目录
我们知道计算机是通过二进制进行运算和文件存储的,当我们打开查看一个文件或访问网站时经常会遇到乱码问题,那么为什么会出现乱码?什么情况下出现出现乱码?为什么有那么多字符集?乱码后的文件还能恢复吗?本篇文章将从字符集的发展史来为你解答上述疑惑。
二进制与编码
背景:
- 所有现代计算机都是冯诺依曼体系计算机
- 冯诺依曼计算机 将数据与程序一起存储,
- 基于二进制进行运算和存储
- 所有数据在计算机底层都是以二进制的形式保存
- 可以将内存想象为一个多个小盒子组成的容器,每个小格子可以存储一个1或一个0,这个小格子在内存中被称为1位(bit)
-
8bit = 1byte(字节)
1024byte = 1kb(千字节)
1024kb = 1mb (兆字节)
1024mb = 1gb (吉字节)
1024gb = 1tb(特字节)
1024tb = 1pb
-
编码与解码
- 将字符 转换为二进制码的过程 称为编码
- 把 “中国” 两字写入txt文件内,计算机存储的是
101100001011110 - 将二进制码 转换为 字符的过程 称为解码
- 打开txt文件显示 “中国” , 从计算机中读取
101100001011110后转换成 “中国” 显示出来
- 打开txt文件显示 “中国” , 从计算机中读取
- 字符集(charset) 编码和解码所采用的规则
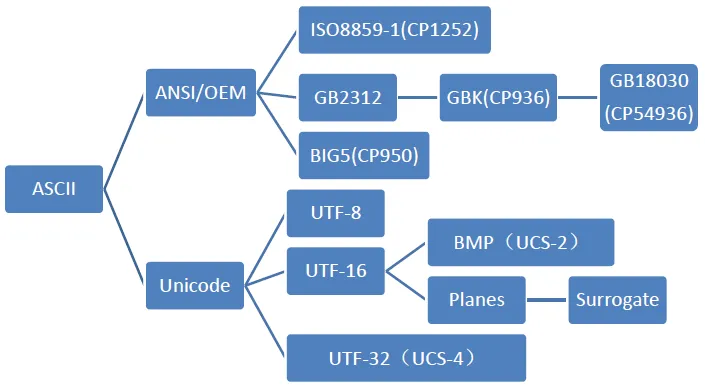
- 常见的字符集 ASCII ISO88591 GB2312 GBK UTF-8(万国码)
- 我们在开发过程中通常使用UTF-8
- 乱码问题
- 如果编码和解码所采用的字符集不同 就会出现乱码问题
计算机字符编码的发展历史
从计算机字符编码的发展历史角度来看,大概经历了三个阶段:
第一阶段:ASCII字符集和ASCII编码
计算机是美国人发明的,因此美国人在一开始设计计算机的时候只考虑英文,其他语言不能够在计算机上存储和显示。ASCII用一个字节(Byte)的7位(bit)表示一个字符,第一位置0。后来为了表示更多的欧洲常用字符又对ASCII进行了扩展,又有了EASCII,EASCII用8位表示一个字符,使它能多表示128个字符,支持了部分西欧字符。
第二阶段:ANSI编码(本地化)
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的2个字节来表示1个字符。比如:汉字 ‘中’ 在中文操作系统里,使用 [0xD6,0xD0] 这两个字节存储。不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用2个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
GB2312、GBK、GB18030 这几种字符集
1 GB2312
GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB 0,由中国国家标准总局发布,1981 年 5 月 1 日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312标准共收录 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75% 的使用频率。- 对于人名、古汉语等方面出现的罕用字,
GB2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。
GB2312对任意一个图形字符都采用两个字节表示2 GBK
GBK即 汉字内码扩展规范,K 为汉语拼音 Kuo Zhan(扩展)中“扩”字的声母。英文全称 Chinese Internal Code Specification。
GBK共收入 21886 个汉字和图形符号
GBK向下与GB2312完全兼容,向上支持ISO 10646国际标准,在前者向后者过渡过程中起到的承上启下的作用。
GBK 采用双字节表示,总体编码范围为 8140-FEFE 之间,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 XX7F 一条线。 GBK 编码区分三部分:汉字区、图形符号区 用户自定义区3
GB18030GB 18030,全称:国家标准 GB 18030-2005《信息技术中文编码字符集》,是中华人民共和国现时最新的内码字集,是 GB 18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》的修订版。 GB 18030 与 GB 2312-1980 和 GBK 兼容,共收录汉字70244个。
- 与 UTF-8 相同,采用多字节编码,每个字可以由 1 个、2 个或 4 个字节组成。
- 编码空间庞大,最多可定义 161 万个字符。
- 支持中国国内少数民族的文字,不需要动用造字区。
- 汉字收录范围包含繁体汉字以及日韩汉字
GB 18030 编码是一二四字节变长编码。
- 单字节,其值从 0 到 0x7F,与 ASCII 编码兼容。
