目录
React理念
React是用JavaScript构建快速响应的大型Web应用程序的首选方式。
ui = render(data) --> 单向数据流
可见,关键是快速响应。
快速响应
我们知道JS执行与DOM渲染是互斥的,JS的执行会阻塞DOM渲染,DOM渲染同样阻塞JS执行。那么浏览器为什么要这样设计呢?
因为这样简单!JS诞生之初只是一些处理表单校验的脚本,考虑的非常简单,试想一下,如果JS执行与DOM渲染并行,那么JS多次操作DOM时,DOM的状态是怎样的?先响应哪一次操作呢?想要解决这个问题就必须要引入线程锁,在深层考虑还需要事务机制,总之就会比较复杂。
制约快速响应的因素是什么?
- CPO卡顿:当遇到大计算量的操作或者设备性能不足使页面掉帧,导致卡顿
- IO卡顿:发送网络请求后,由于需要等待数据返回才能进一步操作导致不能快速响应。
为什么浏览器渲染会丢帧?
浏览器根据垂直同步信号进行渲染,该信号的周期是16.67ms,如果JS执行或渲染时间过长,就会错过一个垂直同步信号,等待下一次信号, 大于人眼能分辨的最小帧率,被识别出来丢帧
React是如何解决上述问题的?
CPU卡顿
- 浏览器在渲染一帧的时间中,预留一些时间给JS线程,React利用这部分时间更新组件(可以看到,在源码中,预留的初始时间是5ms)
- 当预留时间不够用时,React将线程控制权还给浏览器使其有时间渲染UI,React则等待下一帧时间到来继续被中断的工作。
- 这种将长任务分拆到每一帧中,像蚂蚁搬家一样一次执行一小段任务的操作,被称为时间切片
javascript// 通过使用ReactDOM.unstable_createRoot开启Concurrent Mode
// ReactDOM.render(<App/>, rootEl);
ReactDOM.unstable_createRoot(rootEl).render(<App/>);
总结: 解决CPU瓶颈的关键是时间切片,而时间切片的关键是,将同步更新变为可中断的异步更新
IO卡顿
网络延迟是开发者无法解决的。如何在网络延迟客观存在的前提下,减少用户对网络延迟的感知?
React给出的答案是,将人机交互研究的结果整合到真实的UI中,
为此React实现了Suspense功能及配套的hook useDeferredValue
React15架构
React15架构可以分为两层:
- Reconciler(协调器) 负责找出变化的组件
- Renderer(渲染器) 负责将变化的组件渲染到页面上
Reconciler协调器
我们知道React可以通过this.setState、this.forceUpdate、ReactDOM.render等API触发更新
每当有更新发生,Reconciler会做如下工作:
- 调用函数组件或
class组件的render方法,将返回的JSX转换为VDOM - 对比新旧
VDOM - 找出本次更新中变化的
VDOM - 通知
Renderer将变化的VDOM渲染到页面上
Renderer渲染器
由于react支持跨平台,所以不同平台有不同的Renderer
ReactDOMweb渲染ReactNative渲染APP原生组件ReactTest渲染出纯JS对象,仅用于测试ReactArt渲染到Canvas/SVG或VML(IE8)
React15 架构的缺点
react15采用递归更新,递归一旦开始就无法中断,当DOM层级很深时,交互就会卡顿
对此React团队提出了新的方案,使用可中断的异步更新代替同步的更新
React新架构
React16架构如下
Scheduler(调度器)—— 调度任务的优先级,高优任务优先进入Reconciler- 实现时间切片和调度优先级(lan模型)
Reconciler(协调器)—— 负责找出变化的组件 (render阶段)- 创建or更新Fiber(为相应的fiber打上标签)生成一个effectList链表
Renderer(渲染器)—— 负责将变化的组件渲染到页面上 (commit阶段)- 不同的平台有不同的实现,处理
effectList链表,将副作用反应到真实的DOM中
- 不同的平台有不同的实现,处理
可见,react16 增加了调度器。
Scheduler
解决卡顿的关键是使用可中断异步更新,那么什么时候可以中断呢?
需要一种机制,判断当前浏览器是否有空余时间,其实部分浏览器已经有这个API
requestIdleCallback,但是它存在兼容性和不稳定性问题,还有不支持调度优先级。
所以react决定自己实现一套调度机制,这就是Scheduler
Reconciler
react15中的reconciler采用递归处理VDOM,递归不支持中断,如果继续在15架构基础上改造支持中断更新,会出现更新时DOM渲染不完全的问题。
如何解决更新DOM不完整的问题?
