目录
本文主要以V8引擎为例讲解JS引擎的运行机制,包括不限于以下内容:JS语言特性、词法作用域、V8对象和数组、垃圾回收等。
常见面试题
- 简述一下JS语言的特性
- 变量提升这一块可能会有笔试题
- 说一下你对闭包的理解
- 聊一聊JS的垃圾回收机制
- 有遇到过APP闪退?(提示:APP内嵌webview会如果发生内存泄漏会导致APP闪退)
JavaScript语言的特点
JavaScript一门有解释型、动态的、弱类型、支持多范式、事件驱动和异步编程、原型继承、单线程、跨平台等特定的高级编程语言
JavaScript的核心
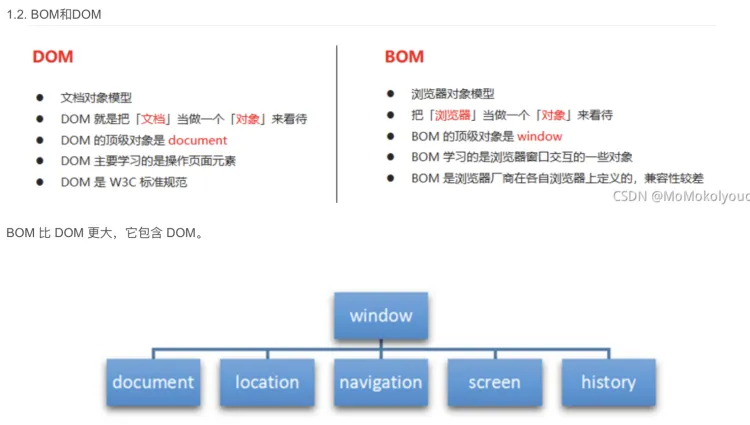
JavaScript三大核心: EcmaScript、DOM和BOM
ECMAScript
- JavaScript是基于ECMA规范的脚本语言
- JavaScript是ECMA规范的一种实现,除此之外还有其他的实现
- 参考资料 《JS历史》
DOM(文档对象模型)
- 描述了处理网页内容的方法和接口,是W3C组织推荐的处理可扩展置标语言的标准编程接口。
- 是一个平台和语言无关的应用程序接口,它可以动态的访问程序和脚本,更新其内容、结构和文档风格
BOM (浏览器对象模型)
- 描述了与浏览器进行交互的方法和接口;
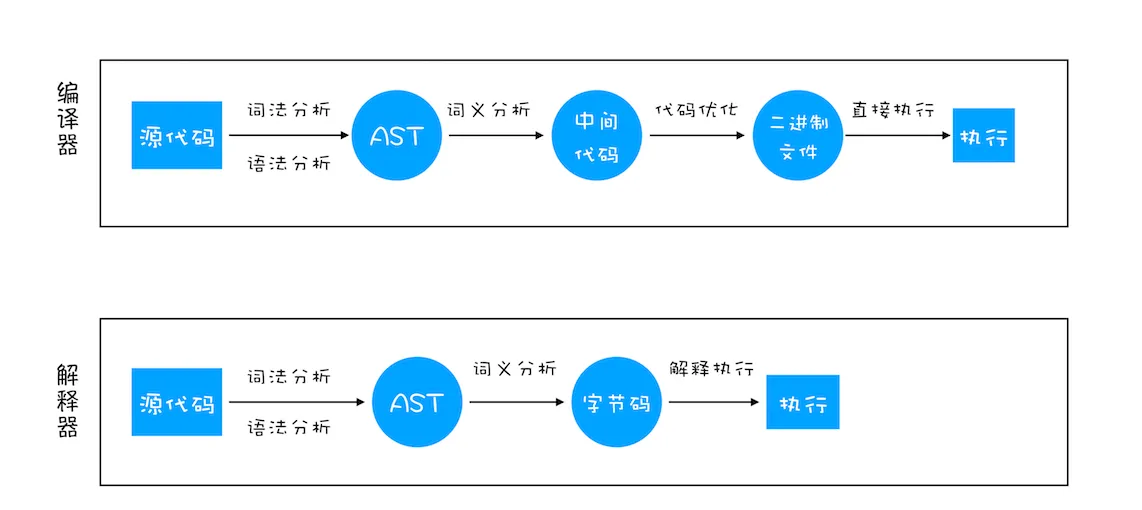
解释器和编译器
- 编译型语言在执行前,需要经过编译器,编译成机器能读懂的二进制文件。
- 解释性语言编写的程序,在每次运行前都需要通过解释器对程序进行动态解释和执行。
- 因为JS应用于web开发的场景,决定了JS必须是解释性语言。
- 解释性语言需要先编译成二进制才能执行,所以JS(解释型语言)运行效率比 Java、C++(编译型语言)执行效率要低
- 解释型语言也有天然优势 就是跨平台、灵活性高
即时编译器(JIT) Just-In-Time Compilation 是一种在运行时将代码编译成机器吗的技术,与传统的静态编译(将源代码在开发阶段编译成机器码)和解释执行(逐行执行源代码)不同,即时编译将代码的编译过程延迟到程序运行时
即时编译技术主要是为了提升解释型语言的执行效率(将热点代码编译为二进制在编译器中执行)
语言特性
- 动态语言(脚本语言)
- 只在被调用是进行解释和编译,在程序的运行过程中逐行解释执行
- 弱类型
- 允许隐式类型转换
- 动态类型
- 运行时检查 (静态类型在编译时检查)
- 单线程
- JS执行与DOM操作互斥,主要因为JS作者当初只是用JS处理脚本,并没要想到过今天JS的生态, 设计成单线程比较简单不用考虑锁和事务等。
- 原型继承
- 通过原型链 实现对象的继承
- 事件驱动和异步编程
- JavaScript常用语处理事件驱动的交互操作,可以通过事件监听器和回调函数来响应用户的操作。异步编程是JS的重要特性,通过回调函数、Promise、async/awiat等机制处理异步操作
- 跨平台
- JS 可以在不同的平台上运行,包括Web浏览器、服务器端(nodejs)桌面应用程序(Election)以及移动应用程序。
- 高级语言
- 高级语言又条件分支循环OOP等,符合人的思维
- 低级语言与硬件和执行细节有关,会操作寄存器、内存,需要开发者理解和熟悉计算机的工作原理
- 支持多范式
- POP
- OOP
- 函数式编程
V8引擎如何执行一段代码?
V8的执行过程既有 解释器(Ignition) 又有 编译器(TurboFan)
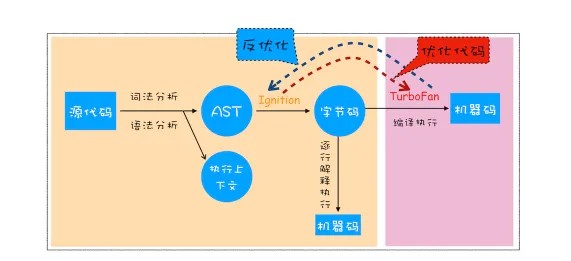
- 生成抽象语法树(AST)和执行上下文
- 生成AST的过程
- 词法分析-->语法分析--> 解析
- 生成字节码
- Ignition会根据AST生成字节码,并解释执行字节码
- 其实V8一开始并没有字节码,而是直接将AST转换成机器码,由于机器码的执行效率非常高效,所以在发布一段时间内运行效果非常好。但随着Chrome在手机上的广泛普及,特别是在512内存的手机上,内存占用问题也就暴露出来了,因为V8要消耗大量内存来存放转换后的机器码。为了解决内存占用问题,V8团队大幅重构了引擎架构,引入字节码,并抛弃了之前的编译器,耗时近4年实现了现在的这套架构。
- 什么是字节码?
- 字节码是一种包含执行程序、由一系列op代码/数据对 组成的文件。 字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。
- 通常情况下它是已经经过编译,但与特定类型的机器码无关。
- 字节码主要是为了实现特定软件运行和运行环境、与硬件环境无关。
- 为什么字节码能解决内存占用问题?
