目录
背景与介绍
一款产品从开发到上线, 从操作系统再到运行环境,再到应用配置,作为开发+运维之间的协作我们需要关心很多东西。这也是很多互联网公司都不得不面对的问题,特别是各种版本的迭代之后,不同版本环境的兼容,对运维人员都是考验。
Docker之所以发展如此迅速,也是因为它对此给出了一个标准化的解决方案。
Docker的思路
环境配置如此麻烦,换一台机器,就要重来一次,费力费时。很多人想到,能不能从根本上解决问题,软件可以带环境安装?也就是说,安装的时候,把原始环境一模一样地复制过来。开发人员利用 Docker 可以消除协作编码时“在我的机器上可正常工作”的问题。
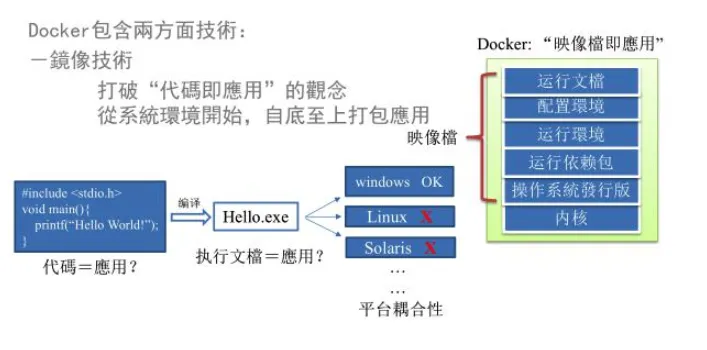
传统开发模式,开发需要清楚的告诉运维部署团队,用的全部配置文件+所有软件环境。不过即便如此,也常常有部署失败的状况。Docker的镜像设计,使得Docker得以打破过去「程序即应用」的观念。通过镜像将作业系统核心除外,运作应用程序所需要的系统环境,有下到上打包,达到应用程序开平台见的无缝接轨运作。
Docker理念
Docker是基于Go语言实现的云开源项目。
Docker的主要目标是“Build,Ship and Run Any App,Anywhere”,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP(可以是一个WEB应用或数据库应用等等)及其运行环境能够做到 “一次封装,到处运行”。
Linux容器技术的出现就解决了这样一个问题,而 Docker 就是在它的基础上发展过来的。将应用运行在 Docker 容器上面,而 Docker 容器在任何操作系统上都是一致的,这就实现了跨平台、跨服务器。只需要一次配置好环境,换到别的机子上就可以一键部署好,大大简化了操作。
总结:Docker是解决了运行环境和配置问题软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术。
对比虚拟机技术
虚拟机的本质是在一种操作系统里面运行另一种操作系统,比如在Windows 系统里面运行Linux 系统。应用程序对此毫无感知,因为虚拟机看上去跟真实系统一模一样,而对于底层系统来说,虚拟机就是一个普通文件,不需要了就删掉,对其他部分毫无影响。这类虚拟机完美的运行了另一套系统,能够使应用程序,操作系统和硬件三者之间的逻辑不变。
但是虚拟机存在以下缺点
- 资源占用多
- 冗余步骤多
- 启动慢
容器虚拟化技术
由于前面虚拟机存在这些缺点,Linux 发展出了另一种虚拟化技术:Linux容器(Linux Containers,缩写为 LXC)。Linux 容器不是模拟一个完整的操作系统,而是对进程进行隔离。有了容器,就可以将软件运行所需的所有资源打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需的库资源和设置。系统因此而变得高效轻量并保证部署在任何环境中的软件都能始终如一地运行。
比较Docker和传统虚拟化方式的不同之处
- 传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;
- 而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
- 每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。

Docker的优势
-
更快速的应用交付和部署
传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间。 -
更便捷的升级和扩缩容
随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成一块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。 -
更简单的系统运维
应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度一致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。 -
更高效的计算资源利用
Docker是内核级虚拟化,其不像传统的虚拟化技术一样需要额外的Hypervisor支持,所以在一台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
Docker基本概念
我画了一张图

Docker的基本组成:
-
镜像(Image):一个只读的模板。镜像可以用来创建
Docker容器,一个镜像可以创建很多容器。 -
容器(Container):独立运行的一个或一组应用。容器是用镜像创建的运行实例。(它可以被启动、开始、停止、删除。每个容器都是相互隔离的、保证安全的平台。可以把容器看做是一个简易版的 Linux 环境(包括root用户权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。)
-
仓库(Repository): 集中存放镜像文件的场所。(仓库分为公开仓库(Public)和私有仓库(Private)两种形式。最大的公开仓库是 Docker Hub,存放了数量庞大的镜像供用户下载。国内的公开仓库包括阿里云 、网易云 等。私有仓库也可像gitlib一样自己构建)
-
数据卷 : 前面介绍
docker容器是隔离的,想修改配置文件、查看日志等先要进入,由于容器是最小运行环境,很多命令可能没有,使用起来不方面,docker容器数据卷就是通过映射的方式,把配置文件、日志、数据与宿主机文件系统映射, 这样查看修改都很方面。 -
dockerfile: 用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本,可以继承组合其他镜像
底层原理
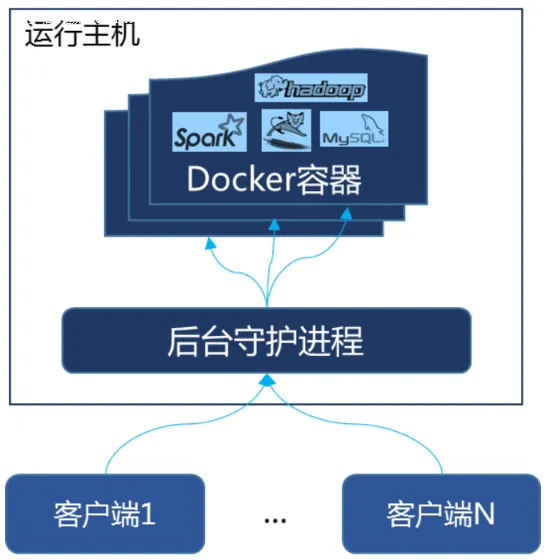
Docker是一个Client-Server结构的系统,Docker守护进程运行在主机上, 然后通过Socket连接从客户端访问,守护进程从客户端接受命令并管理运行在主机上的容器。 容器,是一个运行时环境,就是我们前面说到的集装箱。
环境安装
关于环境安装推荐参考官方文章,对于mac或linux有图形化界面,可以傻瓜式安装;对于linux来说,一些云服务厂商购买ECS实例时可以选择内置docker。熟悉一些linux命令行和翻墙技巧安装docker并不难, 如需机票可以参考我的另一篇文章
- 启动docker
sudo systemctl start docker.service - 设置docker开机自启动
sudo systemctl enable docker.service docker version查看docker版本(验证docker是否安装成功)- 停止docker
sudo systemctl stop docker
配置镜像加速
由于万里长城的存在,你需要修改docker仓库的源(docker hub)为国内源,一些大公司腾讯、阿里、网易都有自己的docker私服。
如阿里的源,需要登陆阿里云后台注册账号,然后才能获取到地址
json{
"registry-mirrors": ["https://{自已的编码}.mirror.aliyuncs.com"]
}
腾讯的源比较简单,这是地址https://mirror.ccs.tencentyun.com
json{
"registry-mirrors": [
"https://mirror.ccs.tencentyun.com"
]
}
通过 vim /etc/docker/daemon.json写入上述配置
docker info 可以检测镜像加速是否生效

HelloWorld
docker run hello-world
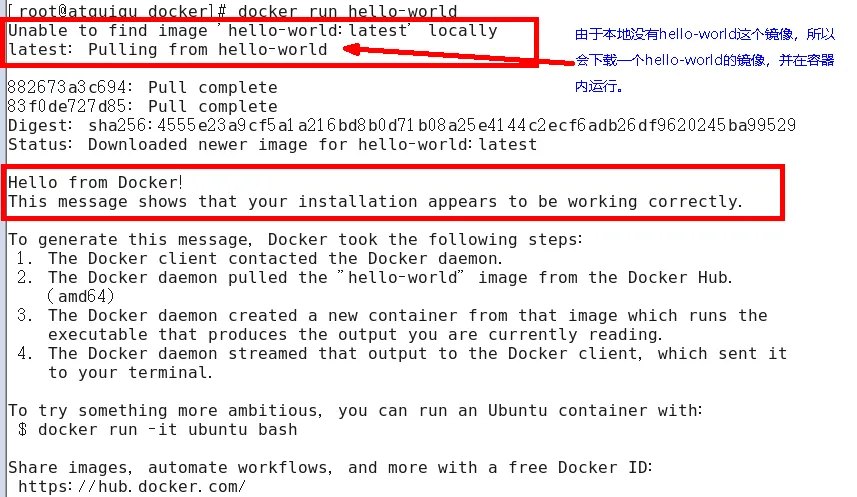
hello-world 是别人已经写好的程序,输入一段内容后就执行结束,容器停止运行
这里补充下 run 干了什么?