为此react16的reconciler与renderer不再是交替工作,当Scheduler将任务交给Reconciler后,Reconciler会为变化的VDOM打上标记(增/删/改)。整个Scheduler和Reconciler是在内存中进行,只有所有组件都完成Reconciler工作才会统一交给Rendener。
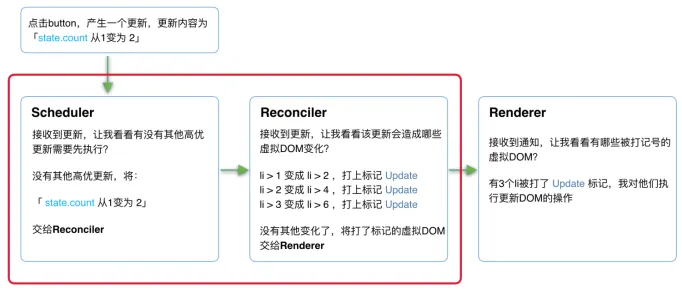 红框中的步骤可以随时被打断
红框中的步骤可以随时被打断
- 有其他更高优任务需要先更新
- 当前帧没有剩余时间
由于红框中的工作都在内存中进行,不会更新页面上的DOM,所以即使反复中断,用户也不会看见更新不完全的DOM
心智模型-代数效应
Fiber是一个计算机术语,中文译为纤程。它与线程、协程同为程序的执行过程 我们把纤程、协程理解为代数效应思想在JS中的体现。 个人理解:React Fiber就是为了践行代数效应准备的。它是组织纤程代码执行的单元
- React核心成员说,在React中做的事情就是践行代数效应。
- 代数效应是函数式编程中的一个概念,用于将副作用从函数中分离。
- 解决副作用的方式我们首先想到的是
async/await,但是async具有传染性(调用它的函数也必须是async) - 为此,虚构了一个语法
try...handle和perform、resume
javascriptfunction getPrice(id) {
const price = perform id;
return price;
}
function getTotalPirce(id1, id2) {
const p1 = getPrice(id1);
const p2 = getPrice(id2);
return p1 + p2;
}
try {
getTotalPrice('001', '002');
} handle (productId) {
fetch(`xxx.com?id=${productId}`).then((res)=>{
resume with res.price
})
}
/*
如何理解上述代码?
- 其中perform和handle是虚构的语法
- 当代码执行到perform的时候会暂停当前函数的执行,并且被handle捕获
- handle函数体会拿到productId参数获取数据之后resume价格
- resume会回到之前的perform暂停的地方并返回price
- 这就完全把副作用分离到了getTotalPrice和getPrice之外。
这里的关键流程是perform暂停函数的执行,handle获取函数的执行权,resume交出函数的执行权
*/
// 上述代码是抽象的,实际代码如下
function usePrice(id){
useEffect(() => {
fetch(`xxx.com?id=${productId}`).then((res) => res.price);
}, [])
}
function TotalPrice({id1, id2}) {
const price1 = usePrice(id1);
const price2 = usePrice(id2);
return <TotalPrice props={...}>
}
Q: 为什么不使用Generator?
- 类似async,也具有传染性
- generator的中间状态是上下文关联的
若只考虑单一任务的中断与继续情况下Generator可以很好的实现异步可中断更新 当高优先级插队,就需要引入全局变量保存当前generator的中间状态,另外在新建一个高优先级generator,引入新的复杂度
如何理解Fiber架构如何践行(模拟or实现)代数效应?
- 严格上讲react是不支持代数效应的,try...handle可以用try...catch模拟,throw errer放在微任务中即可,但是 中断与恢复无法模拟
- 但是react有fiber,执行完这个Fiber的更新之后交还给执行权给浏览器,让浏览器决定怎么调度 (中断与恢复可理解为渲染一帧完成后继续执行JS, Fiber会保存中间状态)
Susperse也是这种概念的延伸
- throw一个Promise,拿到数据通过Promise回调结果,外层组件收到回调结果触发setData, 给人的感觉是实现了代数效果
Fiber是什么
定义: React内部实现的一套状态更新机制。支持任务不同优先级,可中断与恢复,并且恢复后可以复用之前的中间状态。
功能:
- 作为架构
React15的Reconciler采用递归的方式执行,被称为stack Reconciler。React16的Reconciler基于Fiber节点实现,被称为Fiber Reconciler; - 作为静态的数据结构来说,每个
Fiber节点对应一个React emement,保存了该组件的状态(函数需要被删除/被插入页面中/被更新...); - 作为动态的工作单元来说,每个
Fiber节点保存了本次更新中该组件改变的状态、要执行的工作(增删改)
Q:ReactFiber如何更新DOM?