- 执行代码
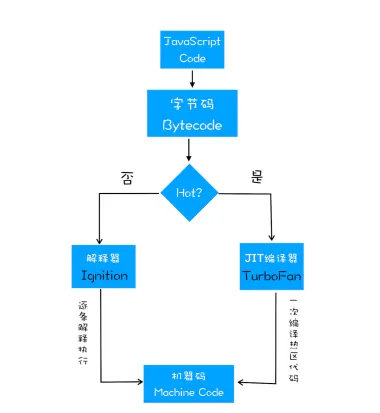
- 通常如果有一段第一次执行的字节码,解释器Ignition会逐条解释执行。在执行字节码的过程中,如果发现有热点代码(一段代码被重复执行多次),那么后台的编译器TurboFan就会把该段热点的字节码编译为高效的机器码,然后再次执行这段被优化的代码时,只需要编译后的机器码就可以了,这样就大大提升了代码的执行效率
- 字节码配合解释器和编译器执行,这种技术叫做即时编译(JIT)。
- JIT用途很广、Java和python虚拟机,苹果的SquirreFish Extreme 和 Mozilla 的 SpiderMonkey 也都是用了该技术

变量提升
先来看一个案例
jsshowName()
console.log(myname)
var myname = 'hello'
function showName() {
console.log('函数 showName 被执行');
}
- 如果JS是顺序执行的,第一行和第二行代码都会报错
- 然而实际上会正常运行
-
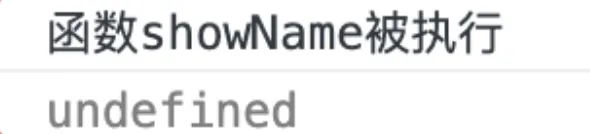
- 要解释这个问题,就要理解什么是变量提升。
声明和赋值
jsvar myname = 'abc';
// 上述代码实际由两部分组成
// var myname // 声明部分
// myname = 'abc' // 赋值部分
// 函数定义的两种方式
// 1. 函数声明语句 函数名和函数体都会提前
function foo() {
console.log('foo');
}
// 2. 函数定义表达式 仅函数名被提前
var bar = function() {
console.log('bar');
}
所谓的变量提升,是指在JavaScript代码执行过程中,JavaScript引擎把变量的声明部分和函数的声明部分提升到代码开头的“行为”。变量被提升后,会给变量设置默认值,这个默认值就是我们熟悉的undefined。
综上:JS的运行可理解为,由为两部分组成 变量提升部分 + 可执行代码部分
JavaScript代码的执行流程
“变量提升” :值变量和函数的声明会在物理层面移动到代码的最前面。但这并不准确。实际上变量和函数声明在代码中的位置是不会改变的,而且是在编译阶段被JavaScript引擎放入内存中

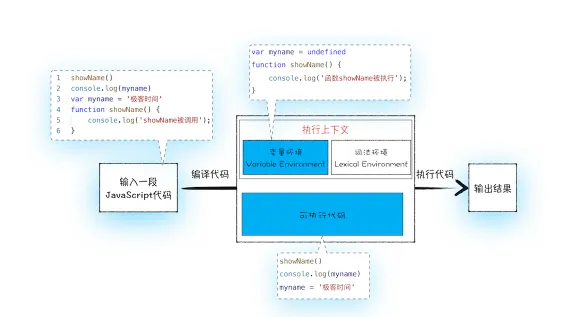
从上图可以看出输入一段代码,经过编译以后,会生成两部分内容:执行上下文和可执行代码。 执行上下文是JavaScript执行一段代码时的运行环境, 比如调用一个函数,就会进入这个函数的执行上下文,确定该函数在执行期间用到的诸如this、变量、对象以及函数等(在执行上下文中会存在一个变量环境的对象)。
同名变量和函数如何处理?
jsxshowName() // 1
var showName = function() {
console.log(2)
}
function showName() {
console.log(1)
}
// showName() // 2
关于同名变量和函数的两点处理原则
- 如果是同名的函数,JavaScript编译阶段会选择最后声明的那个,
- 如果变量和函数同名,那么在编译阶段,变量的声明会被忽略
所以即使 上面两个语句调换顺序,输出依旧不变
Hoisting是否为设计失误?
变量提升带来的问题
javascript// 1 全局变量污染,var和function声明的变量会挂载在window下面
var a = 1;
console.log(window.a) // 1
// 2. var 和function可以重复声明,如果只是单纯重复声明不会改变变量的值
var b = 123;
var b;
console.log(b) // 123
// 3.预期之外的变量 输出不是0到5,而是6个6
for(var i=0; i<6; i++){
setTimeout(() => console.log(i));
};
// 此外 i会泄漏为全局变量
console.log(window.i) // 6
ES6后 不用var,所以可否理解Hoisting为“权宜之计/设计失误”呢?
- 你也可以理解为设计失误,因为设计之初的目的就是想让网页动起来,JavaScript创造者Brendan Eich并没有打算把语言设计太复杂。
- 所以只引入了函数级作用域和全局作用域,一些块级作用域都被华丽地忽略掉了。
- 没有块级作用域,这样设计语言的复杂性就大大降低了,但是这也埋下了混乱的种子。
- 随着JavaScript的流行,人们发现问题越来越多,中间的历史就展开了,最终推出了es6,在语言层面做了非常大的调整,但是为了保持想下兼容,就必须新的规则和旧的规则都同时支持,这样也导致了语言层面不必要的复杂性。
- 虽然JavaScript语言本身问题很多,但是它已经是整个开发生态中的不可或缺的一环了,因此,不要因为它的问题多就不想去学它,我认为判断要学不学习一门语言要看所能产生的价值,JavaScript就这样一门存在很多缺陷却是非常有价值的语言。
编译只是生成字节码吗?
- 先是生成字节码,然后解释器可以和直接执行字节码,输出结果。
- 但是通常JavaScript还有个编译器,会把那些频繁执行的字节码编译为二进制,这样那些经常被运行的函数,就可以快速执行了,通常把这种解释器和编译器混合使用的技术叫做JIT
为什么不建议在块级作用域中定义函数
javascript// ES规定函数不能在块级作用域中声明
function foo(){
console.log(g); // 不是funtion 而是 undefined
if(true){
function g(){ return true; }
}
}
// 根据规范上述代码应该要报错
// 但是大多数浏览器并没有准从这个规定
// ES6 明确支持块级作用域,在块级作用域声明的函数和let声明的变量行为类似
// 规范是理想的,但要照顾实现,如果严格按照let的行为会影响老的代码
// 所以大多数浏览器是按照下面的方式实现
function foo(){
console.log(g); // undefined
if(true){
var g = function (){ return true; }
}
}
// 综上不建议在块级作用域定义函数,简单才是最好的
// 严格模式下函数声明语句要遵从块级作用域规范
// - 块级作用域必须要用函数包裹
// - 不再存在变量提升
"use strict";
if(true) {
function a() {console.log(123)}
};
为什么JavaScript 会存在变量提升这个特性,而其他语言似乎都没有这个特性呢? 要解释清楚这个问题,就要了解作用域
作用域
什么是作用域
- 作用域是指函数中定义变量的区域,该位置决定了变量的生命周期,通俗的理解,作用域就是变量与函数的可访问范围,即作用域控制着变量和函数的可见性和生命周期。
- 在ES6之前是不支持块级作用域的,JavaScript作者在设计这门语言的时候并没有想到JS会火起来,只是按照最简单的方案来设计,这也导致了变量提升。
- 变量提升带来的问题
- 变量在不易察觉的情况下被覆盖掉
- 本应该销毁的变量没有被销毁
- 意料之外的全局变量
javascript// 1. 变量在不易察觉的情况下被覆盖掉
var myName = '张三';
function foo() {
console.log(myName)// 输出 undefined
if(0) {
var myName = '李四'
}
}
foo();
// 2. 本应该销毁的变量没有销毁
function foo(){
for (var i = 0; i < 7; i++) {
}
console.log(i);
}
foo()
为了解决上述问题,ES6引入了块级作用域 let和const
JS如何支持块级作用域的
首先了解一个概念,执行上下文:当执行到一个函数的时候,就会进行准备工作
接着看一个示例代码
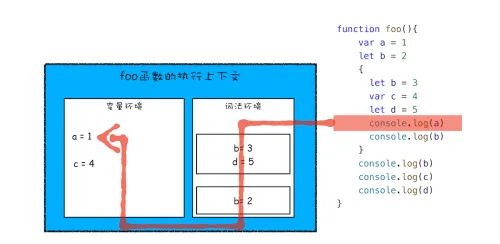
javascriptfunction foo(){
var a = 1
let b = 2
{
let b = 3
var c = 4
let d = 5
console.log(a)
console.log(b)
}
console.log(b)
console.log(c)
console.log(d)
}
foo()
- 第一步创建执行上下文
- 第二步 继续执行代码
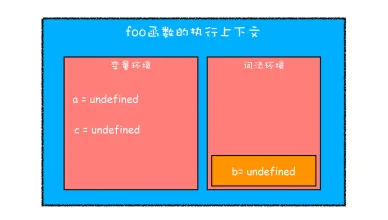
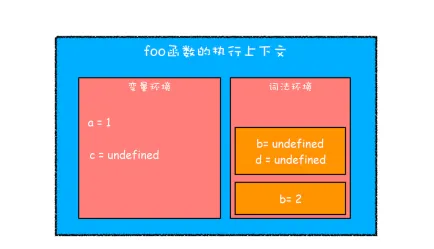
- 在词法环境内部维护了一个小型栈结构,栈底是函数最外层的变量,进入一个作用域块后,就会把该作用域块内部的变量压到栈顶 ;当作用域执行完成以后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构 。(这里所讲的变量是指通过let或const声明的变量)
- 当执行到作用域块中的
console.log(a)这行代码时,就需要在词法环境和变量环境中查找变量a的值了,具体查找方式是,沿着词法环境的栈顶向下查询,如果词法环境中的某个块中找到了,就直接返回给JavaScript引擎,没有找到,就继续在变量环境中查找。
词法作用域
词法作用域就是指作用域是由函数声明的位置来决定的,所以词法作用是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。
JavaScript 采用的是词法作用域(也叫静态作用域),函数的作用域在函数定义的时候就决定了。而与词法作用域相对的是动态作用域(函数的作用域是在函数调用的时候才决定的)。
javascript// 分别用静态作用域和动态作用域分析下面实例代码
var value = 1;
function foo() {
console.log(value);
}
function bar() {
var value = 2;
foo();
}
bar();
- 假设JavaScript采用静态作用域,让我们分析下执行过程:
- 执行 foo 函数,先从 foo 函数内部查找是否有局部变量 value,如果没有,就根据书写的位置,查找上面一层的代码,也就是 value 等于 1,所以结果会打印 1。
- 假设JavaScript采用动态作用域,让我们分析下执行过程:
- 执行 foo 函数,依然是从 foo 函数内部查找是否有局部变量 value。如果没有,就从调用函数的作用域,也就是 bar 函数内部查找 value 变量,所以结果会打印 2。
- 前面我们已经说了,JavaScript采用的是静态作用域,所以这个例子的结果是 1。
调用栈
调用栈是用来管理函数调用关系的一种数据结构 要理解调用栈,首先要弄明白函数调用和栈结构
- 函数调用: 运行一个函数
- 栈结构: 类比一个一端封闭的管子,后进先出。
什么是调用栈?