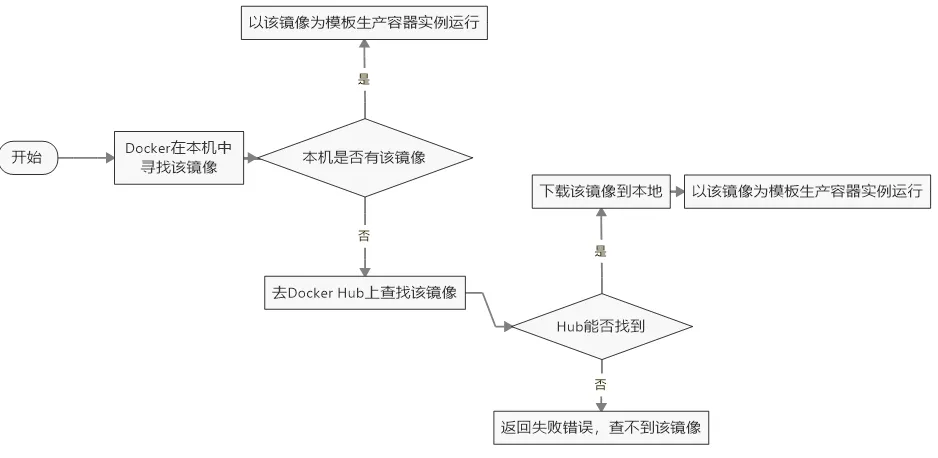
docker常见命令
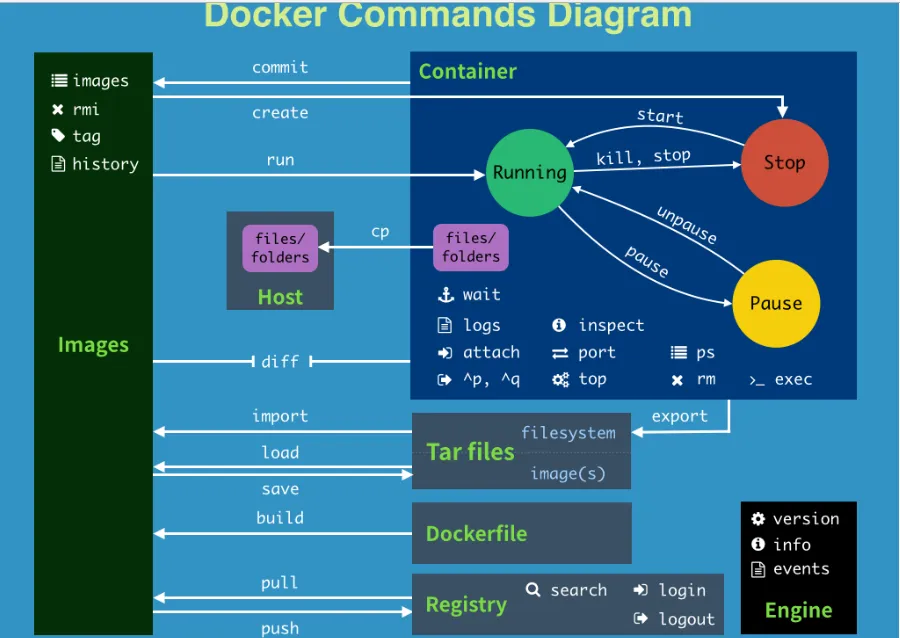
这是网上找的一张图
我做了一个思维导图 详细内容点这里
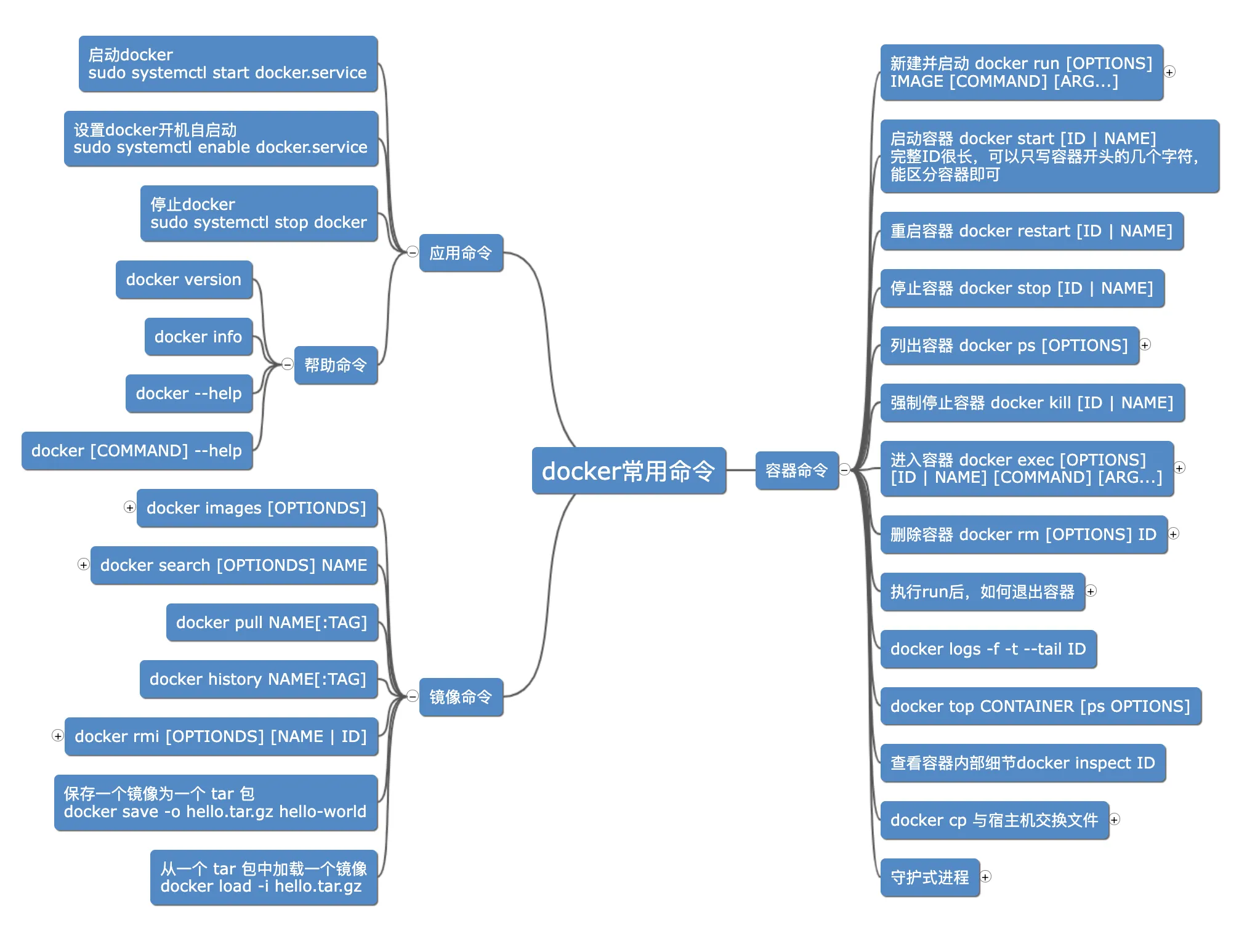
注:思维导图中的命令使用的是简写形式(老版本语法),新老版本语法区别如下

举一些例子

注意
关于docker条件允许还是推荐在linux系统下学习
windows电脑也可以,但有一些注意事项
windows系统shell脚本与linux区别有点多,比较重要的一点是对于变量的引用windows使用${},linux使用$()docker run之后退出容器exit命令在linux系统下会终止容器运行,而windows不会- 后面讲
docker容器卷的时候,windows电脑和mac电脑 无法进入/var/lib/docker/volumes目录
docker镜像
镜像是一种轻量级、可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码、运行时、库、环境变量和配置文件。
UnionFS
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。Union 文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。

docker加载原理
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
bootfs(boot file system)主要包含bootloader和kernel,
bootloader主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。rootfs(root file system) ,在bootfs之上。包含的就是典型Linux系统中的/dev,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
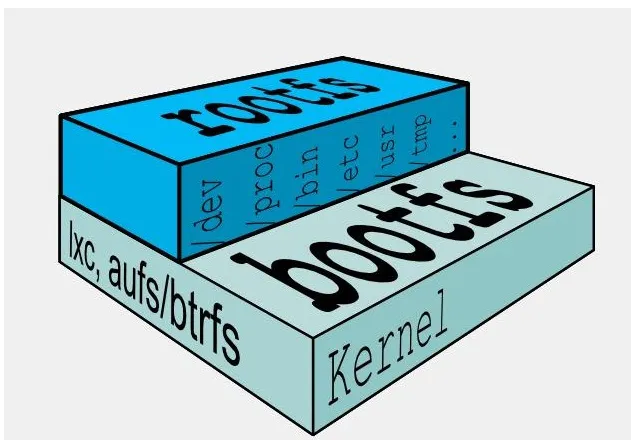
平时我们安装进虚拟机的CentOS都是好几个G,为什么docker这里才200M??