使用双缓存(在内存中构建并直接执行替换的技术叫做双缓存)。
在React中最多会同时存在两课Fiber树,屏幕显示的为current fiber树,内存中正在构建的Fiber树称为workInProgress Fiber树。它们通过alternate属性连接
fiberRootNode整个应用的跟节点rootFiber<APP/>所在组件的根节点
所有fiber节点都有alternate属性,通过任意组件发生更新,修改alternate指针
JSX与Fiber
JSX和Fiber节点是同一个东西吗?React Component、React Element是同一个东西吗,它们和JSX有什么关系?
JSX在编译时会被React.createElement方法,这也是为什么要引入 import React from 'react';的原因。
JSX与Fiber节点的关系
JSX是一种描述当前组件内容的数据结构,他不包含组件schedule、reconciler、render所需的相关信息(组件在更新中的优先级、组件的state、组件被打上的用于Renderer的标记)。Fiber更多的是一种更新机制- 在组件
mount时,Reconciler根据JSX描述的组件内容生成组件对应的Fiber节点 - 在
update时,Reconciler将JSX与Fiber节点保存的数据对比,生成组件对应的Fiber节点,并根据对比结果为Fiber节点打上标记
Render阶段
reconciler的执行对应的就是render阶段,该阶段主要是生成新的workInProgressFiberTree
虽然fiber reconciler是从stack reconciler重构而来,但都是通过遍历的方式实现可中断的异步递归
- 递
beginWork传入当前Fiber节点,创建子Fiber节点 - 归
completeWork针对不同的fiber.tag调用不同的处理逻辑
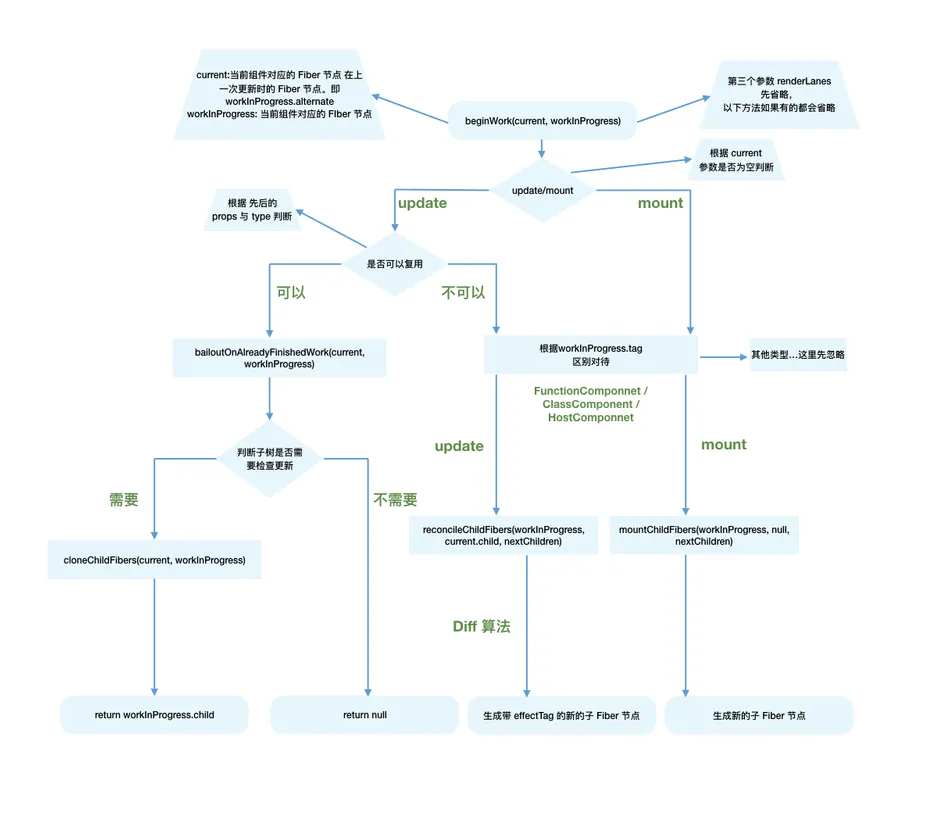