- JavaScript引擎正是利用栈的这种结构来管理执行上下文的。
- 通常把这种用来管理执行上下文的栈称为调用栈
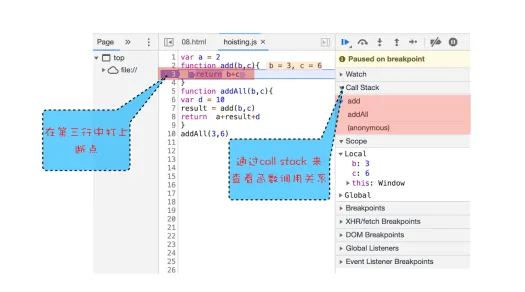
javascriptvar a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)
- 创建全局执行上下文,压入栈底
- 执行全局代码
- 调用addAll函数
- 执行add函数
- add函数执行完从栈顶弹出
- addAll函数执行完成从栈顶弹出
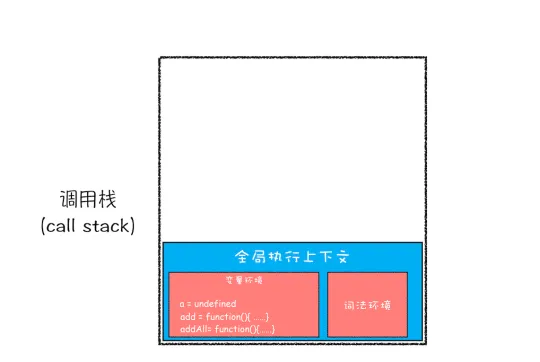
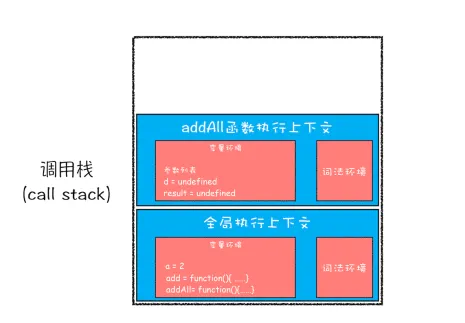
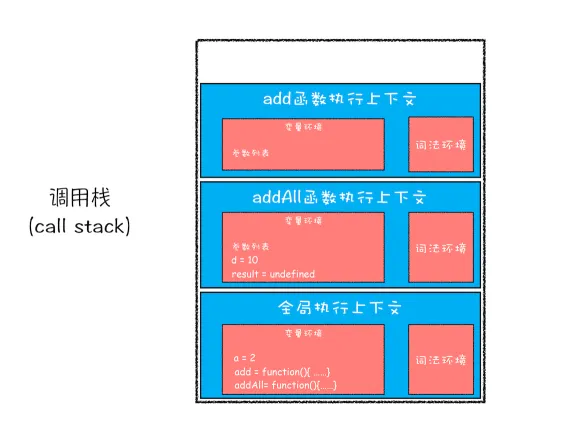
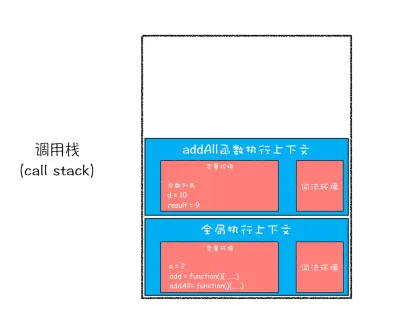
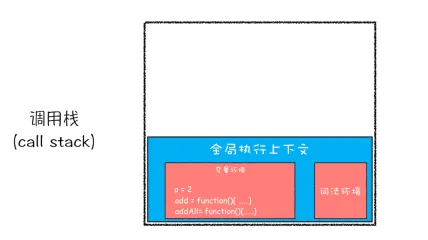
调用栈是JavaScript引擎追踪函数执行的一个机制
使用调用栈
chrome查看调用栈
console.trace 打印调用栈

栈溢出
调用栈是由大小的,当入栈的执行上下文超过一定数目,JavaScript引擎就会报错,我们把这种错误叫做栈溢出。
调用栈有两个指标,最大栈容量和最大调用深度,满足任意一个就会栈溢出。
递归代码就比较容易出现栈溢出
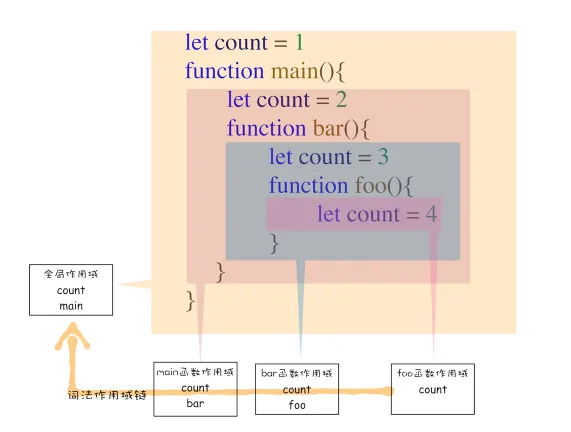
作用域链
- 查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
- 函数的作用域在函数定义的时候就决定了!!!!!!。
- 这是因为函数有一个内部属性 [[scope]],当函数创建的时候,就会保存所有父变量对象到其中,你可以理解 [[scope]] 就是所有父变量对象的层级链,但是注意:[[scope]] 并不代表完整的作用域链!
案例分析1
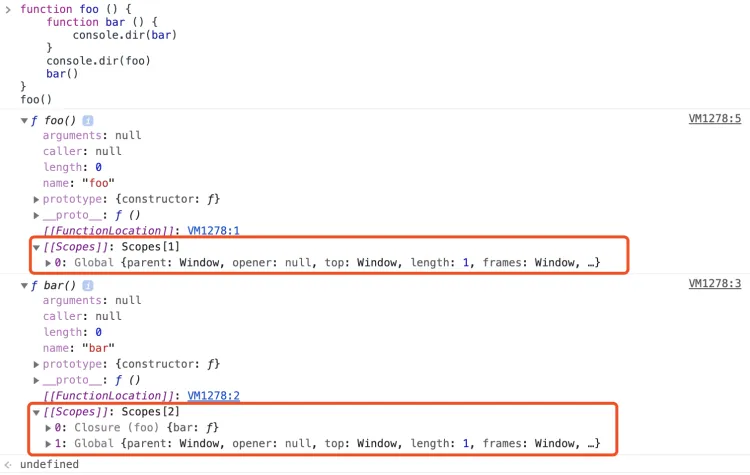
函数激活
当函数激活时,进入函数上下文,创建 VO/AO 后,就会将活动对象添加到作用链的前端。
这时候执行上下文的作用域链,我们命名为 ScopeChain
ScopeChain = [AO].concat([[Scope]]);
至此,作用域链创建完毕。
案例分析2
先来看一段代码
javascriptfunction bar() {
console.log(myName)
}
function foo() {
var myName = " 极客邦 "
bar()
}
var myName = " 极客时间 "
foo()
执行foo函数的调用栈如下图

其实在每个执行上下文的变量环境中,都包含一个外部引用,用来指向外部的执行上下文,我们把这个外部引用称为outer
下图为 块级作用域中是如何查找变量的
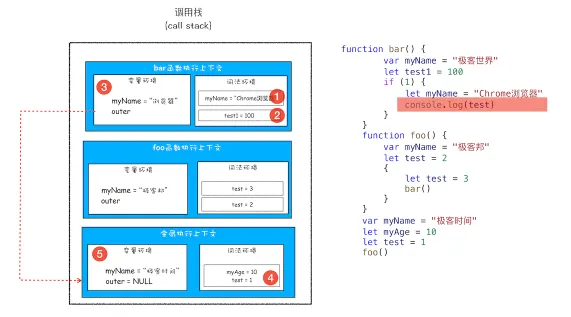
为什么bar函数的外部引用是全局上下文,而不是foo函数的上下文?这个是因为JavaScript词法作用域规定的。
具体执行分析
javascriptvar scope = "global scope";
function checkscope() {
var scope = "local scope";
function f() {
return scope;
}
return f();
}
checkscope();
// 执行全局代码,创建全局执行上下文,全局上下文被压入执行上下文栈
ECStack = [
globalContext
];
// 全局上下文初始化
globalContext = {
VO: [global],
Scope: [globalContext.VO],
this: globalContext.VO
}
// 初始化的同时,checkscope 函数被创建,保存作用域链到函数的内部属性[[scope]]
checkscope.[[scope]] = [
globalContext.VO
];
// 执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 函数执行上下文被压入执行上下文栈
ECStack = [
checkscopeContext,
globalContext
];
/*
checkscope 函数执行上下文初始化:
复制函数 [[scope]] 属性创建作用域链,
用 arguments 创建活动对象,
初始化活动对象,即加入形参、函数声明、变量声明,
将活动对象压入 checkscope 作用域链顶端。
同时 f 函数被创建,保存作用域链到 f 函数的内部属性[[scope]]
*/
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope: undefined,
f: reference to function f() {
}
},
Scope: [AO, globalContext.VO],
this: undefined
}
// 执行 f 函数,创建 f 函数执行上下文,f 函数执行上下文被压入执行上下文栈
ECStack = [
fContext,
checkscopeContext,
globalContext
];
/*f 函数执行上下文初始化, 以下跟第 4 步相同:
复制函数 [[scope]] 属性创建作用域链
用 arguments 创建活动对象初始化活动对象,即加入形参、函数声明、变量声明
将活动对象压入 f 作用域链顶端
*/
fContext = {
AO: {
arguments: {
length: 0
}
},
Scope: [AO, checkscopeContext.AO, globalContext.VO],
this: undefined
}
/*f 函数执行,沿着作用域链查找 scope 值,返回 scope 值
f 函数执行完毕,f 函数上下文从执行上下文栈中弹出
checkscope 函数执行完毕,checkscope 执行上下文从执行上下文栈中弹出
*/
ECStack = [
globalContext
];
js有哪些作用域
全局作用域 函数作用域 块级作用域 eval作用域 动态作用域this
javascript// 1.全局作用域
var a = 123
b = 234
console.log(window.a) // 123
console.log(window.b) // 456
// a是全局变量 不可以被删除
// b是全局对象上的属性 可以删除
function test () {
c = 345
}
test()
console.log(c)
//在函数内部没有用var定义的变量是具有全局作用域的
// 2. 块级作用域
var a = 12
let b = 23
console.log(a, b)
console.log(window.a, window.b) // 12 undefined
// 3.函数作用域(也称作局部作用域)
// 在函数内部声明的变量
// 4.动态作用域 this
eval 只在被直接调用时,this指向才是当前作用域,否则则是全局作用域;
javascriptvar a = 'out'
function f() {
var a = 'in'
eval("console.log(a)"); // in
var i = eval;
i("console.log(a)"); // out 间接调用
(1,eval)('console.log(a)'); // out 间接调用
}
f()
执行上下文栈
当执行到一个函数的时候,就会进行准备工作,这里的“准备工作”,让我们用个更专业一点的说法,就叫做"执行上下文(execution context)"。 当一段代码被执行时,JavaScript引擎会对其进行编译,并创建执行上下文。 一般说来,有这么三种情况
- 当JavaScript执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生命周期内,全局执行上下文只有一份。
- 当调用一个函数的时候,函数体内的代码会被编译,并创建函数的执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁。
- 当使用eval函数的时候,eval的代码也会被编译,并创建执行上下文。
javascriptfunction fun3() {
console.log('fun3')
}