对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host(宿主机)的kernel,自己只需要提供 rootfs 就行了。由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs。
分层的镜像
以docker pull mongo为例,在下载的过程中我们可以看到docker的镜像好像是在一层一层的在下载。
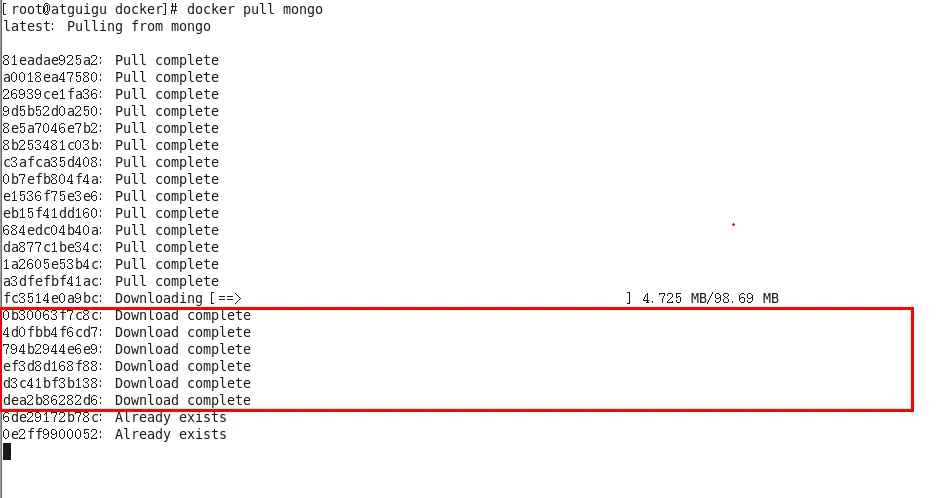
为什么Docker镜像要采用这种分层结构呢?
最大的一个好处就是 - 共享资源。
比如:有多个镜像都从相同的 base 镜像构建而来,那么宿主机只需在磁盘上保存一份base镜像,同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享。
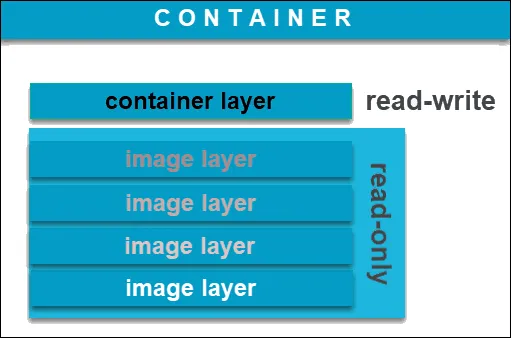
Docker镜像都是只读的。当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作”容器层”,“容器层”之下的都叫“镜像层”。
思考一个问题:
假设你使用imageA启动一个容器containerA, 进入容器 containerA 进行了一堆操作, 这时候使用docker commit生成imageB,把imageB交付给测试,测试imageB使用在生成了containerB,如果这时候发现 imageB有问题, 那么怎样恢复之前的代码或者说找回imageA?
其实docker启动新容器后会在原有的镜像上,新建一个容器,这个容器才是可写的,相关改动改动都保留在这个容器中, commit后会基于这个可写层生成一个新的镜像。
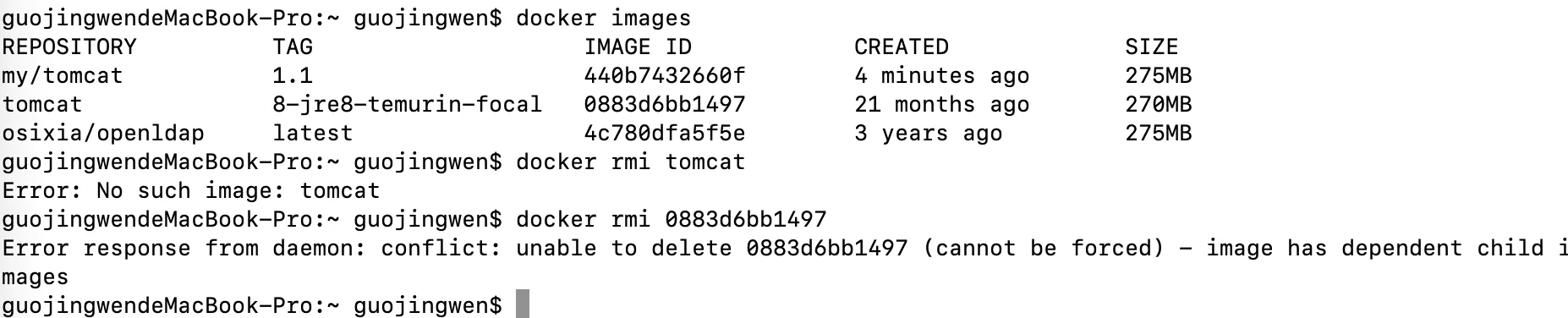
如下图 my/tomcat 就是我基于tomcat: 8-jre8-temurin-focal生成的容器上进行一波操作后,再通过 docker commit生成的新镜像
 如果我想删除老镜像
如果我想删除老镜像tomcat: 8-jre8-temurin-focal 是不可以的。
docker容器数据卷
数据卷是什么
卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性:
卷的设计目的就是数据的持久化,完全独立于容器的生存周期,因此Docker不会在容器删除时删除其挂载的数据卷
关于容器数据卷我的理解有两个作用
- 共享数据。因为
docker容器是隔离的,必须进入容器才能操作容器内的文件,一个文件如配置信息、日志、数据等在容器里改动也不方面(容器是最小运行环境,可用命令少),所以需要将容器内的一些文件与宿主机进行映射。这样操作查看荣喜信息修改等更方便。 - 持续存储。
Docker容器产生的数据,如果不通过docker commit生成新的镜像,使得数据做为镜像的一部分保存下来, 那么当容器删除后,数据自然也就没有了。 为了能保存数据在docker中我们使用卷。 - 容器间传递共享信息
- 这篇文章写一个容器卷继承的案例,有兴趣可以看一下,结论是:容器之间配置信息的传递,数据卷的生命周期一直持续到没有容器使用它为止
- 补充知识点: 数据卷容器 比如
docker run -it --name dc02 --volumes-from dc01 my/centos, 则dc02被称为数据卷容器
网上大佬对容器数据卷的总结:有点类似Redis里面的rdb和aof文件。

特点:
- 数据卷可在容器之间共享或重用数据
- 卷中的更改可以直接生效
- 数据卷中的更改不会包含在镜像的更新中
- 数据卷的生命周期一直持续到没有容器使用它为止
添加数据卷有两种方式
- 命令添加
dockerfile添加
通过命令添加数据卷
docker run -it -v /宿主机绝对路径目录:/容器内目录 镜像名- 注意:
-v可以指定多个映射
- 注意:
- 查看数据卷是否挂载成功
docker inspect 容器ID - 尝试在容器内一波操作,检查容器宿主机目录下面的文件内容与容器内目录下的文件内容是否一致
- 容器停止退出后,主机修改数据后,启动容器,查看容器内数据是否同步
通过Dockerfile添加数据卷
- 根目录下新建
mydocker文件夹并进入 - 可在
Dockerfle中使用VOLUME指令来给镜像添加一个或多个数据卷VOLUME ["/dataVolumeContainer1","/dataVolumeContainer2"]
- 注意这里个路径都是容器路径,没有宿主机路径,这是出于可移植和分享的考虑,因为宿主机目录是依赖于特定宿主机的,并不能够保证在所有的宿主机上都存在这样的特定目录。
- 该方式定义仅当创建容器时没有指定
-v时有效 - 可以通过
docker inspect查询映射的宿主机目录 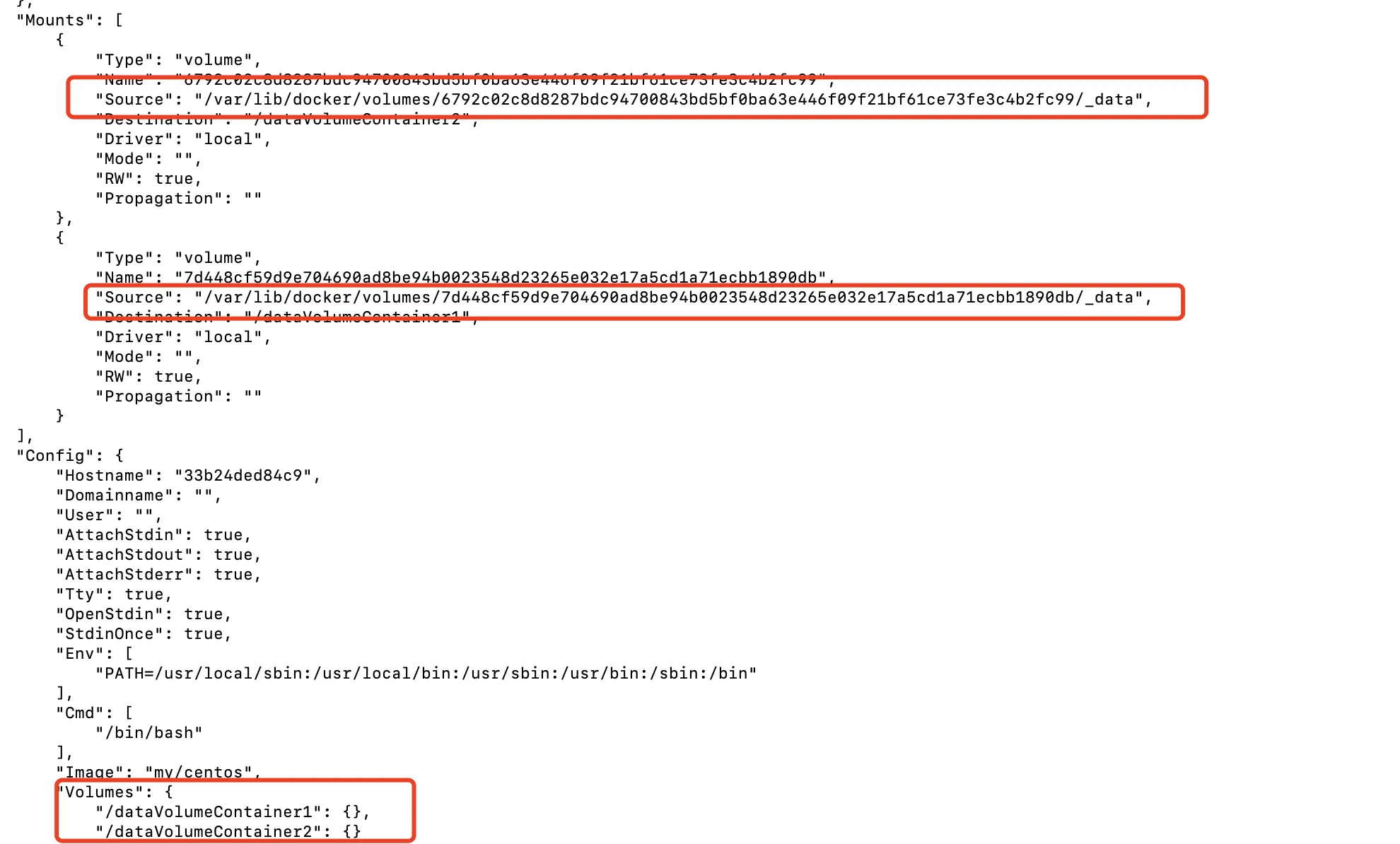
- 注意 如果你是
windows电脑或mac电脑 无法进入/var/lib/docker/volumes目录
- 编写
File,构建镜像docker build [OPTIONS] PATH | URL- 例子
docker build -f myDockerfile -t NAME .
