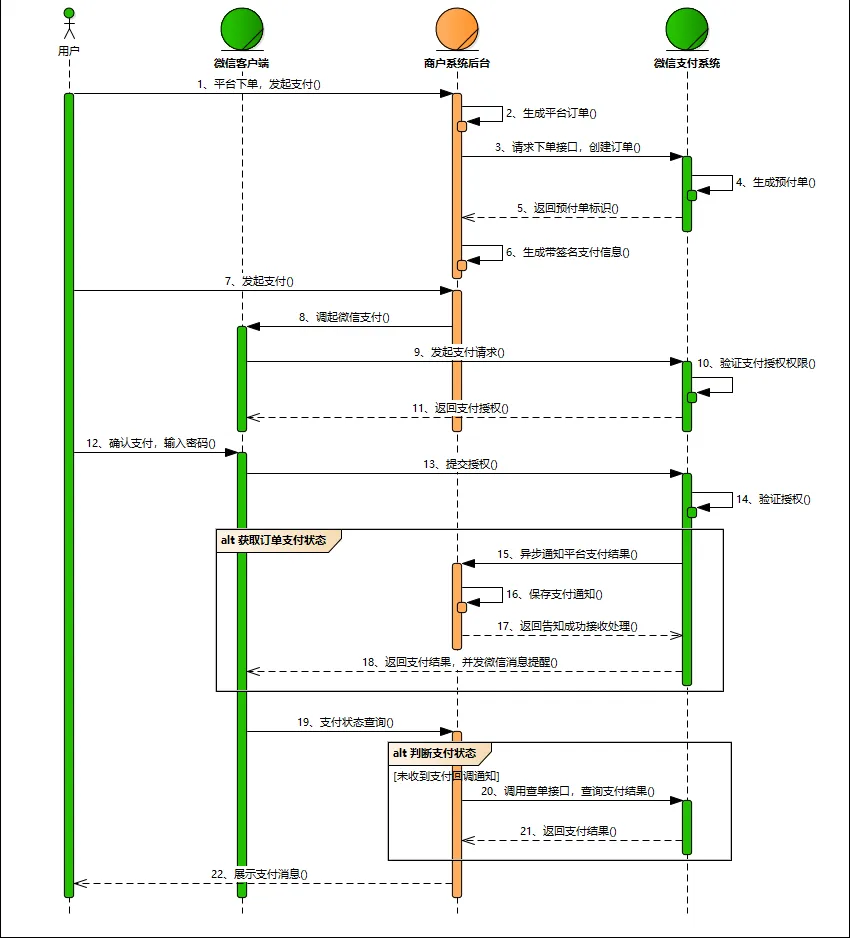
大致实现思路
- 生成预支付单号,请求微信接口要使用微信平台证书(公钥)对请求数据进行签名,微信响应后,要对请求头进行验证签名(使用商户私钥)
- 验签成功要生成JSSDK参数并签名(使用商户私钥),JSSDK唤起支付
- 支付成功微信会回调服务器(回调地址是第一步配置的),照例先验签,然后对body中的ciphertext字段进行解密(使用APIV3密钥),告知微信收到通知。
核心步骤就这些,但支付安全是大事,有很多细节问题要处理,如下
- 预支付订单两个小时内有效,防止用户重复生成订单
- 对支付回调数据落库,要进行事务处理。
- JSSDK支付成功,开启轮训,以服务端状态为准
- 对于微信回调通知,要注意并发问题,保持接口幂等,还要防止日志重复。
- 极端情况下可能收不到微信通知,需要定时任务主动请求微信服务器查询订单状态
- 预支付订单超时要通知微信关闭订单(建议)
- 定时任务更新平台证书。
本文作者:郭郭同学
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!