function fun2() {
fun3();
}
function fun1() {
fun2();
}
fun1();
// 伪代码
// fun1()ECStack.push(<fun1> functionContext);
// fun1中竟然调用了fun2,还要创建fun2的执行上下文ECStack.push(<fun2> functionContext);
// 擦,fun2还调用了fun3!ECStack.push(<fun3> functionContext);
// fun3执行完毕ECStack.pop();
// fun2执行完毕ECStack.pop();
// fun1执行完毕ECStack.pop();
// javascript接着执行下面的代码,但是ECStack底层永远有个globalContext
变量对象 对于每个执行上下文,都有三个重要属性:
- 变量对象(Variable object,VO)
- 作用域链(Scope chain)
- this
变量对象是与执行上下文相关的数据作用域,存储了在上下文中定义的变量和函数声明。 全局上下文 全局上下文中的变量对象就是全局对象! 函数上下文
- 在函数上下文中,我们用活动对象(activation object, AO)来表示变量对象。
- 活动对象和变量对象其实是一个东西,只是变量对象是规范上的或者说是引擎实现上的,不可在 JavaScript 环境中访问,只有到当进入一个执行上下文中,这个执行上下文的变量对象才会被激活,所以才叫 activation object 呐,而只有被激活的变量对象,也就是活动对象上的各种属性才能被访问。
- 活动对象是在进入函数上下文时刻被创建的,它通过函数的 arguments 属性初始化。arguments 属性值是 Arguments 对象。
执行过程
- 进入执行上下文
- 代码执行
进入执行上下文 当进入执行上下文时,这时候还没有执行代码,
- 变量对象会包括:
- 函数的所有形参 (如果是函数上下文)
- 由名称和对应值组成的一个变量对象的属性被创建
- 没有实参,属性值设为 undefined
- 函数声明
- 由名称和对应值(函数对象(function-object))组成一个变量对象的属性被创建
- 如果变量对象已经存在相同名称的属性,则完全替换这个属性
- 变量声明
- 由名称和对应值(undefined)组成一个变量对象的属性被创建;
- 如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性
javascriptfunction foo(a) {
var b = 2;
function c() {}
var d = function () {};
b = 3;
}
foo(1);
/* 在进入执行上下文后,这时候的 AO 是
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: undefined,
c: reference to function c() {
},
d: undefined
}*/
/* 代码执行
// 在代码执行阶段,会顺序执行代码,根据代码,修改变量对象的值。还是上面的例子,当代码执行完后,这时候的 AO 是:
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: 3,
c: reference to function c() {
},
d: reference to FunctionExpression "d"
}
*/
关于箭头函数的执行上下文
- 箭头函数在执行时比块级作用域的内容多,比函数执行上下文的内容少,砍掉了很多函数执行上下文中的组件。
- 不过在箭头函数在执行时也是有变量环境的,因为还要支持变量提升!所以变量环境的模块还是砍不掉的
闭包
在JavaScript中,根据词法作用域的规则,内部函数总是可以访问外部函数中声明的变量,当通过调用一个外部函返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。
定义
- MDN: 闭包是指那些能够访问自由变量的函数
- 《红宝书》p178 : 闭包是指有权访问另外一个函数作用域中的变量的函数
- 《JavaScript权威指南》:函数的执行依赖变量的作用域,这个作用域是函数定义时决定的,函数可以通过作用域链相互关联起来,函数体内部的变量都可以保存在函数作用域内。从技术的角度讲,所有的JavaScript函数都是闭包。
从实践角度:以下函数才算是闭包:
- 即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
- 在代码中引用了自由变量
闭包案例
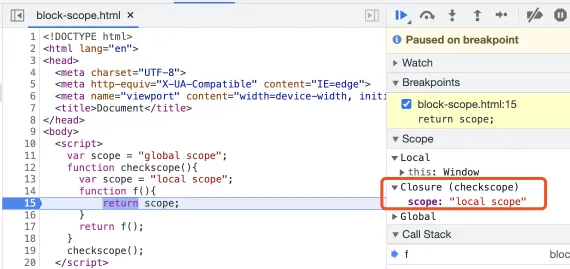
javascriptvar scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();
这里直接给出简要的执行过程:
- 进入全局代码,创建全局执行上下文,全局执行上下文压入执行上下文栈
- 全局执行上下文初始化
- 执行 checkscope 函数,创建 checkscope 函数执行上下文,checkscope 执行上下文被压
执行上下文栈
- checkscope 执行上下文初始化,创建变量对象、作用域链、this等
- checkscope 函数执行完毕,checkscope 执行上下文从执行上下文栈中弹出 执行 f 函数,创建 f 函数执行上下文,
- f 执行上下文被压入执行上下文栈 f 执行上下文初始化,创建变量对象、作用域链、this等
- f 函数执行完毕,f 函数上下文从执行上下文栈中弹出
了解到这个过程,我们应该思考一个问题,那就是:当 f 函数执行的时候,checkscope 函数上下文已经被销毁了啊(即从执行上下文栈中被弹出),怎么还会读取到 checkscope 作用域下的 scope 值呢?我们知道 f 执行上下文维护了一个作用域链: fContext = { Scope: [AO, checkscopeContext.AO, globalContext.VO], }
以下代码片段会产生闭包吗?
javascriptvar scope = "global scope";
function f(){
return scope;
}
function checkscope(){
var scope = "local scope";
return f();
}
checkscope();
答案: 不会,内部函数没有使用外部函数中的变量。
闭包应用
补充一点:模块化 在古老的项目中或者构建工具(rollup)打包后的文件 我们会看到这种写法,
javascript// 1
(function(){
// 模块代码
})()
// 2
(function(){}(
// 模块代码
))
// 3
!function(){
// 模块代码
}()
那么为什么要套个壳呢? var 或 function 声明的变量会成为全局变量,可能会造成命名空间的污染 其本质就是利用函数作用域(也叫局部作用域)将函数体内声明的变量保存在函数作用域上,防止污染全局变量或其他函数。
闭包是怎样回收的
- 如果闭包使用不正确,就会造成内存泄漏。
- 如果引用闭包的函数是个局部变量,在下次JavaScript引擎执行垃圾回收时,判断闭包这块内容如果已经不在被使用了,那么JavaScript引擎的垃圾回收器就会回收这块内存
this指向问题
为什么需要this
- 对象内部的方法访问对象中的属性是一个非常普遍的需求。
- 但是JavaScript的作用域机制似乎并不支持这一点,基于这个需求,JavaScript又搞出来另一套机制this机制。
- 作用域链和this是两套不同的系统,它们之间基本没太多联系
this是和执行上下文绑定的,每个执行上下文中都有一个this
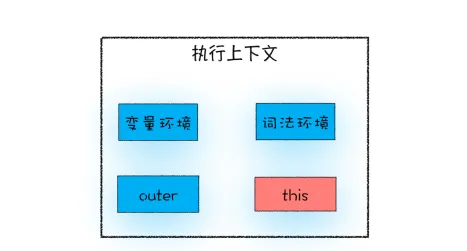 执行上下文主要分三种--- 全局执行上下文、函数执行上下文和eval执行上下文,
所以对应的this也只有这三种---全局执行上下文中的this,函数中的this和eval中的this
执行上下文主要分三种--- 全局执行上下文、函数执行上下文和eval执行上下文,
所以对应的this也只有这三种---全局执行上下文中的this,函数中的this和eval中的this
作用域链的最底端包含了window对象,全局执行上下文中的this也是window对象,这也是this和作用域链的唯一交集
this指向
参考资料: 嗨,你真的懂this吗?