补充知识点: 可以通过:ro(默认是rw)指定宿主机目录或容器目录只读,如下设置容器内只读
docker run -it -v /宿主机绝对路径目录:/容器内目录:ro
docker volume 命令行
可以通过 docker volume ls 查看容器数据卷
如果想找到数据卷在宿主机的位置可以通过 docker volume inspect 数据卷ID 或 docker container inspect 容器ID
docker volume prune 清除数据卷(容器被干掉,数据卷还存留的)。
docker volume 还支持多机器共享数据卷 参考这篇文章
dockerfile
Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本。
构建三步骤 1> 编写dockerile文件 2> docker build 3> docker run
dockerfile简介
先来看一个镜像案例
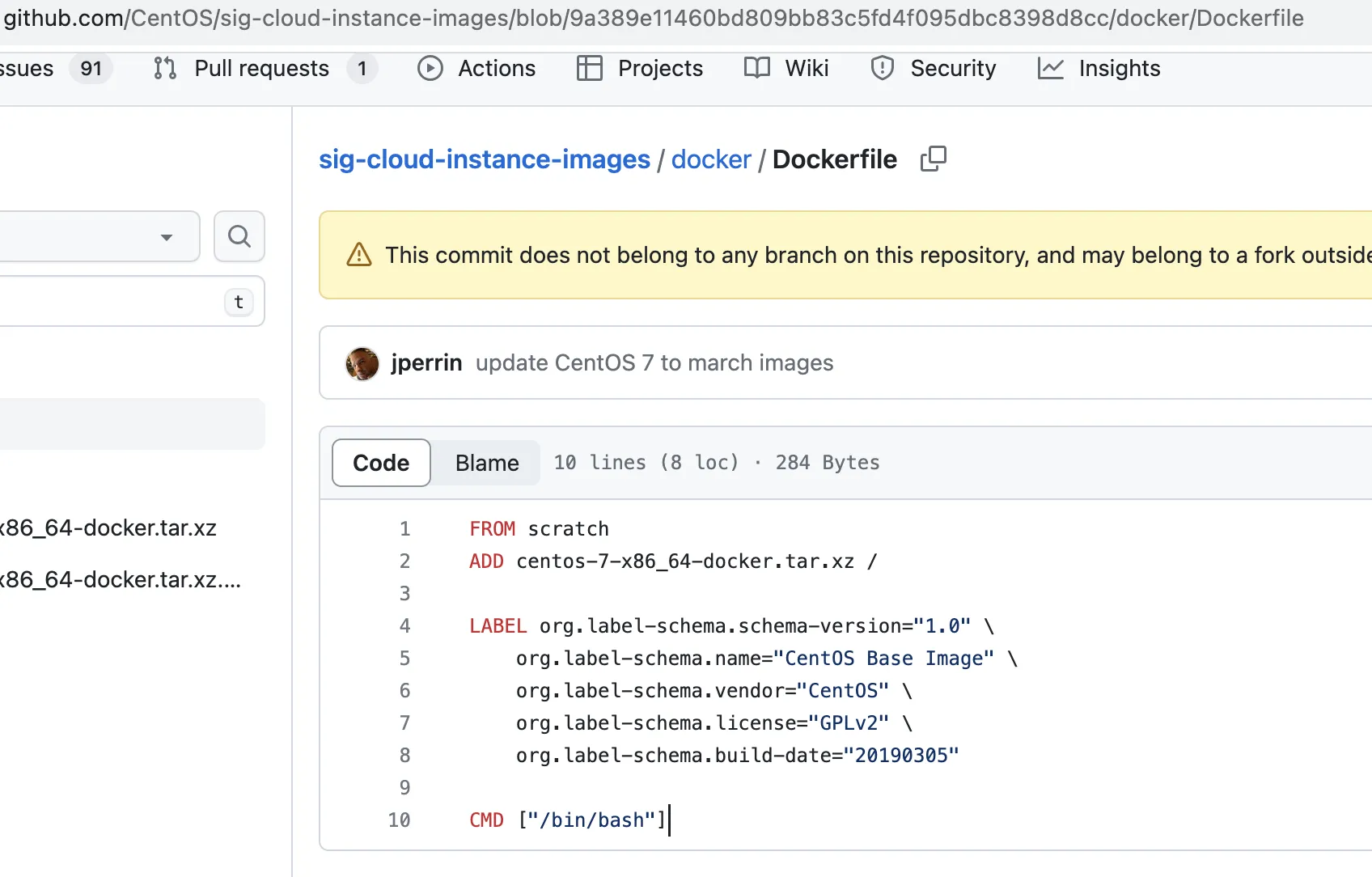 注:
注: FROM、ADD、LABEL、CMD都是保留字,每个保留字都有特定的功能(后面说)
dockerfile的编写规则有以下几点
- 每条保留字指令都必须为大写字母且后面要跟随至少一个参数
- 指令按照从上到下,顺序执行
#表示注释- 每条指令都会创建一个新的镜像层,并对镜像进行提交
docker执行dockerfile的大致流程
docker从基础镜像运行一个容器- 执行一条指令并对容器作出修改
- 执行类似
docker commit的操作提交一个新的镜像层 docker再基于刚提交的镜像运行一个新容器- 执行
dockerfile中的下一条指令直到所有指令都执行完成
从应用软件的角度来看,Dockerfile、Docker镜像与Docker容器分别代表软件的三个不同阶段,
dockerfile是软件的原材料docker镜像是软件的交付品docker容器则可以认为是软件的运行态。dockerfile面向开发,docker镜像成为交付标准,docker容器则涉及部署与运维,三者缺一不可,合力充当Docker体系的基石。
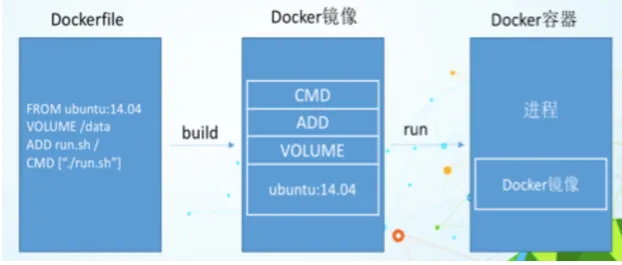
保留字指令
FROM当前新镜像基于哪个镜像MAINTAINET镜像维护者的姓名和邮箱RUN镜像构建(docker build)需要运行的命令EXPOSE当前容器对外暴露的端口WORKDIR指定在创建容器后,终端默认登录进来的工作目录(docker exec -it ID进入容器shell的pwd),一个落脚点ENV用来在构建镜像过程中设置环境变量, 在后续的任何RUN指令或其他指令中使用ARG与ENV作用类似,但有两点区别- 它的作用域仅在构建镜像时,而
ENV设置的环境变量在容器运行时依旧可以访问 ARG的优势在于还可以通过命令行docker build --build-arg接受参数。
- 它的作用域仅在构建镜像时,而
ADD将宿主机目录下的文件拷贝进镜像,且ADD命令会自动处理URL和解压tar压缩包COPY类似ADD,拷贝文件和目录到镜像中。- 语法1 shell格式
COPY src dest - 语法2 exec格式
COPY ["src", "dest"] - 两种格式的区别
- 语法1 shell格式
VOLUME容器数据卷,用于数据保存和持久化工作CMD指定一个容器要运行的命令- 可以有多个
CMD,但只有最后一个生效,CMD会被docker run之后的参数替换 - 与
RUN一样支持两种格式
- 可以有多个
ENTRYPOINT指定一个容器启动时要运行的命令- 与
CMD一样,都是指定容器启动容器及参数,区别是docker run命令后面的参数,CMD是被覆盖 ,ENTRYPOINT是追加
- 与
ONBUILD子镜像被构建,父镜像的onbuild会被触发
注意:这里的指令大都是在镜像构建(docker build)时运行, VOLUME、ENTRYPOINT、CMD、ONBUILD是在创建容器时运行。
dockerfile案例
定制centos镜像 实现对vim 和ifconfig两个命令的支持
dockerfile编写
dockerfile文件内容如下
shFROM centos
MAINTAINER gjw<2315162186@qq.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
# https://stackoverflow.com/questions/70963985/error-failed-to-download-metadata-for-repo-appstream-cannot-prepare-internal
# 这两行修复一个下载源问题
RUN sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*
RUN sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*
RUN yum -y install vim # 安装vim
RUN yum -y install net-tools # 安装net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "success--------------ok"