- 双字节,第一个字节的值从 0x81 到 0xFE,第二个字节的值从 0x40 到 0xFE(不包括0x7F),与 GBK 标准兼容。
- 四字节,第一个字节的值从 0x81 到 0xFE,第二个字节的值从 0x30 到 0x39,第三个字节从0x81 到 0xFE,第四个字节从 0x30 到 0x39。
第三阶段:UNICODE编码(国际化)
UNICODE编码
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。
- 目前,Unicode的最新版本是14.0版,一共收入了超过14W个符号。
- 这么多符号,Unicode不是一次性定义的,而是分区定义。
- 每个区可以存放65536个(
2**16)字符,称为一个平面(plane)。 - 目前,一共有17个(25)平面,也就是说,整个Unicode字符集的大小现在是
2**21。 - 17个平面分为一个基本平面(缩写BMP)和 16个辅助平面(缩写SMP)
- 基本平面 它的码点范围是从0一直到
2**16-1,写成16进制就是从U+0000到U+FFFF是Unicode最先定义和公布的一个平面 - 剩下16个辅助平面,码点范围从
U+010000一直到U+10FFFF
然而,Unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,文本文件的大小会因此大出两三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了Unicode的多种存储方式。
UNICODE 常见的有三种编码方式:UTF-8(1~4个字节表示)、UTF-16(2或4个字节表示)、UTF-32(4个字节表示)。
UTF-32
UTF-32采用最直观的编码方法,每个码点使用四个字节表示,字节内容一一对应码点。
它的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大四倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5标准就明文规定,网页不得编码成UTF-32。
UTF-8
最流行的编码格式要数 UTF-8
txtUnicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) -------------------------+------------------------------------- 0000 0000 ~ 0000 007F | 0xxxxxxx 128 2**7 0000 0080 ~ 0000 07FF | 110xxxxx 10xxxxxx 2048 2**11 0000 0800 ~ 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 65536 2**16 0001 0000 ~ 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 2097152 2**21
思考
utf8存储1-4字节的数据为什么设置前缀?
- 这是因为计算机按自己读取数据,设置前缀能区分一个字符的开始和结束
- 比如0开头的就是一个字节;110开头的是两个字节,与接下来的一个字节共同构成一个字符
注意Unicode的字符编码和UTF-8的存储编码表示是不同的,例如”严”字的Unicode码是4E25,UTF-8编码是E4B8A5,这个在7步骤里面做过解释,UTF-8编码不仅考虑了编码,还考虑了存储,E4B8A5是在存储识别编码的基础上塞进了4E25。
”严”字的Unicode码是4E25,UTF-8编码是E4B8A5 0x4E25.toString(2) 100_111000_100101 共15位 需要三字节存储,套用3字节 11100100_10111000_10100101 == 0xE4B8A5.toString(2)
UTF-8 使用一至四个字节为每个字符编码。128 个ASCII字符(Unicode 范围由 U+0000 至 U+007F)只需一个字节,带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及马尔代夫语(Unicode 范围由 U+0080 至 U+07FF)需要二个字节,其他基本多文种平面(BMP)中的字符(CJK属于此类)使用三个字节,其他 Unicode 辅助平面的字符使用四字节编码。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
UTF-16
UTF-16它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。
也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)
于是就有一个问题,当我们遇到两个字节,怎么看出它本身是一个字符,还是需要跟其他两个字节放在一起解读?