- 默认绑定
- 浏览器中
- 非严格模式下 顶层代码、函数内部 this指向 window 或 self
- 严格模式下 this指向undefined
- nodejs 中
- 顶层代码this指向CJS模块,
- 函数内部this 非严格模式下指向global,严格模式下指向 undefined
- 作为一个DOM事件处理函数 .addEventListener 方式 this指向 MouseEvent
- class中的this
- 在普通方法和构造函数中this指向实例
- 在静态方法中指向类
- 继承后
- 在父类普通方法和构造函数中指向子类实例
- 父类静态方法中指向子类
- 因私有属性不被继承,在父类方法中访问私有属性,拿到的是父类的私有属性
- 浏览器中
- 隐式绑定
- 即通常说说的方法调用,谁调用指向谁
- 这里有个坑, 解构赋值会丢失隐式绑定
- 有些隐式绑定比较坑 如
setTimeout(obj.fn, 0)
- 有些隐式绑定比较坑 如
- getter 与 setter 及 原型链中的this指向当前对象
- 显示绑定
- call apply bind 可以改变this指向
- bind只有第一次绑定有效
javascriptvar obj = {a:1}
function fn(a, ...args) {
console.log(obj, ...args)
this.b = 2
}
var nFn = fn.bind({}, 'a', 'b');
var bFn = nFn.bind(obj, 'c', 'd');
bFn() // {a:1} a b c d
- new绑定 指向新创建的对象
- 优先级 new绑定 > 显示绑定 > 隐式绑定 > 默认绑定
- 箭头函数中的this指向定义它所在环境中的this
javascriptvar name = 'outer'
var obj = {
name: 'inner',
say() {
console.log(this.name);
return () => {
console.log(this.name);
}
}
}
obj.say()(); // inner inner
var say = obj.say;
say()(); // outer outer
var bSay = say.bind({name: 'bind'});
bSay()(); // bind bind
如果箭头函数所在环境的this发生改变,它也跟着改变
javascriptfunction test() {
console.log('test', this);
window.innerTest = () => {
console.log('innerTest', this)
}
}
test.call(1);
innerTest();
// test Number {1}
// innerTest Number {1}
- generator中的this
- g()返回的是遍历器对象,不是this对象
- 想用this的话
g.call(g.prototype);
顶层对象
- 浏览器里面,顶层对象是window,但 Node 和 Web Worker 没有window
- 浏览器和 Web Worker 里面,self也指向顶层对象,但是 Node 没有self
- Node 里面,顶层对象是global,但其他环境都不支持。
- 同一段代码为了能够在各种环境,都能取到顶层对象
- 全局环境中,this会返回顶层对象。但是,Node.js 模块中this返回的是当前模块,ES6 模块中this返回的是undefined。
- 函数里面的this,如果函数不是作为对象的方法运行,而是单纯作为函数运行,this会指向顶层对象。但是,严格模式下,这时this会返回undefined。
- 不管是严格模式,还是普通模式,new Function('return this')(),总是会返回全局对象。但是,如果浏览器用了 CSP(Content Security Policy,内容安全策略),那么eval、new Function这些方法都可能无法使用。
javascript// 综上所述,很难找到一种方法,可以在所有情况下,都取到顶层对象。下面是两种勉强可以使用的方法。
// 方法一
(typeof window !== 'undefined'
? window
: (typeof process === 'object' &&
typeof require === 'function' &&
typeof global === 'object')
? global
: this);
// 方法二
var getGlobal = function () {
if (typeof self !== 'undefined') { return self; }
if (typeof window !== 'undefined') { return window; }
if (typeof global !== 'undefined') { return global; }
throw new Error('unable to locate global object');
};
- globalThis
ES2020 在语言标准的层面,引入globalThis作为顶层对象。也就是说,任何环境下,globalThis都是存在的,都可以从它拿到顶层对象,指向全局环境下的this。 垫片库global-this模拟了这个提案,可以在所有环境拿到globalThis。
super
- 作为函数时,super()只能用在子类的构造函数之中
- super作为对象时,在普通方法中,指向父类的原型对象;在静态方法中,指向父类。
- super.x= 3 修改的是子类实例x
- 注意,使用super的时候,必须显式指定是作为函数、还是作为对象使用