beginWork的主要工作
mount时:除fiberRootNode以外,current === null。会根据fiber.tag不同,创建不同类型的子Fiber节点;update时:如果current存在,在满足一定条件时可以复用current节点,这样就能克隆current.child作为workInProgress.child,而不需要新建workInProgress.child;
总结:beginWork就是创建Fiber节点
effectTag
- render阶段的工作是在内存中进行,当工作结束后会通知Renderer需要执行的DOM操作。要执行DOM操作的具体类型就保存fiber.effectTag中
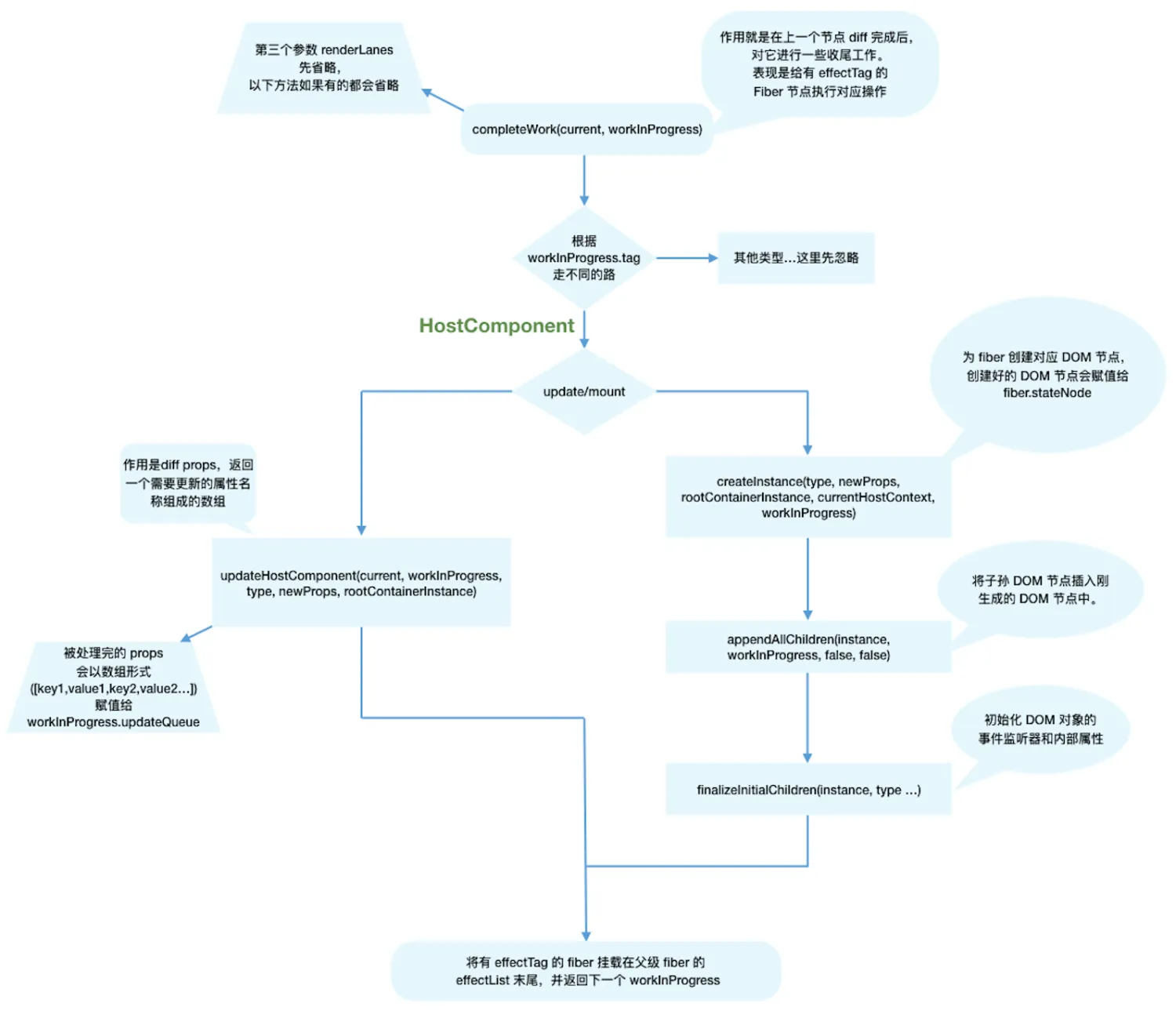
completeWork
根据不同的fiber.tag生成不同的处理逻辑
- 判断
update时我们还需要考虑workInProgress.stateNode != null?(即该Fiber节点是否存在对应的DOM节点) - 当
update时,Fiber节点已经存在对应DOM节点,所以不需要生成DOM节点。需要做的主要是处理props,比如:onClick、onChange等回调函数的注册- 处理
styleprop - 处理
DANGEROUSLY_SET_INNER_HTML prop - 处理
children prop
- mount时
- 为
Fiber节点生成对应的DOM节点 - 将子孙
DOM节点插入刚生成的DOM节点中 - 与
update逻辑中的updateHostComponent类似的处理props的过程
- 为
总结:completeWork就是创建Fiber节点
effectList
Q:作为DOM操作的依据,completeWork阶段需要找到所有effectTag的Fiber节点并依次执行effectTag对应操作。难道需要在commit阶段再遍历一次Fiber树寻找effectTag !== null的Fiber节点么?