CMD /bin/bash
- 构建镜像
docker build -t mycentos:1.0 .(这里没有通过-f指定dockerfile文件,因为默认会找名为dockerfile的文件) - 验证效果
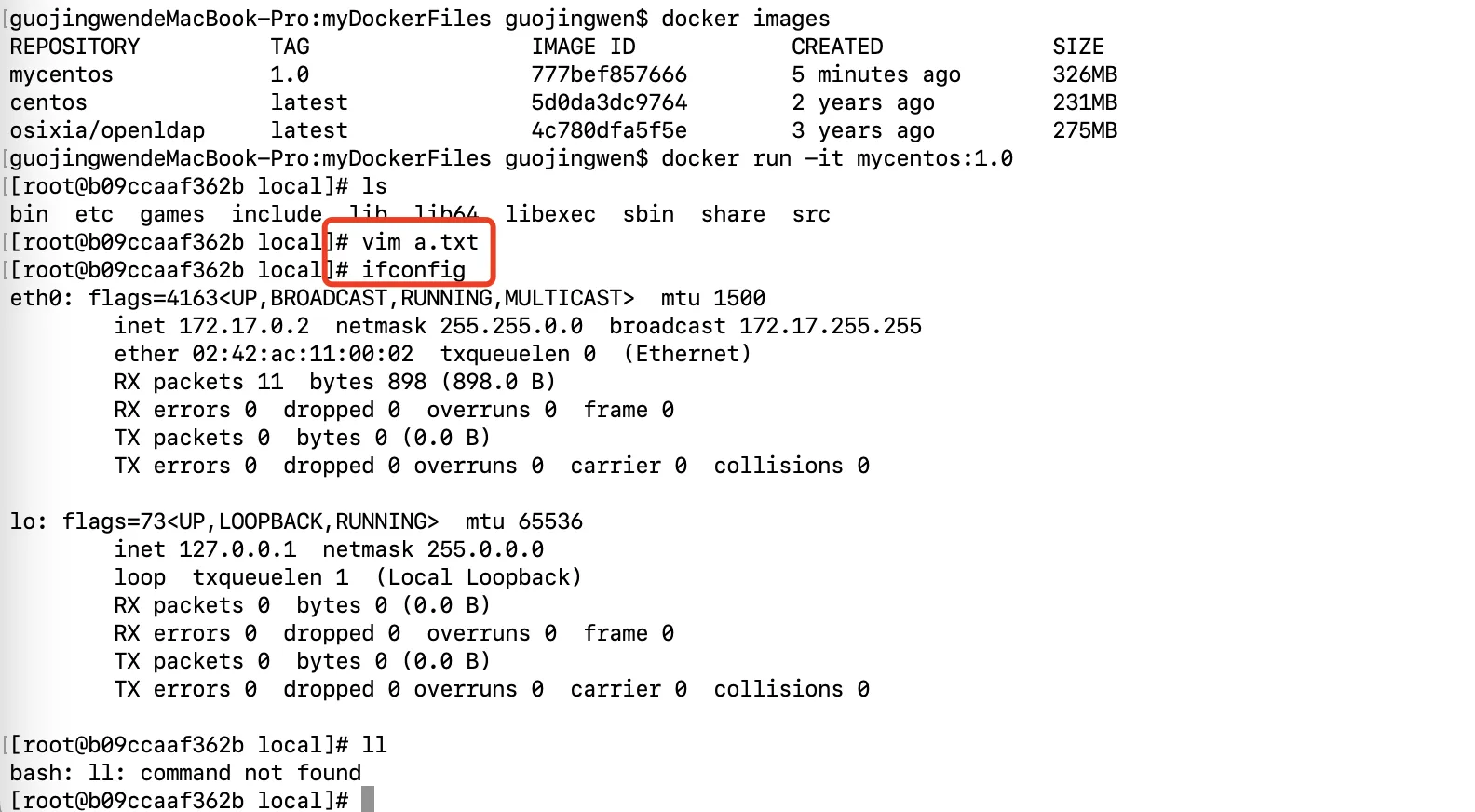
试一下docker history
最后贴一张小结图
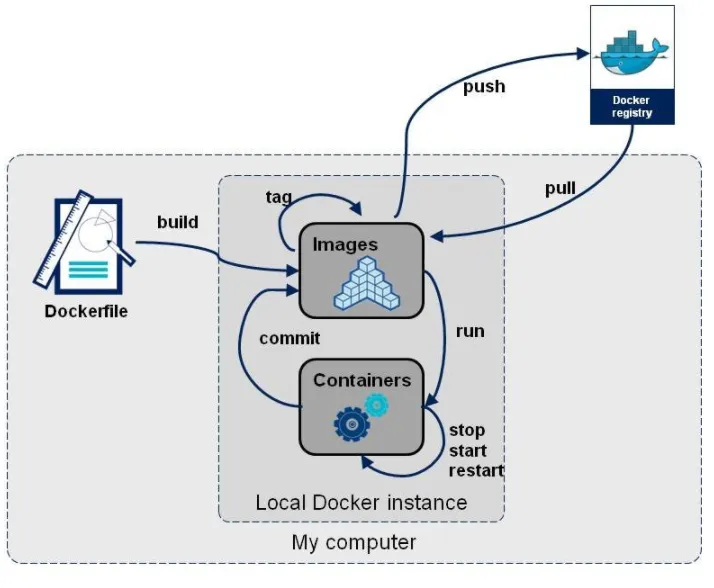
dockerfile编写建议
- 尽量选择体积小的镜像(缺点是基础命令比较少,优点是下载快)
- 尽量选择官方认证的镜像(安全),其次选择有
dockerfile的文件(知道它做了什么) RUN指令尽可能写一行(这样不会生成多层镜像)- 使用dockerfile
- 多阶段构建
- 尽量使用非root用户
docker常见软件安装
tomcat安装
docker pull tomcatdocker run -d -p 8082:8080 tomcat- 浏览器访问http://localhost:8082/
mysql安装
-
docker pull mysql:5.7 -
sudo docker run -p 3306:3306 --name mymysql \
-v $PWD/conf:/etc/mysql/conf.d \
-v $PWD/logs:/logs \
-v $PWD/data:/mysql_data \
-v /etc/localtime:/etc/localtime:ro \
-e MYSQL_ROOT_PASSWORD=todoDream -d mysql:5.7 -
检查
docker ps查看容器是否启动- 在容器内执行一些操作
docker exec -it 容器id /bin/bash
mysql -uroot -p;
show databases;
create database db01;
use db01;
create table t_book(id int not null primary Key, bookName varchar(20));
insert into t_book values (1, 'javascript');
select * from t_book;
exit; - 使用mysql客服端软件(如Navicat for Mysql) 访问检查数据并修改数据
redis 安装
-
docker pull redis:3.2 -
docker run -p 6379:6379 \
-v $PWD/myredis/data:/data \
-v $PWD/myredis/conf/redis.conf:/usr/local/etc/redis/redis.conf:Z \
-d redis:3.2 redis-server /usr/local/etc/redis/redis.conf \
--appendonly yes -
进入容器操作redis
docker exec -it 9d3c49e00ced redis-cli
set k1 v1
exists k1
SHUTDOWN
mongo安装
-
docker pull mongo -
创建目录
mkdir mongodb && cd mongodb -
执行命令
docker run -d -p 27017:27017 \
-v $PWD/mongo_configdb:/data/configdb \
-v $PWD/mongo_db:/data/db --name mymongo mongo
nginx安装
-
docker pull nginx -
创建目录
mkdir -p nginx && cd nginx -
配置启动
nginxdocker run -d -p 443:443 -p 80:80 --name myNginx \
-v $PWD/html/:/usr/share/nginx/html/ \
-v $PWD/conf/nginx/:/etc/nginx/ \
-v $PWD/logs/nginx/:/var/log/nginx/ nginx -
安装上一步会启动失败,原因是当前目录
./conf/目录没有任何配置,先设法去到配置- 简单方式启动
docker run --name myNginx -p 80:80 -d nginx - 取到默认配置文件
docker cp 容器id:/usr/share/nginx/html/ ./mkdir conf && docker cp 容器id:/etc/nginx/ ./confmkdir logs && docker cp 容器id:/var/log/nginx/ ./logs/
docker rm -f 容器id在执行第3步
- 简单方式启动
-
启动以上命令后进入
nginx/www目录,创建index.html
html<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>nginx demo</title>
</head>
<body>
<h1>欢迎光临</h1>
</body>
</html>
node项目案例
我写了一个极简的demo node_docker
dockerfile 如下
yml# 指定node镜像的版本
FROM node:16-alpine
# 声明作者
MAINTAINER gjw<2315162186@qq.com>