new.target
- 子类继承父类时,new.target会返回子类
- 利用这个特点,可以写出不能独立使用、必须继承后才能使用的类 (java抽象类)
- 不能在函数外部使用
对象是怎样存储的?
虽然 JavaScript 并不需要直接去管理内存,但是在实际项目中为了能避开一些不必要的坑,你还是需要了解数据在内存中的存储方式的。 先来看一段代码
javascript// 在 JavaScript 中,赋值操作和其他语言有很大的不同,
// 原始类型的赋值会完整复制变量值,
// 而引用类型的赋值是复制引用地址。
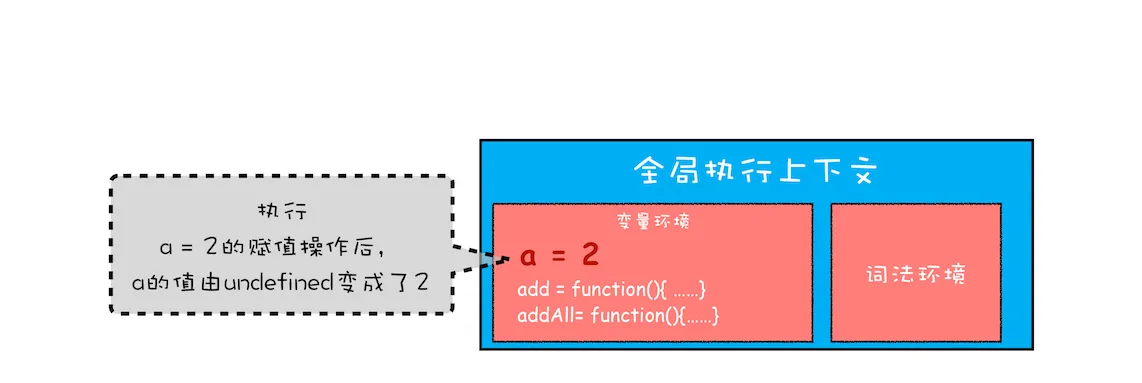
function foo(){
var a = 1
var b = a
a = 2
console.log(a) // 2
console.log(b) // 1
}
foo()
function bar(){
var a = {name:" zhangsan "}
var b = a
a.name = " lisi "
console.log(a) // {name: ' lisi '}
console.log(b) // {name: ' lisi '}
}
bar()
从上述案例中可以看出:如果将一个变量赋值给另一个变量
- 如果这个是基础类型,则是值得copy
- 如果是引用类型,则是变量引用地址的copy,修改了目标对象的属性,原始对象也会跟着影响
js对象分为值类型和引用类型,基础类型的数据都属于值类型,其他的都是引用类型
JavaScript在执行过程中主要有三种类型的内存空间,分别是代码空间、栈空间和堆空间。
- 代码空间是用来存储可执行代码的
- 栈空间 就是调用栈,用来存储执行上下文的。(执行上下文中有 变量环境和词法环境)
- 如果是基本类型,则栈中存储的是值
- 如果是引用类型,则栈中存储的是值的地址,而变量的值实际保存在堆空间里
- 堆空间, 综上分析可以简单理解为引用类型的值存放在堆空间里
为什么要这样设计? 因为引用类型占用的空间可能比较大,JavaScript引擎需要用调用栈来维护程序的上下文,如果所有数据都放在栈空间里面,会影响到上下文切换的效率,进而影响到整个程序的执行效率
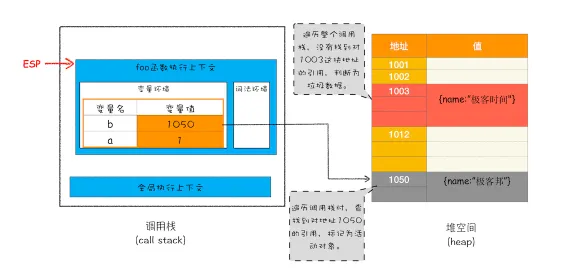
闭包案例分析
javascriptfunction foo() {
var myName = " 李四 "
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName(" 张三 ")
bar.getName()
console.log(bar.getName())
bar = null;
- 创建一个全局上下文
- 执行foo函数,首先进行编译,创建一个空的执行上下文
- 编译时遇到内部函数setName,堆内部函数做一次快速的词法扫描,发现内部函数引用了外部函数foo函数中的变量myName,由于内部函数引用了外部函数中的变量,引擎判断这是一个闭包,于是在堆空间创建一个“closure(foo)”的对象(这是一个内部对象,JS是无法访问的),用来保存myName变量
- 接着扫描的getName方法,又把test1添加到“closure(foo)”对象中。
- 由于test2并没有被内部函数引用,所以test2依然保存在调用栈中
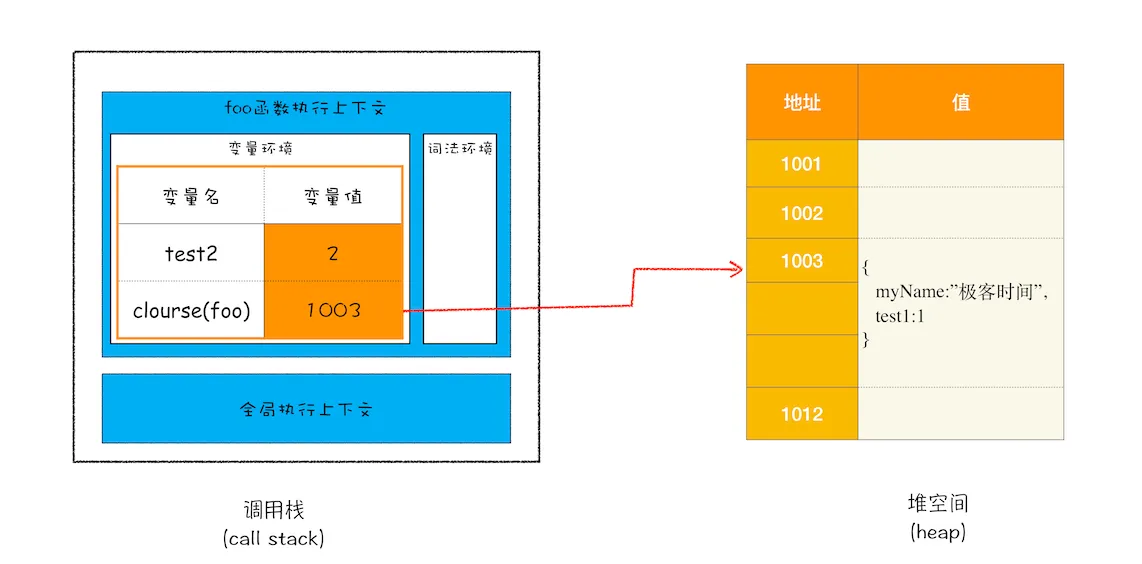
- 第16行代码
var bar = foo()执行完成,调用栈foo函数的执行上下文被销毁,进入全局上下文, innerBar被保存在全局上下文中,由于闭包closure(foo)被innerBar引用,所以不能销毁。 - 执行完成第20行代码
bar=nullinnerBar不在被引用,从而触发 innerBar和 闭包closure(foo)的垃圾回收。
垃圾回收与内存泄漏
- 有些数据被使用之后,可能就不需要了,我们把这些数据称为垃圾数据
- 如果放任这些垃圾数据保存在内存里,那么内存会越用越多
- 所以不同的语言有着不同的垃圾回收策略
- 手动回收的策略 如C/C++,何时分配内存、可是销毁内存都是代码控制的
- 自动回收的策略 如JavaScript、Java、Python等语言,产生的垃圾数据是由垃圾回收器来释放的,不需要手动通过代码来释放。
JS内存占用
JavaScript主要会占用三块内存
- JS在运行前会进行编译,创建全局上下文,和生成可执行代码,全局上下文存储在调用栈中,可执行代码存被存放在一个叫做代码空间的地方
- JS在运行过程中调用函数会创建函数执行上下文,同样是放在栈中;对于基本类型的数值存放在栈中(变量环境中或词法环境的栈中);对于引用类型会存放在堆中;
- 编译是指将字符串转换成字节码,频繁执行的字节码会编译成二进制,字节码和二进制存放的地方叫代码空间。浏览器当前tab关闭,该页面的代码空间会随着渲染进程一起被回收掉。
- 当一个函数执行完推出当前调用栈,当前调用栈即被回收,遇到下一个函数调用就覆盖该区域了
- 销毁操作就是下移ESP指针,ESP是记录当前调用栈的指针
如果堆中的数据要回收,就需要垃圾回收器了
代际假说和分代收集
通常垃圾回收算法有很多中,但是没有哪一种能胜任所有的场景,需要权衡使用场景,根据对象的生存周期的不同而使用不同的算法,已便达到最好的效果。
V8引擎使用的是代际假说和分代收集方案。
代际假说有以下两个特点:
- 大部分对象在内存中存放的时间都很短,很多对象一经分配内存,很快就变得不可访问。
- 不死的对象,会活的更久。
其实这两个特点不仅仅适用于JavaScript,同样适用于大多数语言,如Java、Python等。
- V8会把堆分成新生代和老生代两个区域,
- 新生代存放的是生存时间短的对象,老生代存放的是生存时间久的对象。
- 新生区通常只支持1~8M的容量, 使用副垃圾回收器