A: completeWork在上层函数completeUnitOfWork上维护了一个单向链表
effectList中第一个Fiber节点保存在fiber.firstEffect,最后一个元素保存在fiber.lastEffect。
类似appendAllChildren,在“归”阶段,所有有effectTag的Fiber节点都会被追加在effectList中,最终形成一条以rootFiber.firstEffect为起点的单向链表。

commit阶段
commitRoot(root);
- 在
rootFiber.firstEffect上保存了一条需要执行副作用的Fiber节点的单向链表effectList, - 这些
Fiber节点的updateQueue中保存了变化的props - 这些副作用对应的
DOM操作在commit阶段执行。 - 除此之外,一些生命周期钩子(比如
componentDidXXX)、hook(比如useEffect)需要在commit阶段执行。 commit阶段的主要工作(即Renderer的工作流程)分三个部分:
before mutation阶段(执行DOM操作前)- 主要做一些变量赋值,状态重置的工作,具体如下
- 处理DOM节点渲染删除后的
autoFocus、blur等操作 getSnapshotBeforeUpdateuseEffect
mutation阶段(执行DOM操作前)- 根据
ContentReseteffectTag重置文字节点 - 更新
ref - 根据
effectTag分别处理,其中effectTag包括(Placement|Update|Deletion|Hydrating)
- 根据
layout(执行DOM操作前)useEffect相关处理- 性能追踪相关
- 一些生命周期钩子
Q:为什么从Reactv16开始,componentWillXXX钩子前增加了UNSAFE_前缀?
在
React更新里,每次发起更新都会创建一个Update对象,同一组件的多个Update,会以链表的形式保存在updateQueue中。 假设,某个组件updateQueue存在4个update,数字代表优先级
javascriptbaseState = '';
A1 - B2 - C1 - D2
// 为了保证更新的连贯性,第一个被跳过的update(B)和后面的update会作为第二次渲染的baseUpdate
// 为BCD
// 首次渲染后
baseState: ''
Updates: [A1, C1]
Result state: 'AC'
// 第二次渲染,B在第一次渲染时被跳过,
// 所以在他之后的C造成的渲染结果不会体现在第二次渲染的baseState中。
// 所以baseState为A而不是上次渲染的Result state AC。
// 这也是为了保证更新的连贯性
baseState: 'A' // 为了保证一致性,C不在
Updates: [B2, C1, D2]
Result state: 'ABCD'
// Updates里出现了两次C
与
componentDidMount、componentDidUpdate不同的是,在浏览器完成布局与绘制之后,传给useEffect的函数会延迟调用。这使得它适用于许多常见的副作用场景,比如设置订阅和事件处理等情况,因此不应在函数中执行阻塞浏览器更新屏幕的操作。
防止同步执行时阻塞浏览器渲染
Q:渲染DOM中时间复杂度最高的操作是?
getHostSibling(获取兄弟DOM节点)
当在同一个父Fiber节点下依次执行多个插入操作,getHostSibling算法的复杂度为指数级。
这是由于Fiber节点不只包括HostComponent,所以Fiber树和渲染的DOM树节点并不是一一对应的。要从Fiber节点找到DOM节点很可能跨层级遍历。
javascriptfunction Item() {
return <li><li>;
}
function App() {
return (
<div>
<Item/>
</div>
)
}
ReactDOM.render(<App/>, document.getElementById('root'));
// Fiber树
child child child child
rootFiber -----> App -----> div -----> Item -----> li
// DOM树
#root ---> div ---> li
// 在div的子节点Item前加一个p
function App() {
return (
<div>
<p></p>
<Item/>
</div>
)
}
// Fiber树
child child child
rootFiber -----> App -----> div -----> p
| sibling child
| -------> Item -----> li
// DOM树
#root ---> div ---> p
|
---> li
// 此时dom中p的兄弟节点是li
// fiber中fiberP的兄弟节点是fiberItem,fiberItem的子节点才是li
Q:双缓存切换执行时间
mutation阶段结束后,layout阶段开始前
- componentWillUnmount在mutation阶段执行。此时current Fiber树还指向前一次更新的Fiber树,在生命周期钩子内获取的DOM还是更新前的;
- componentDidMount和componentDidUpdate会在layout阶段执行。此时current Fiber树已经指向更新后的Fiber树,在生命周期钩子内获取的DOM就是更新后的
Diff
在render阶段,对于update的组件,他会将当前组件与该组件在上次更新时对应的Fiber节点比较(也就是俗称的Diff算法),将比较的结果生成新Fiber节点。 官网对diff算法的介绍
- 不同类型的元素:React拆卸原有的树,生成新的树 调用周期函数
- 同一类型的元素
- 保留DOM节点,仅对比更新有改变的属性
- 对比同类型的组件元素
- 组件更新时,调用周期函数 willMount willUpdate DidUpdate
- 调用render执行diff
结合render和commit阶段,一个DOM节点最多有4个节点与之相关:
- current Fiber。如果该DOM节点已在页面中,current Fiber代表该DOM节点对应的Fiber节点;
- workInProgress Fiber。如果该DOM节点将在本次更新中渲染到页面中,workInProgress Fiber代表该DOM节点对应的Fiber节点;