# 移动当前目录下面的文件到app目录下
ADD . /app/
# 进入到app目录下面,类似cd
WORKDIR /app
# 安装依赖
RUN npm install
# 对外暴露的端口
EXPOSE 3000
# 程序启动脚本
ENTRYPOINT ["npm", "start"]
这只是一个雏形,使用koa启动一个http服务,然后支持了构建容器时传递参数,没有做数据库连接(一会学习docker compose再补充)。
演示
git clone git@github.com:guojingwen/node_docker.git && cd node_docker- 构建镜像
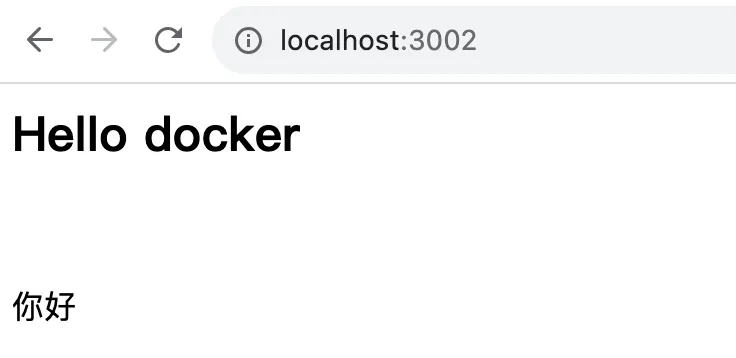
docker build -f dockerfile -t my-server:1.0 . - 启动容器
docker run -it -p 3002:3000 my-server:1.0 -- --env=你好 - 本地访问 http://localhost:3002/
效果如下图
多阶段构建
构建镜像如果把所有内容(编译、测试、打包)都写在一个配置文件里,会存在两个问题
- 镜像层次多,镜像体积较大(包含node_modules),部署时间变长
- 源代码存在泄漏的风险
老的方案是可以通过分离的构建文件,构建多个镜像(丢弃编译时的镜像)以规避上述问题
docker v17.05开始支持多阶段构建 ,参考这篇文章-go语言 和nodejs多阶段构建 我尝试写了一个纯前端案例 代码仓库 dockerfile文件内容如下
yml# FROM node:16-alpine # 方案1
FROM node:16-alpine AS appbuild # 方案2
MAINTAINER gjw<2315162186@qq.com>
WORKDIR /usr/src/app
COPY ./ ./
RUN npm install && npm run build
FROM node:16-alpine
WORKDIR /usr/src/app
#COPY --from=0 /usr/src/app/dist ./dist # 方案1
COPY --from=appbuild /usr/src/app/dist ./dist # 方案2
RUN npm i http-server
EXPOSE 4002
CMD cd ./dist && npx http-server -p 4002
docker 网络
先来了解一下基本的网络相关命令
与网络相关的命令
- 检查网络是否连通
ping命令ping IP-addr - 查看IP地址 linux
ifconfig/ windowipconfig结果关注en0就行了 - 测试端口的连通性
telnet www.baidu.com 80 - 探测IP数据包在网络中走过的路径 linux
traceroute/ windowTRACERT.EXE - 发起HTTP请求
curl命令 brctl show命令,显示linux网络及相关信息ip toute命令 查看路由表ipables --list -t nat查看Nat转发规则dig查看DNS解析more /etc/resolv.conf
docker网络通信模型
- 两台电脑之间通信
插一根网线相互连接,分别分配IP地址即可通信 - 多台电脑之间通信
需要一个路由器或交换机(这里假设是路由器),每台电脑分别与路由器连接,两台电脑之间通信经过路由器中转。路由器会为每台电脑分配IP地址(使用以太网协议)。

docker容器之间的通信过程类似于多台电脑通信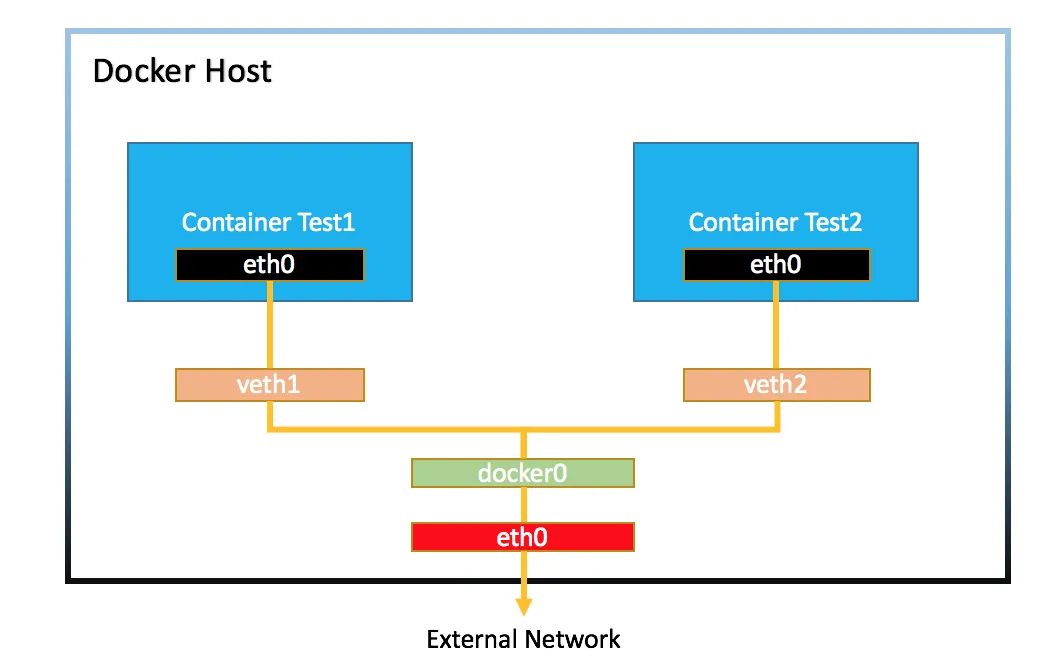
docker启动时默认会建一个网桥 即docker0 它相当于一个路由器的过程。veth1和veth2是docker0(路由器)的网口
- 容器间的相互通信 每启动一个容器 ,网桥
docker0就会给该容器分配IP地址, 这样容器间就能相互通信了 - 容器与外部通信
- 假设
docker0(路由器)的子网掩码172.17.0.0/16,那么网管地址为172.17.0.1,容器Test1的IP为172.17.0.2/16,宿主机IP为192.168.200.10,子网掩码为192.168.200.0/24 - 容器
Test1想要对外通信,Test1通过网孔网线到达docker0通过NAT技术 将172.17.0.2转换为192.168.200.10,剩下的工作就是宿主机与外部通信,原理类似也是NAT技术,宿主机也是通过路由器往外通信的,这个路由器肯定有一个公网IP的 - 补充说明:
NAT技术就是通过端口映射,实现多个设备共享同一个公网IP
- 假设
- 外部与容器通信 端口映射
-p- 可以拆解为外部与宿主机通信(利用路由器NAT技术)
- 宿主机与容器通信(利用docker网桥NAT技术)
大致原理就是这样,假设你已经懂了。推荐按照这篇文章体验一下
自定义网桥
docker网络默认的bridge没有dns功能,可以通过
docker network create -d bridge mybrige创建一个名为mybrige的网桥docker network ls查看docker网络docker network inpsect mybrige查看网桥信息- 创建容器时通过