- 老生代中支持的容量要大很多,使用主垃圾回收器。
无论什么类型的垃圾回收器,它们都有一套共同的执行流程。
- 标记空间中的活动对象和非活动对象。所谓的活动对象就被变量引用,还在使用的对象;非活动对象就是没有被变量引用,可以进行垃圾回收的对象。
- 回收非活动对象所占据的内存。 所有的标记完成后,统一清理内存中所有被标记可回收的对象
- 内存整理。一般来说,频繁回收内存对象后,内存中就会存在大量内存碎片(不连续的空间)。大量内存碎片产生的影响是,当需要分配较大连续内存的时候,就可能出现不足的情况。(但这一步不是必须的,因为有的垃圾回收器不产生内存碎片)
副垃圾回收器
- 副垃圾回收器主要负责新生区的垃圾回收。而通常情况下,大多数小的对象都会分配到新生区,所以这个区域虽然不大,但垃圾回收还是比较频繁的。
- 新生区采用Scavenge算法来处理。所谓的Scavenge算法,就是把新生区空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示:
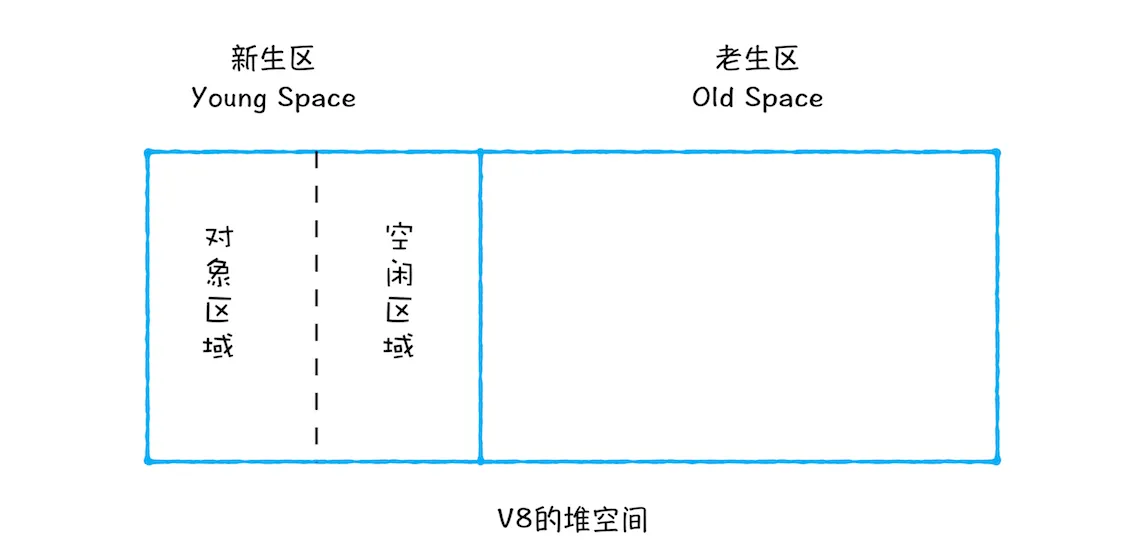
- 新加入的对象都会放到对象区域,当对象区域快被写满时,就需要执行一次垃圾回收清理操作。
- **标记清除 **首先做标记,标记完成进入垃圾清理阶段,副垃圾回收器会把这些存活的对象复制到空闲区域,复制的过程完成对象的有序排列,就相当于清理了内存碎片。
- 角色反转 完成复制后,对象区域于空闲域去进行角色翻转,也就时原先的对象区域变成空闲区域,空闲区域变成对象区域。即完成了垃圾回收还能让新生代中的这两块区域无限重复使用下去。
- 时间成本问题 为了解决角色翻转的复制过程所需要时间成本,新生区的空间一般设置的比较小。
- 可用空间越来越小的问题 也正因为新生区的空间不大,所以很容易塞满整个区域,V8引擎采用 对象晋升策略 ,也就是经过两次垃圾回收依然还存活的对象会被移动到老生区中。
主垃圾回收器
主垃圾回收器负责老生区中的垃圾回收。
- 除了新生区中晋升的对象,一些大的对象会被直接分配到老生区中。
- 因此老生区的特点,一个是对象占用空间大,一个是对象存活时间长。
- 若老生区也采用Scavenge算法进行垃圾回收,复制这些大的对象会花费比较多的时间,从而导致回收执行效率不高,同时还会浪费一半的空间。
- 因为主垃圾回收器是采用 标记-清除(Mark-Sweep) 的算法进行垃圾回收的
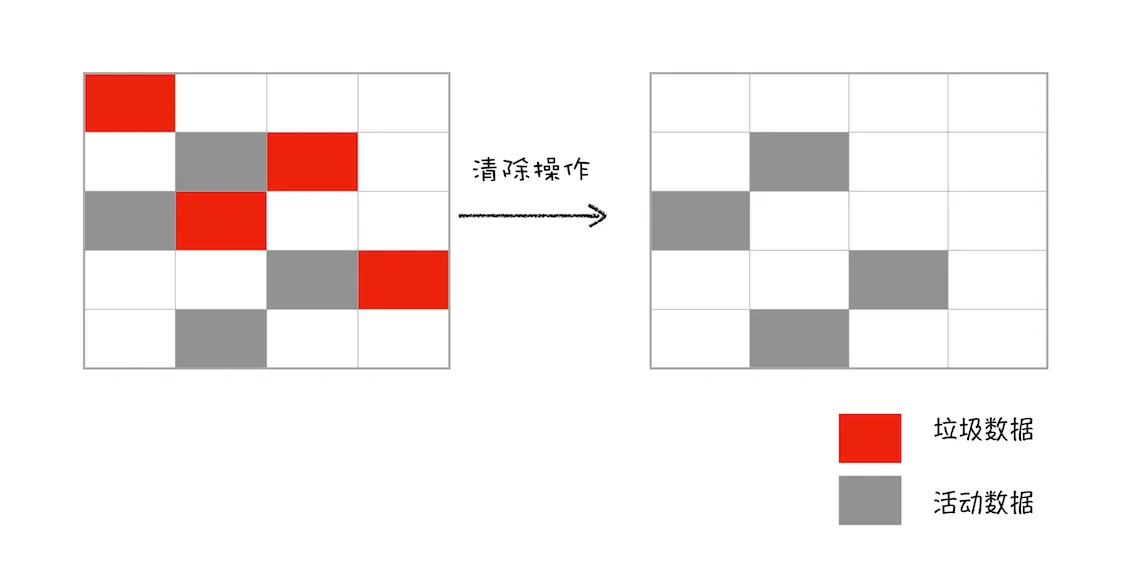
标记-清除算法是如何工作的
- 首先是标记过程阶段。从一组跟元素开始,递归便利这组元素,在这个遍历过程中,能达到的元素为活动对象,没有达到的元素可以判断为垃圾数据。
javascriptfunction foo(){
var a = 1
var b = {name:" 极客邦 "}
function showName(){
var c = " 极客时间 "
var d = {name:" 极客时间 "}
}
showName()
}
foo()
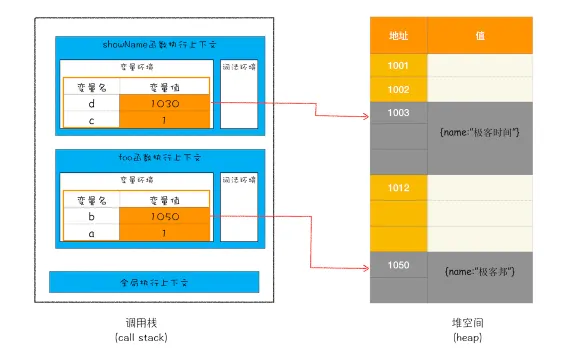
- 接下来就是垃圾的清除过程。与副垃圾回收器的清除相比区别是不对活动对象排序整理
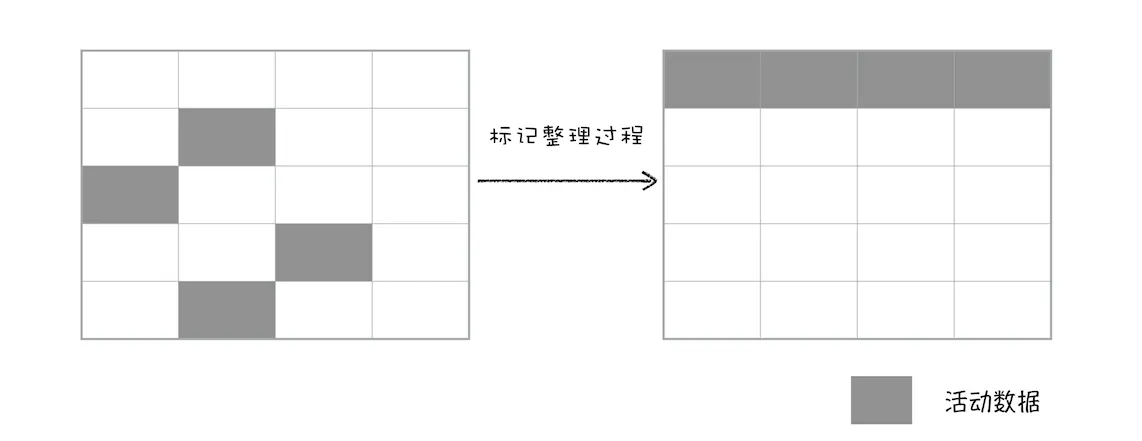
 不过堆一块内存多次执行标记-清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生另外一种算法---标记-整理。
标记过程仍然与标记-清楚算法一致, 但后续不走不是直接对可回收对象进行整理,而是让所有存活对象都像一端移动,然后直接清理掉边界以外的内存。
不过堆一块内存多次执行标记-清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生另外一种算法---标记-整理。
标记过程仍然与标记-清楚算法一致, 但后续不走不是直接对可回收对象进行整理,而是让所有存活对象都像一端移动,然后直接清理掉边界以外的内存。
 全停顿
全停顿
- JavaScript是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的JavaScript脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿
- V8引擎新生代空间较小,所以全停顿影响不大,但老生代就不一样了,比如堆中有100M数据,执行标记-整理算法要200ms,如果有动画则在这200ms内史无法执行的,这就造成页面卡顿。
- 增量标记算法 为了降低老生代的垃圾回收而造成的卡顿,V8将标记过程分为一个个的子标记过程,同时让垃圾回收标记和JavaScript应用逻辑交替进行,直到标记阶段完成
- 使用增量标记算法,将垃圾回收拆分为很多小的任务,然后穿插执行其他的JavaScript任务中间执行,这样当执行上述动画效果是,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
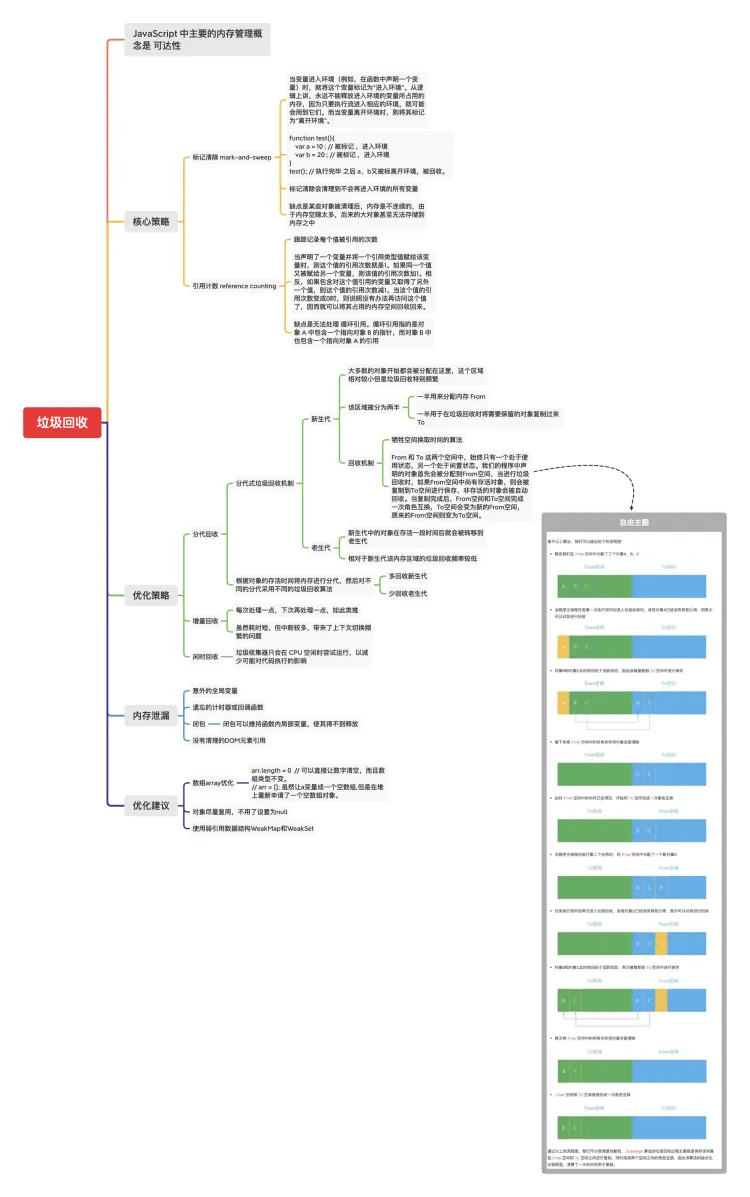
内存泄漏
1、内存泄漏memory leak : 是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
2、内存溢出out of memory : 指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即所谓的内存溢出。
占用的内存没有及时释放,内存泄露积累多了就容易导致内存溢出
如何判断内存泄漏
- 一般是感官上的长时间运行页面卡顿,猜想可能会有内存泄漏。内存泄漏会导致浏览器运行变慢
- 通过chrome Performance来观察。如果多次垃圾回收后,整体趋势是向上,就有可能存在内存泄漏的可能!