巧合的一点是,从U+D800到U+DFFF是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
javascript// 为了方便理解我加了“_”每4位区分一下
0xD800.toString(2)
'1101_1000_0000_0000'
0xDFFF.toString(2)
'1101_1111_1111_1111'
具体来说,辅助平面的字符位共有2**20个,也就是说,对应这些字符至少需要20个二进制位。UTF-16将这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小2**10),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小2**10),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。计算机读取前两位编码是意识到这是一个4字节字符,会把后面的两个字节连接在一起,通过运算得到Unicode编码进而显示给用户看。具体运算规则,这里不做阐述,想要了解的点击这里
BOM格式编码
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space) BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记。
UTF编码 ║ Byte Order Mark UTF-8 ║ EF BB BF UTF-16LE ║ FF FE UTF-16BE ║ FE FF UTF-32LE ║ FF FE 00 00 UTF-32BE ║ 00 00 FE FF // LE 即 little-endian,小端的意思。小端就是将高位的字节放在高地址表示 // BE 即 big-endian,大端的意思。大端就是将高位的字节放在低地址表示
如果一个文件
- FF FE 00 00 开头表示 它使用的是 UTF-32LE 编码
- 00 00 FE FF 开头表示 它使用的是 UTF-32BE 编码
- 以 FF FE 开头表示 它使用的是 UTF-16LE 编码
- 以 FE FF 开头表示 它使用的是 UTF-16BE 编码
- 没有标头或者 EF BB BF 开头表示 它使用的是 UTF-8 编码
微软做这种检测,但有些软件不做这种检测, 而把它当作正常字符处理。 这个BOM头只是建议添加,不是强制的,所以不少软件和系统没有添加这个BOM头(所以有些软件格式中有带BOM头和NoBOM头的选择)
参考资料: 字符,字节与编码
说了这么多,好像跟JS没啥关心吧,平时也用不到,,, 下面来说一下字符集与JS之间的关系
JS与字符集
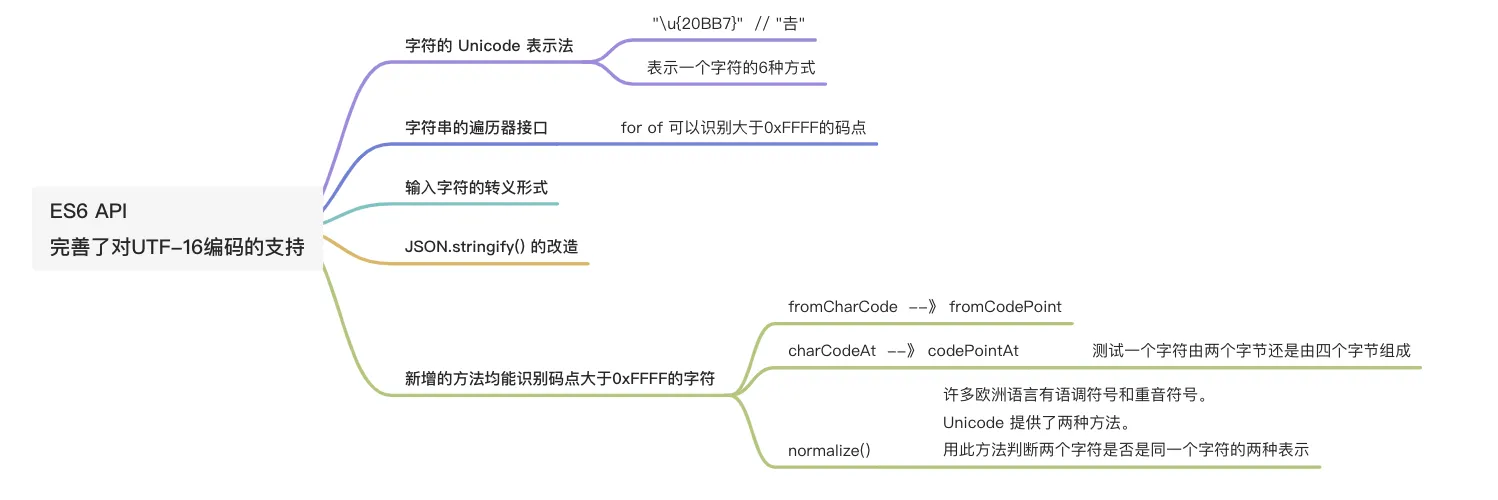
JavaScript语言采用Unicode字符集,但是只支持一种编码方法。
这种编码既不是UTF-16,也不是UTF-8,更不是UTF-32。上面那些编码方法,JavaScript都不用。
JavaScript用的是UCS-2!