--network网桥,docker container run -d --name box2 --network mybrige busybox /bin/sh -c "while true; do sleep 3600; done"- 这时候再次查看
mybrige网桥信息会更新(增加了网口)
- 连接到不同网桥的两个容器之间网络是不通的, 你可以通过如下命令测试
docker container exec -it box1 ping box2的IP - 可以让一个容器连接多个网桥
docker network connect bridge box2, 相对应的可以通过discontect关闭连接
自定义网桥的好处是两个网桥之间不仅可以通过IP地址通信, 还可以通过容器名称通信(测试命令:docker container exec -it box1 ping box2),因为自定义的网桥含有DNS解析的功能
除了自定义网络还可以使用宿主机网络,
比如 docker container run -d --name web --network host nginx 减少了端口映射的损耗。
自定义网桥实战(24年1月更新)
一个完整的项目由多个应用组成, 比如nodejs后端服务,mysql数据库,redis持久化,使用docker-compose 就够了。
(插个小知识点。docker-compose踩坑笔记
docker-compose生成的容器是基于所在服务器,如果你有两个docker-compose.yml文件所在不同的目录,但文件夹名称一样,这是两个docker容器会相互卸载)
由于重复创建容器会占用服务器资源,比如mysql我想复用已有的容器,不想再重新创建了,但是由于docker容器是隔离环境包括网络,nodeJS应用无法访问mysql。
理论上可以通过一下两个方案解决
nodejs容器和mysql容器都使用宿主机网络nodejs容器和mysql都适用默认的网桥,由于默认网桥没有dns存在,需要配置,现获取到mysql容器的局域网ip,然后在.env文件中配置
遗憾的是这两个方案,我都没有跑通,但是我发现了另一个更便捷的方式,就是自定义网桥,然后把nodejs和mysql容器都加入这个网桥中。
docker network create -d bridge mybridgedocker network connect mybridge your_mysqldocker network connect mybridge your_nodejs_proj.env文件可以夹入通过dns访问mysql了mysql=http://your_mysql:3306
当然你也可以在docker-compose.yml中配置使用外部网桥
ymlversion: "3.7"
services:
your_nodejs_proj:
networks:
- existing_network
networks:
existing_network:
external: true
name: mybridge
由于一个容器可以加入多个网桥, 这样你就可以随意组合了,非常好用。
至于前面两个方案为什么没跑通,是我姿势哪里有问题? 有空在研究,先记一下笔记。
docker-compose
比如我们部署一个nodejs应用,nodejs应用需要一个容器,数据库也需要一个容器,可能还需要redis去持久化缓存。基于类似这样的需求(一个应用需要多个容器)诞生了 docker compose技术,可以粗暴理解一下它是应用创建start.sh和关闭stop.sh的脚本,这个脚本采用yml格式编写, 默认文件名docker-compose.yml
docker-compose配置文件
ymlversion: "3.8"
services: # 容器
servicename: # 服务名字,这个名字也是内部 bridge网络可以使用的 DNS name
image: # 镜像的名字
command: # 可选,如果设置,则会覆盖默认镜像里的 CMD命令
environment: # 可选,相当于 docker run里的 --env
volumes: # 可选,相当于docker run里的 -v
networks: # 可选,相当于 docker run里的 --network
ports: # 可选,相当于 docker run里的 -p
servicename2:
volumes: # 可选,相当于 docker volume create
networks: # 可选,相当于 docker network create
关于version表示docker compose的语法版本,与docker版本有一些对应关系, 具体对应关系点这里
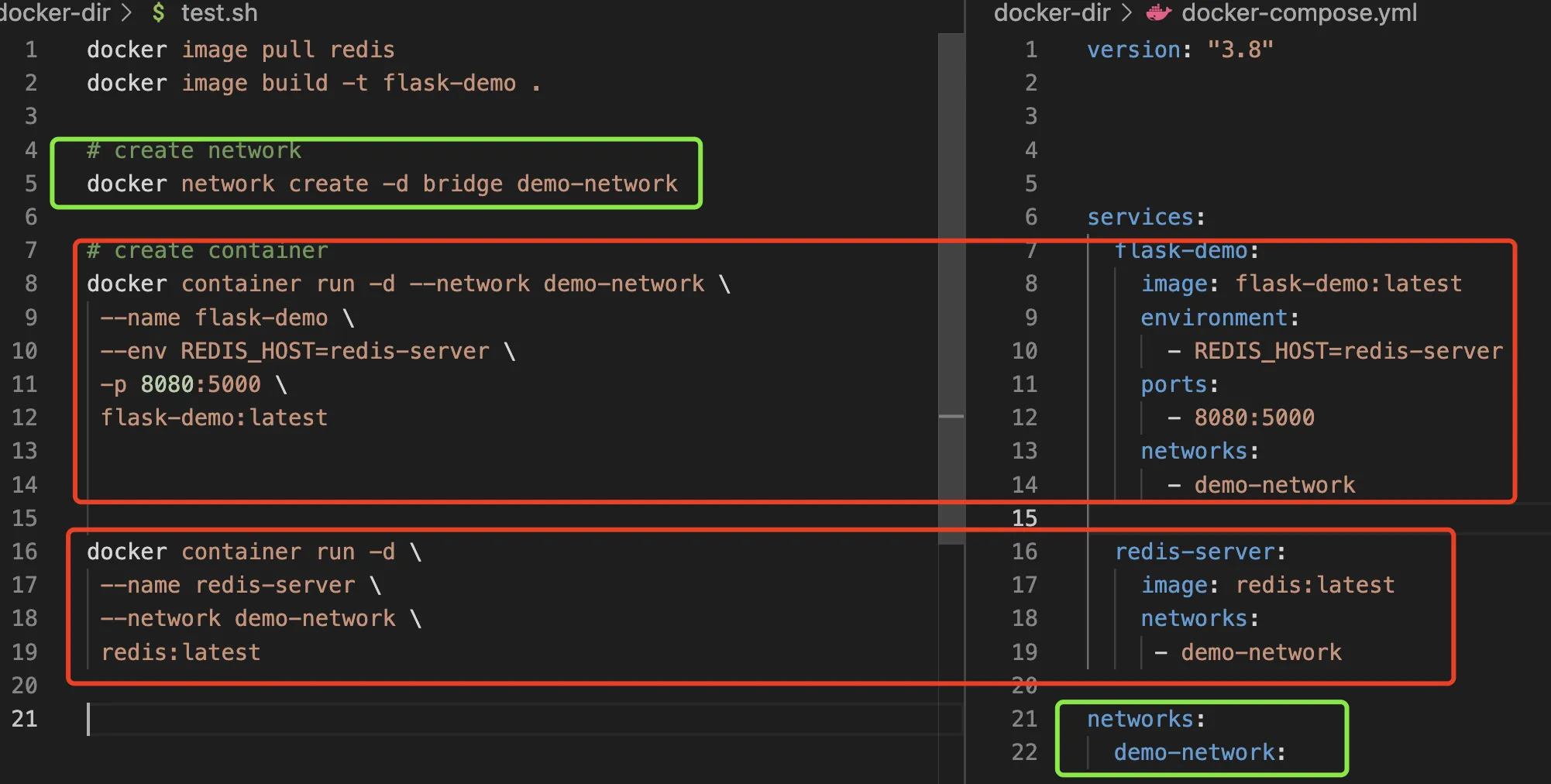
看一例子,体验一下docker-compse做了哪些事情
配置文件可以动态传参吗?
当然可以!
在配置文件同级创建一个.env文件
.env文件
PASSWORK=abc123
- 在
docker-compse.yml引用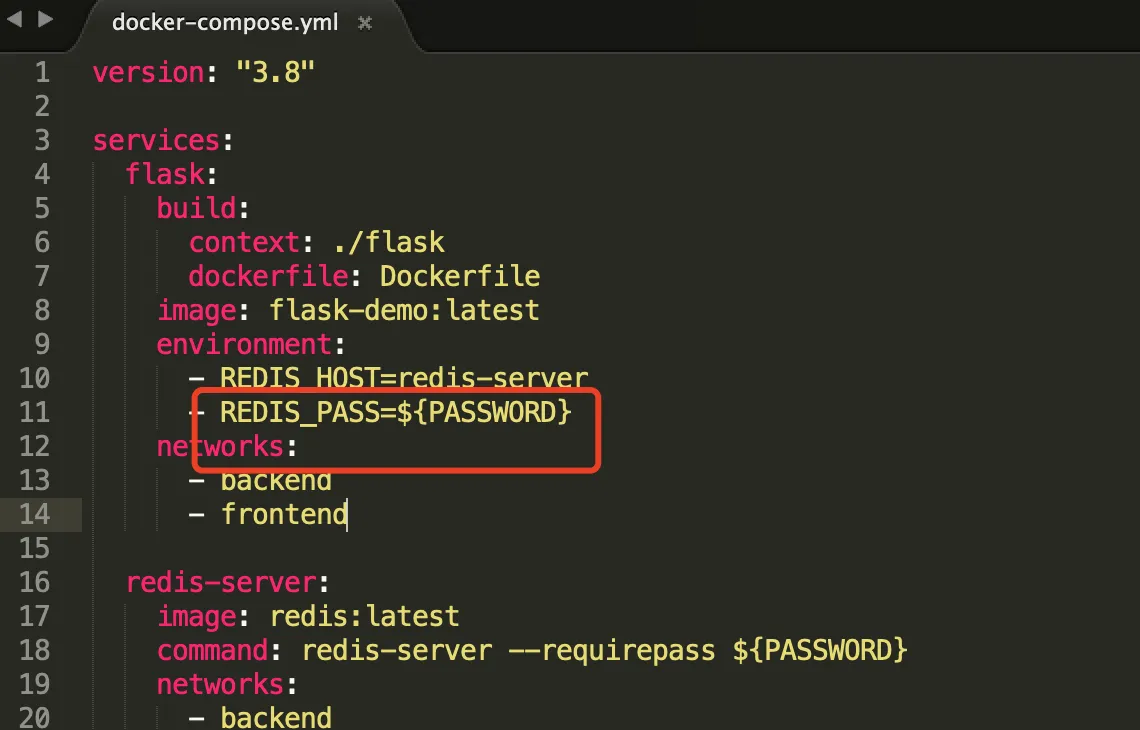
- 最后通过
docker-compose config命令验证配置文件- 补充: 可以通过
--env-file指定env文件名 例:--env-file .\myenv
- 补充: 可以通过
这样写安全吗?