- DOM节点本身;
- JSX对象
diff算法:对比1 4 生成2
Diff的瓶颈
diff操作本身也会带来性能损耗,React文档中提到,即使在最前沿的算法中,将前后两棵树完全比对的算法的复杂程度为 ,其中是树中元素的数量;如果在React中使用了该算法,那么展示1000个元素所需要执行的计算量将在十亿的量级范围。这个开销实在是太过高昂;
为了降低算法复杂度,React的diff会预设三个限制:
- 不考虑元素层级移动的问题;
- 标签更换,销毁后代元素重新创建
- 通过 key 告知哪些子元素在不同的渲染下能保持稳定;
单节点Diff
根据同级的节点数量将Diff分为两类:
- 当newChild类型为object、number、string,代表同级只有一个节点
- 当newChild类型为Array,同级有多个节点
单节点 diff
- 先判断key是否相同,如果key相同则判断type是否相同,只有都相同时一个DOM节点才能复用;
- 删除逻辑:
- 当child !== null且key相同且type不同时执行deleteRemainingChildren将child及其兄弟fiber都标记删除;
- 当child !== null且key不同时仅将child标记删除;
多节点Diff
react团队提供的思路:2轮遍历
- 处理 更新 的节点;
- 处理非 更新 的节点;
第一轮遍历 --- 找出可复用(以头部为标志)的节点, lastIndex表示最后一个可复用节点的索引
第二轮遍历 分析第一轮遍历有四种情况
- newChildren 和 oldFiber 同时遍历完 - 结束了
- newChildren没遍历完,oldFiber遍历完 - 追加
- newChildren遍历完,oldFiber没遍历完 - 删除
- newChildren与oldFiber都没遍历完 - 重点讨论这个
如何处理更新后的节点? -- 标记节点是否移动
javascript// 之前
abcd
// 之后
acdb
===第一轮遍历开始===
a(之后)vs a(之前)
key不变,可复用
此时 a 对应的oldFiber(之前的a)在之前的数组(abcd)中索引为0
所以 lastPlacedIndex = 0;
继续第一轮遍历...
c(之后)vs b(之前)
key改变,不能复用,跳出第一轮遍历
此时 lastPlacedIndex === 0;
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === cdb,没用完,不需要执行删除旧节点
oldFiber === bcd,没用完,不需要执行插入新节点
将剩余oldFiber(bcd)保存为map
// 当前oldFiber:bcd
// 当前newChildren:cdb
继续遍历剩余newChildren
key === c 在 oldFiber中存在
const oldIndex = c(之前).index;
此时 oldIndex === 2; // 之前节点为 abcd,所以c.index === 2
比较 oldIndex 与 lastPlacedIndex;
如果 oldIndex >= lastPlacedIndex 代表该可复用节点不需要移动
并将 lastPlacedIndex = oldIndex;
如果 oldIndex < lastplacedIndex 该可复用节点之前插入的位置索引小于这次更新需要插入的位置索引,代表该节点需要向右移动
在例子中,oldIndex 2 > lastPlacedIndex 0,
则 lastPlacedIndex = 2;
c节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:bd
// 当前newChildren:db
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
oldIndex 3 > lastPlacedIndex 2 // 之前节点为 abcd,所以d.index === 3
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:b
// 当前newChildren:b
key === b 在 oldFiber中存在
const oldIndex = b(之前).index;
oldIndex 1 < lastPlacedIndex 3 // 之前节点为 abcd,所以b.index === 1
则 b节点需要向右移动
===第二轮遍历结束===
最终acd 3个节点都没有移动,b节点被标记为移动
我们改一下案例,再分析一波
javascript// 之前
abcd
// 之后
dabc
===第一轮遍历开始===
d(之后)vs a(之前)
key改变,不能复用,跳出遍历
===第一轮遍历结束===
===第二轮遍历开始===
newChildren === dabc,没用完,不需要执行删除旧节点
oldFiber === abcd,没用完,不需要执行插入新节点
将剩余oldFiber(abcd)保存为map
继续遍历剩余newChildren
// 当前oldFiber:abcd
// 当前newChildren dabc
key === d 在 oldFiber中存在
const oldIndex = d(之前).index;
此时 oldIndex === 3; // 之前节点为 abcd,所以d.index === 3
比较 oldIndex 与 lastPlacedIndex;
oldIndex 3 > lastPlacedIndex 0
则 lastPlacedIndex = 3;
d节点位置不变
继续遍历剩余newChildren
// 当前oldFiber:abc
// 当前newChildren abc
key === a 在 oldFiber中存在
const oldIndex = a(之前).index; // 之前节点为 abcd,所以a.index === 0
此时 oldIndex === 0;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 0 < lastPlacedIndex 3
则 a节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:bc
// 当前newChildren bc
key === b 在 oldFiber中存在