JS诞生于1995年,关于Unicode编码,那时候只有1990年公布了第一套编码方法UCS-2。它使用2个字节表示已经有码点的字符。
而UTF-16在1996年才公布。 两者之间的关系:UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16
ES6之前的字符串方法存在的问题
`JavaScript`的字符函数都受到这一点的影响,无法返回正确结果。
js// 在Unicode-16编码中, 一个中文字符可能是2个字符,也可能是4个字符,
// 𠮷 和 𝌆 是4字节字符
const str = 'a吉b𠮷c𝌆d';
console.log(str.length); // 9 表示9个双字节字符
console.log([...str].length);
console.log(getStrLength(str));
// 现在能不能理解识别汉字字数的方法?
function getStrLength(str) {
let count = 0;
for (let i=0; i < str.length; i++) {
++count;
if (/^[\uD800-\uDBFF]$/.test(str[i])) {
++i;
}
}
return count
}
如判断textarea有多少文字时, 很多前端开发者大都会用.length属性计算吧,
假设文本内容如下 a吉b𠮷c𝌆d
但是如果产品的想法是把中文也算成一个字符呢?
es5确实不好处理,想要弄出还的搞懂编码,es6却非常方便[...'a吉b𠮷c𝌆d'].length
对于es6之前所有所有的JavaScript字符操作函数该问题(把四字节的字符当成两个双字节处理)
String.lengthString.prototype.replace()String.prototype.substring()String.prototype.slice()
es6对4字节字符的支持
HTML与编码
由于下面的原因,不是每一个 Unicode 字符都能直接在 HTML 语言里面显示。
- 有些 Unicode 字符 没有可打印形式 。 比如换行符的码点是十进制的10(十六进制的A)
- 小于号(<)和大于号(>)用来定义 HTML 标签,其他需要用到这两个符号的场合,必须防止它们被解释成标签。
- 没有一种键盘,有办法输入所有符号。
- 网页不允许混合使用多种编码
HTML 为了解决上面这些问题,允许使用 Unicode 码点表示字符,浏览器会自动将码点转成对应的字符。 字符的码点表示法有两种
- 十进制
&#N; - 十六进制
&#xN;
html<p>hello</p>
<!-- 等同于 -->
<p>hello</p>
<!-- 等同于 -->
<p>hello</p>
但是数字表示法很难记忆,所以有了字符的实体表示法
<:<>:>":"':'&:&空格:
浏览器乱码问题