可以通过.gitignore忽略.env文件的提交
如果容器之间有依赖呢?
service.depends_on
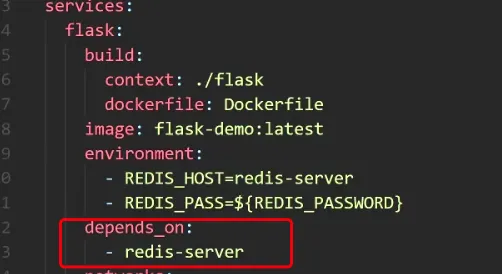
docker-compose 相关命令
docker-compose要在含有docker-compose.yml的目录下运行, 或者通过-f指定配置文件
docker-compose up运行容器,- 会依次执行拉去或构建镜像、创建容器,进入命令行前台
- 容器名:默认会以当前文件夹作为命名前缀,并增加
_数字的后缀可以通过-p修改前缀, 当然如果你不想要前缀可以在配置文件里定义容器名称service.container(不建议) -d在后台运行
- 可以通过
docker-compose log查看日志-f持续动态查看日志
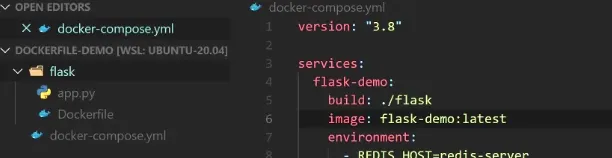
docker-compose up停止相关容器docker-compose rm移除相关停止的容器docker-compose build根据配置文件构建所需镜像- 指定文件夹
- 指定文件夹和
dockerfile文件名 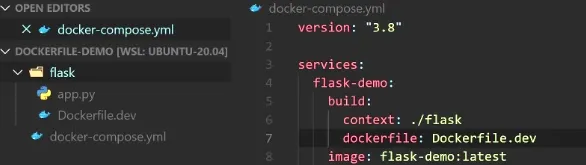
docker compose的更新策略
默认docker-compose up -d 会根据配置文件的调整(新增或修改)对应容器、网络等,如果有删除容器会提示warning。 但是如果镜像的源码发生改变不会重新构建镜像。
想要重新构建镜像需要增加--build参数,命令为docker-compose up -d --build
docker system prune -f 会系统清理非运行的容器、未被使用的容器卷、网络、镜像。
关于docker-compose的网络,即使配置文件没有声明网络docker-compose也会创建一个类似的自定义网桥,内置DNS解析。(docker创建的容器默认没有DNS解析)
docker-compse 水平扩展
先说有两个疑问,
- 前面提到
docker-compose启动容器时默认会加一个后缀_数字 - 本文开头提到
docker的优势 更便捷的扩容所容。
“水平扩展” 就是指动态扩容和所容,此外docker-compse内置的dns还做了负载均衡。有兴趣的可以参考这一篇文章试试看
docker-compose 健康检查
dockerfile文件增加HEALTHCHECK字段 示例:
ymlHEALTHCHECK --interval=30s --timeout=3s\
CMD curl -f http://localhost:5000/ || exit 1
容器的状态有三种 starting、unhealthy、healthy
官方文档对失败的定义是连续3次失败,容器状态才会变成unhealthy。可以通过 --retries=N指定尝试次数。

docker-compose健康检查 与在dockerfile文件配置差不多,看个示例代码
docker-compose.yml
ymlversion: "3.8"
services:
flask:
build: ./flask # ./flask/Dockerfile
image: flask-demo:latest
environment:
- REDIS_HOST=redis-server
- REDIS_PASS=${REDIS_PASSWORD}
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5000"]
interval: 30s
timeout: 3s
retries: 3
start_period: 40s
depends_on:
- redis-server:
condition: service_healthy
redis-server:
image: redis:latest
command: redis-server --requirepass ${REDIS_PASSWORD}
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 1s
timeout: 3s
retries: 30
nginx:
image: nginx:stable-alpine
ports:
- 8000:80
depends_on:
flask:
condition: service_healthy
volumes:
- ./nginx/nginx.conf:/etc/nginx/conf.d/default.conf:ro
- ./var/log/nginx:/var/log/nginx
该配置文件启动有三个容器 flask-demo、redis-server、nginx
根据依赖关系,先启动redis-server
接着对redis-server健康检查,健康检查完成再启动flask-demo
最后对flask-demo进行健康检查,启动nginx
最后关于docker-compose有一个著名的案例 投票练习app
nodejs+mysql案例
我写了一个nodejs+mysql的服务使用docker-compose部署
配置文件docker-compose.yml内容如下
ymlversion: '3.7'
services:
server:
build:
context: ./server/
dockerfile: dockerfile
restart: always
environment:
TZ: "Asia/Shanghai"
MYSQL_HOST: "mysql-server"
MYSQL_USER: ${MYSQL_USER}
MYSQL_PASSWORD: ${MYSQL_PASSWORD}
MYSQL_DB: ${MYSQL_DB}
ports:
- 3002:3001
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3001"]
interval: 30s
timeout: 3s
retries: 3
depends_on:
- mysql-server
restart: on-failure
mysql-server:
build: ./db/
environment:
MYSQL_ROOT_PASSWORD: ${MYSQL_PASSWORD}
MYSQL_DATABASE: ${MYSQL_DB}
ports:
- 3306:3306
healthcheck:
test: ["CMD", "mysqladmin" ,"ping", "-h", "localhost"]
timeout: 20s
retries: 10
restart: always
生产环境可以用docker-compose吗
一般企业只在测试环境下使用docker-compose,生产环境下不使用docker-compose的。因为docker-compose只适用于单机模式,万一宕机了怎么办?生产环境需要多机环境进行集群负载均衡等。
如何在多级环境下运行docker容器,这个问题被称为容器编排。
docker容器编排有两中方式 docker swarm or kubernetes。
在容器编排领域kubernetes处于绝对领先地位,但是swarm属于简单的轻量级的容器编排,它们之间的共性很多
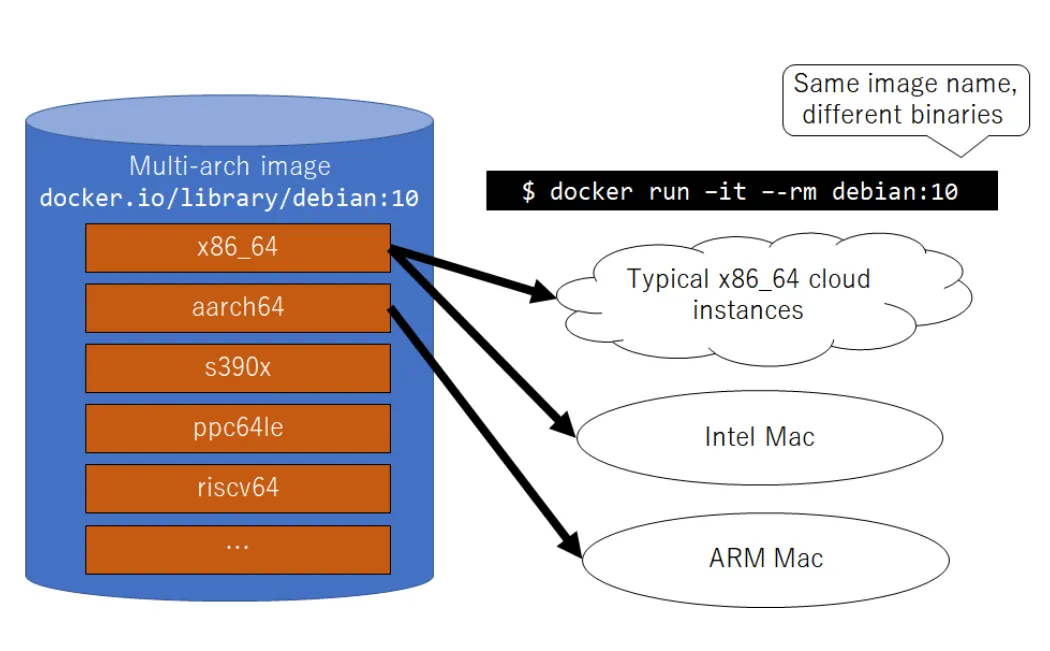
docker多架构支持
这里的多架构是指CPU架构,比如你在linux x86_64构建的镜像上传到hub.docker.com,测试拉去镜像后在自己的电脑(假设是mac M1芯片,对应的CPU是arm架构)上无法运行,这就需要你构建ARM的包。
如果专门去找ARM芯片的电脑这个成本太大了,docker 提供了buildx构建工具,构建命令示例
docker buildx build --push --platform linux/arm/v7,linux/arm64/v8,linux/amd64 -t xiaopeng163/flask-redis:latest .
具体案例推荐按这篇文章尝试
docker调试技巧
常用调试命令
docker inspect 容器ID# 可以查看容器信息,里面包含容器配置、日志、映射等docker logs -f -t --tail 容器id#-f跟随最新的日志打印,-t时间戳--tail最后多少条docker top 容器ID// 查看容器内部进程- 进入容器
docker exec和docker attach
如果容器正常运用以上命令操作容器能处理大部分问题
如果容器不能正常运行的话
使用docker inspect 或 docker logs 查看日志分析原因
只要容器存在,容器内的任何文件都可以在宿主机上找到
- 通过
docker inspect找到MergedDir这个是容器相对宿主机的路径,通过sudo命令可以操作里面的任意文件尝试解决问题 - 如果找不到
MergedDir这个字端,尝试启动一下容器,让它产生日志信息,在使用命令sudo find / -cmin 1查找最后一分钟有变化的文件,进而找到容器在宿主机的位置。一般而言容器在宿主机的路径为/var/lib/docker/aufs/diff/容器完整id - 容器环境和宿主机会有差异,容器内的可执行命令会少很多,可以在宿主机上操作
/var/lib/docker/aufs/diff/容器完整id该路径下的文件
本文作者:郭敬文
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!