const oldIndex = b(之前).index; // 之前节点为 abcd,所以b.index === 1
此时 oldIndex === 1;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 1 < lastPlacedIndex 3
则 b节点需要向右移动
继续遍历剩余newChildren
// 当前oldFiber:c
// 当前newChildren c
key === c 在 oldFiber中存在
const oldIndex = c(之前).index; // 之前节点为 abcd,所以c.index === 2
此时 oldIndex === 2;
比较 oldIndex 与 lastPlacedIndex;
oldIndex 2 < lastPlacedIndex 3
则 c节点需要向右移动
===第二轮遍历结束===
总结: 设置参照物,尽量减少节点从后面移动到前面的操作
Demo
typescript/**
* react diff
* 1. abcd -> acdb
* 2. abcd -> dabc
*/
export function diffChildren(newStr: string, oldStr: string): string[] {
// 第一轮循环 找出头部无变更的元素
let lastPlaceIndex = 0;
const result: string[] = [];
for (let i = 0; i < newStr.length; i++) {
if (newStr[i] && oldStr[i] && newStr[i] === oldStr[i]) {
lastPlaceIndex = i+1;
} else {
break;
}
}
if (
lastPlaceIndex === newStr.length &&
lastPlaceIndex === oldStr.length
) {
result.push("第一轮遍历结束,全部节点都可以复用");
return result;
}
if (lastPlaceIndex === oldStr.length) {
result.push("第一轮遍历结束, 新children有剩余");
result.push(`将剩余的新节点${newStr.slice(lastPlaceIndex)}插入尾部`);
return result;
}
if (lastPlaceIndex === newStr.length) {
result.push("第一轮遍历结束, 旧children有剩余");
result.push(`将剩余的新节点${oldStr.slice(lastPlaceIndex)}删除`);
return result;
}
result.push(`第一轮遍历结束新旧children都有剩余的情况`);
// 第二轮循环
const restOfOld = [...oldStr.slice(lastPlaceIndex)];
const [map, deletionsMap] = restOfOld.reduce(([map1, map2], item, index) => {
map1[item] = index + lastPlaceIndex;
const map2Index = index + lastPlaceIndex + '';
map2[map2Index] = true;
return [map1, map2];
}, [{}, {}] as [{[key: string]: number}, {[key: string]: boolean}]);
const restOfNew = [...newStr.slice(lastPlaceIndex)];
for (let j = 0; j < restOfNew.length; j++) {
const oldIndex = map[restOfNew[j]];
if(oldIndex !== undefined) {
deletionsMap[oldIndex] = false;
}
if(oldIndex === undefined) {
result.push(`将新元素${restOfNew[j]}插入到尾部`);
lastPlaceIndex = Math.max(oldStr.length, lastPlaceIndex) + 1;
} else if (oldIndex > lastPlaceIndex) {
lastPlaceIndex = oldIndex;
} else if (oldIndex < lastPlaceIndex) {
result.push(`将${restOfNew[j]}移动到尾部`);
}
}
Object.keys(deletionsMap)
.filter(index => deletionsMap[index])
.forEach(index => {
console.log(`删除${oldStr[index]}`)
result.push(`删除${oldStr[index]}`);
})
return result;
}
// diff.test.ts
import { diffChildren } from "./diff";
import { describe, it, expect } from "vitest";
describe("diffChildren", () => {
it("第一轮遍历结束,全部节点都可以复用", async () => {
const result = diffChildren('abcd', 'abcd');
console.log(result);
expect(result).toEqual(['第一轮遍历结束,全部节点都可以复用'])
});
it("第一轮遍历结束,新children有剩余", () => {
const result = diffChildren('abcd', 'abc');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束, 新children有剩余',
'将剩余的新节点d插入尾部'
])
})
it("第一轮遍历结束,旧children有剩余", () => {
const result = diffChildren('abc', 'abcd');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束, 旧children有剩余',