通常window电脑采用gbk编码,如果编写的文件没有声明编码方式,默认浏览器是采用utf-8解析,这就导致了乱码。
具体来说,浏览器有一套自己的编码解析机制
- 文件开头的 Byte Order mark 字符
- http响应头字段content-type
- html
<meta @charset='XX'> - 默认utf-8
总结
1. 简述各种编码之间的关系
- 编码的发展史分三个阶段 1) ASCII 2) ANSI 编码本地话,但不能国际传输 3)unicode utf-8
- gbk2312 与 gbk字符集同属于ANSI , 前者采用2个字节存储,覆盖中国大陆99.75%使用频次的文字,后者是前者的扩充,采用多字节编码
- unicode为世界上每种语言的每一个字符规定了编码,但没有规定如何存储
- 举例来说一个一篇英文文本文件,如果每个字符都用三个或四个字节储存造成存储空间的浪费。如何来存储呢,所以有 utf-8 utf-16 utf-32, 比较流行的是utf-8
- utf-8采用可变长的编码方式,使用一至四个字节为每个字符编码。
- BOM格式编码 识别是使用unicode编码的哪一种字符集
2. 编码、解码、字符集之间的关系,乱码是怎样形成的
- 将字符转换成二进制的形式存储时叫做编码,读取一个文件,将二进制转换成字符显示的过程叫做解码
- 编码与解码需要字符集,如果编解码过程使用的字符集不同则会可能出现乱码问题
- 乱码问题如何解决?首先想办法知道该文件时使用什么字符集编码的,然后使用该字符集解码。
- 文件内容开头输入一个“严”字,判断依次采用不同的字符集保存,然后,用文本编辑软件UltraEdit 中的"十六进制功能",观察该文件的内部编码方式。
- 一位二进制 单位时bit, 8bit = 1byte 1kb = 1024byte 依次类推 mb gb tb pb
- 相同的字符文字使用不同的字符集存储,所占文件大小也不同,比如“中国”两字使用utf-8存储占6字节,使用gbk-2312存储占4字节
- 数据(文件)压缩,使用某种转换规则(高频率的字符用短编码)使得存储所占的空间变小的过程,生成这种转换规则的算法叫做压缩算法
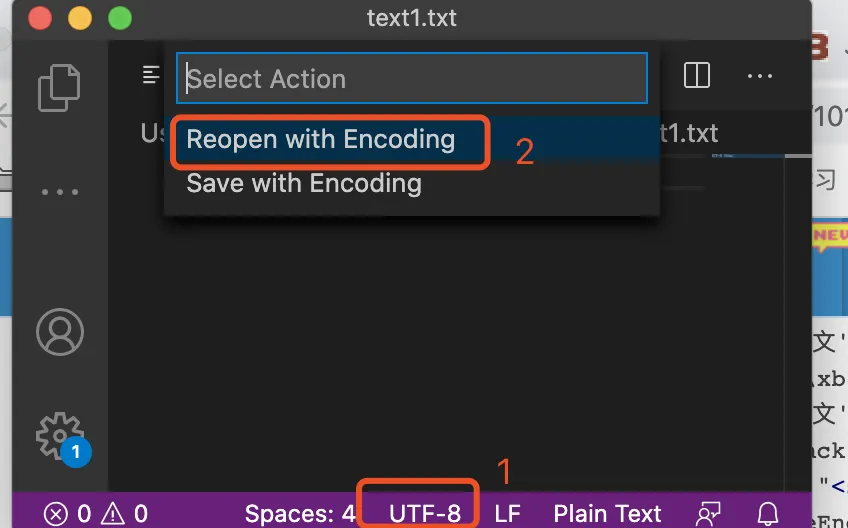
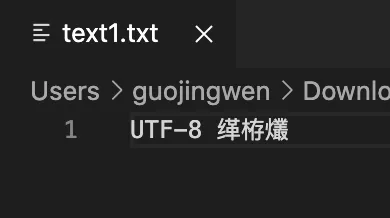
模拟乱码
乱码问题可使用vscode模拟,新建一个文件输入文字 “UTF-8 编码” 保存为utf-8编码,然后点击右下角 utf-8
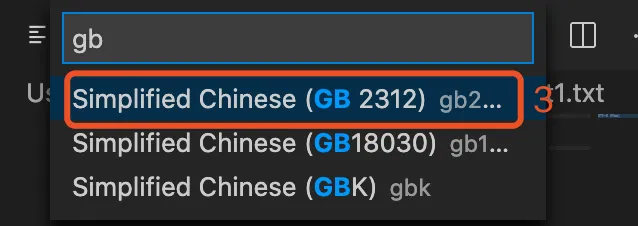
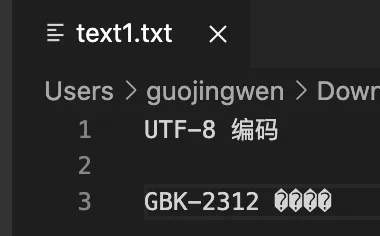
追加文字 “GBK-2312 编码”, 保存后,同样的方式采用utf-8打开
更多参考资料
本文作者:郭敬文
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!