检测内存泄漏案例

内存泄漏的影响案例
- 内存泄漏导致浏览器进程崩溃
- 在app内嵌webview 可能导致应用闪退(比如微信)
小程序内存泄漏排查
常见的内存泄露
javascript// 1) 占用的内存没有及时释放
// 内存溢出
var obj = {}
for (var i = 0; i < 10000; i++) {
obj[i] = new Array(10000000)
console.log('-----')
}
// 内存泄露
// 1)意外的全局变量
function fn() {
a = new Array(10000000)
console.log(a)
}
fn()
// 2)没有及时清理的计时器或回调函数
var intervalId = setInterval(function () { //启动循环定时器后不清理
console.log('----')
}, 1000)
// clearInterval(intervalId)
// 闭包
function f2 () {
var a = new Array(10000)
var b = function () {
var c = 3
console.log('b', a)
}
return b
}
var C = f2() // a不会被垃圾回收
C() // c被垃圾回收 a,b 不会
C = null // a,b 被垃圾回收
node 内存泄漏分析
js// node-inspector
console.log("Server PID", process.pid);
// sudo node --inspect app.js
while true;do curl "http://localhost:1337/"; done
// top -pid 2322
V8对象与数组
- 常规属性 (properties) 和排序属性 (element)
- 对象内属性 (in-object properties)
- 快属性和慢属性
- 快数组(FastElements)慢数组(SlowElements)
常规属性&排序属性&排序属性
JavaScript 对象像一个字典是由一组组属性和值组成的,所以最简单的方式是使用一个字典来保存属性和值,但是由于字典是非线性结构,所以如果使用字典,读取效率会大大降低。
V8 为了提升存储和查找效率,V8 在对象中添加了两个隐藏属性,排序属性和常规属性,element 属性 指向了 elements 对象,在 elements 对象中,会按照顺序存放排序属性。properties 属性则指向了properties 对象,在 properties 对象中,会按照创建时的顺序保存常规属性。
- 常规属性 (properties) 和排序属性 (element)
javascript/*
* 1.数字属性被最先打印出来了,并且是按照数字大小的顺序打印的
* 2.设置的字符串属性依然是按照之前的设置顺序打印的
* 原因:ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列
*/
function Foo() {
this[100] = 'test-100'
this[1] = 'test-1'
this["B"] = 'bar-B'
this[50] = 'test-50'
this[9] = 'test-9'
this[8] = 'test-8'
this[3] = 'test-3'
this[5] = 'test-5'
this["A"] = 'bar-A'
this["C"] = 'bar-C'
}
var bar = new Foo()
for (key in bar) {
console.log(`index:${key} value:${bar[key]}`)
}
console.log(bar);
在对象中的数字属性称为排序属性,在 V8 中被称为 elements(elements 对象中,会按照顺序存放排序属性),字符串属性就被称为常规属性,在 V8 中被称为 properties(按照创建时的顺序保存了常规属性)。bar 对象恰好包含了这两个隐藏属性。

如上在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别 保存排序属性和常规属性。分解成这两种线性数据结构之后,如果执行索引操作,那么 V8 会先从elements 属性中按照顺序读取所有的元素,然后再在 properties 属性中读取所有的元素,这样就完成一 次索引操作。
- 我们来验证打印一下
当我们在浏览器里打印出来以后,并没有发现 properties原因是bar.B这个语句来查找 B 的属性值,那么在 V8 会先查找出 properties 属性所指向的对象 properties,然后再在 properties 对象中查找B 属性,这种方式在查找过程中增加了一步操作,因此会影响到元素的查找效率。 所以V8 采取了一个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到对象本身,我们把这称为对象内属性 (in-object properties)。对象在内存中的展现形式你可以参看下图:
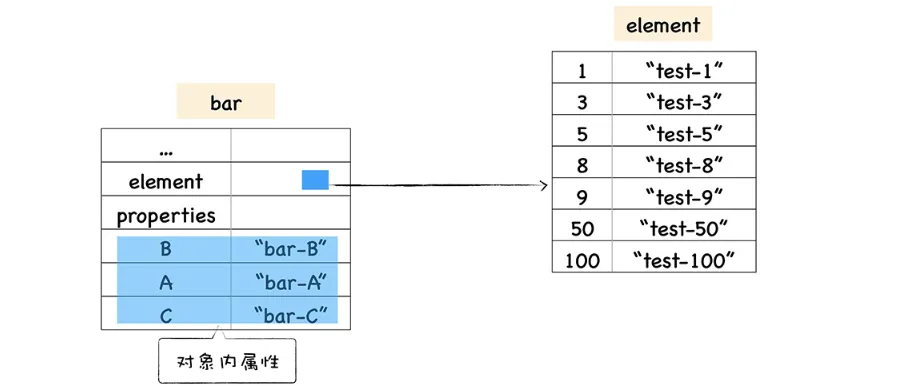
不过对象内属性的数量是固定的,默认是 10 个,如果添加的属性超出了对象分配的空间,则它们将被保存在常规属性存储中。虽然属性存储多了一层间接层,但可以自由地扩容。 保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除大量的属性时,则执行效率会非常低,这主要因为会产生大量时间和内存开销。
因此,如果一个对象的属性过多时,V8 就会采取另外一种存储策略,那就是“慢属性”策略,但慢属性的 对象内部会有独立的非线性数据结构 (词典) 作为属性存储容器。所有的属性元信息不再是线性存储的,而是直接保存在属性字典中。
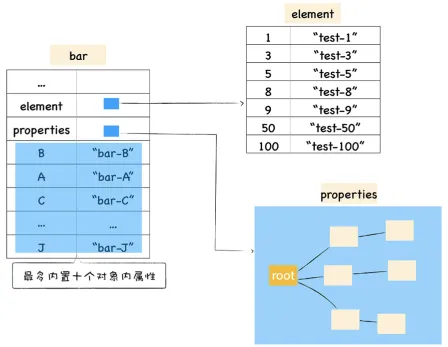
通过引入这两个属性,加速了 V8 查找属性的速度,为了更加进一步提升查找效率,V8 还实现了内置内属性的策略,当常规属性少于一定数量时,V8 就会将这些常规属性直接写进对象中,这样又节省了一个中间步骤。 最后如果对象中的属性过多时,或者存在反复添加或者删除属性的操作,那么 V8 就会将线性的存储模式降级为非线性的字典存储模式,这样虽然降低了查找速度,但是却提升了修改对象的属性的速度。 以上资料参考自 https://v8.dev/blog/fast-properties
快数组与慢数组
数组 它的这种特定的存储结构(连续存储空间存储同一类型数据)决定了,优点就是可以随机访问 (可以通过下标随机访问数组中的任意位置上的数据),缺点(对数据的删除和插入不是很友好)。
javascript// ---当栈用---
let stack = [1, 2, 3] // 进栈
stack.push(4)
// 出栈
stcak.pop()
//---当队列用---
let queue = [1, 2, 3] // 进队
queue.push(4)
// 出队
queue.shift()
/*
* 综上所述:有如果下的结论
* 查找: 根据下标随机访问的时间复杂度为 O(1); *插入或删除: 时间复杂度为 O(n);
*/
JavaScript的数组过于灵活。
- 数组
- 数组为什么可以保存不同类型?
- 数组是如何存储的?
- 数组的动态扩容与减容?
- 先来看看V8的源码
cpp//JSArray 是继承自 JSObject 的,所以在 JavaScript 中,数组可以是一个特殊的对象,
// 内部也是以 key-value 形式存储数据,所以 JavaScript 中的数组可以存放不同类型的值。
// The JSArray describes JavaScript Arrays
// Such an array can be in one of two modes:
// - fast, backing storage is a FixedArray and length <= elements.length();
// Please note: push and pop can be used to grow and shrink the array.
// - slow, backing storage is a HashTable with numbers as keys.
class JSArray: public JSObject {
public:
// [length]: The length property.
DECL_ACCESSORS(length, Object)
// ...
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
};
// src/objects/js-objects.h
static const uint32_t kMaxGap = 1024;
// src/objects/dictionary.h
// JSObjects prefer dictionary elements if the dictionary saves this much
// memory compared to a fast elements backing store.
static const uint32_t kPreferFastElementsSizeFactor = 3;
// src/objects/js-objects-inl.h
// If the fast-case backing storage takes up much more memory than a dictionary
// backing storage would, the object should have slow elements.
// static
static inline bool ShouldConvertToSlowElements(uint32_t used_elements,
uint32_t new_capacity) { NumberDictionary::kPreferFastElementsSizeFactor *
NumberDictionary::ComputeCapacity(used_elements) * NumberDictionary::kEntrySize;
// 快数组新容量是扩容后的容量3倍之多时,也会被转成慢数组
return size_threshold <= new_capacity; }
static inline bool ShouldConvertToSlowElements(JSObject object, uint32_t capacity,
uint32_t index,
uint32_t* new_capacity) { STATIC_ASSERT(JSObject::kMaxUncheckedOldFastElementsLength <=
JSObject::kMaxUncheckedFastElementsLength);
if (index < capacity) {
*new_capacity = capacity;
return false;
}
// 当加入的索引值(例如例3中的2000)比当前容量capacity 大于等于 1024时,
// 返回true,转为慢数组
if (index - capacity >= JSObject::kMaxGap) return true; *new_capacity = JSObject::NewElementsCapacity(index + 1); DCHECK_LT(index, *new_capacity);
// TODO(ulan): Check if it works with young large objects.
if (*new_capacity <= JSObject::kMaxUncheckedOldFastElementsLength || (*new_capacity <= JSObject::kMaxUncheckedFastElementsLength &&
ObjectInYoungGeneration(object))) {
return false;
}
return ShouldConvertToSlowElements(object.GetFastElementsUsage(),
}
uint32_t size_threshold =
*new_capacity);
所以,当处于以下情况时,快数组会被转变为慢数组:
- 当加入的索引值 index 比当前容量 capacity 差值大于等于 1024 时(index - capacity >= 1024)
- 快数组新容量是扩容后的容量 3 倍之多时 例如:向快数组里增加一个大索引同类型值
javascriptvar a = [1, 2, 3]
a[2000] = 10
当往 arr 增加一个 2000 的索引时, arr 被转成慢数组。节省了大量的内存空间(从索引为 2 到索 引为 2000)。
本文作者:郭敬文
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!