'将剩余的新节点d删除'
])
})
it("元素移动:abcd --> acdb", () => {
const result = diffChildren('acdb', 'abcd');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束新旧children都有剩余的情况',
'将b移动到尾部'
])
})
it("元素移动:abcd --> dabc", () => {
const result = diffChildren('dabc', 'abcd');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束新旧children都有剩余的情况',
"将a移动到尾部",
'将b移动到尾部',
'将c移动到尾部',
])
});
it("有元素移动和新增元素:abcd --> dabce", () => {
const result = diffChildren('dabce', 'abcd');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束新旧children都有剩余的情况',
"将a移动到尾部",
'将b移动到尾部',
'将c移动到尾部',
"将新元素e插入到尾部",
]);
});
it("有元素移动和新增元素:abcd --> daebc", () => {
const result = diffChildren('daebc', 'abcd');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束新旧children都有剩余的情况',
"将a移动到尾部",
"将新元素e插入到尾部",
'将b移动到尾部',
'将c移动到尾部',
]);
})
it("有元素移动和新增元素:abcd --> dac", () => {
const result = diffChildren('dac', 'abcd');
console.log(result);
expect(result).toEqual([
'第一轮遍历结束新旧children都有剩余的情况',
"将a移动到尾部",
'将c移动到尾部',
'删除b',
]);
});
});
状态更新
在react里,触发状态更新的操作包括:
- ReactDOM.render
- this.setState
- this.forceUpdate
- useState
- useReducer
Q:如何在调用场景不同的情况下,接入同一套状态管理机制?
在每次状态更新,都会创建保存一个更新状态相关的对象,称为Update,在render的beginwork中会根据Update得到新的state

Update思路 可类比代码版本控制类比
Update与Fiber联系:
- Fiber节点上的多个Update会组成链表并被包含在fiber.updateQueue中
- Fiber节点最多同时存在两个updateQueue:current fiber/workInProgress fiber
updateQueue
javascriptconst queue: UpdateQueue<State> = {
baseState: fiber.memoizedState,
firstBaseUpdate: null,
lastBaseUpdate: null,
shared: {
pending: null,
},
effects: null,
};
- baseState:本次更新前该Fiber节点的state,Update基于该state计算更新后的state,可以将baseState类比心智模型中的master分支;
- firstBaseUpdate与lastBaseUpdate:本次更新前该Fiber节点已保存的Update。以链表形式存在,链表头为firstBaseUpdate,链表尾为lastBaseUpdate。之所以在更新产生前该Fiber节点内就存在Update,是由于某些Update优先级较低所以在上次render阶段由Update计算state时被跳过,可以将baseUpdate类比心智模型中执行git rebase基于的commit(节点D);
- shared.pending:触发更新时,产生的Update会保存在shared.pending中形成单向环状链表。当由Update计算state时这个环会被剪开并连接在lastBaseUpdate后面,可以将shared.pending类比心智模型中本次需要提交的commit(节点ABC)。
- effects:数组。保存update.callback !== null的Update;
Q:render阶段可能会被中断,如何保证updateQueue中的Update不会丢失?
在render阶段,shared.pending的环被剪开并连接在updateQueue.lastBaseUpdate后面。
实际上shared.pending会被同时连接在workInProgress updateQueue.lastBaseUpdate与current updateQueue.lastBaseUpdate后面。
当render阶段被中断后重新开始时,会基于current updateQueue克隆出workInProgress updateQueue。由于current updateQueue.lastBaseUpdate已经保存了上一次的Update,所以不会丢失
当commit阶段完成渲染,由于workInProgress updateQueue.lastBaseUpdate中保存了上一次的Update,所以 workInProgress Fiber树变成current Fiber树后也不会造成Update丢失
Concurrent Mode
架构运行策略--lane
基于当前的架构,当一次更新在运行过程中被中断,过段时间再继续运行,这就是“异步可中断的更新”;
当一次更新在运行过程中被中断,转而重新开始一次新的更新,我们可以说:后一次更新打断了前一次更新;
这就是优先级的概念:后一次更新的优先级更高,就会打断正在进行的前一次更新。
多个优先级之间如何互相打断?优先级能否升降?本次更新应该赋予什么优先级?
这就需要一个模型控制不同优先级之间的关系与行为,也就是lane
时间切片原理 时间切片的本质是模拟实现requestIdleCallback(opens new window) 除去“浏览器重排/重绘”,下图是浏览器一帧中可以用于执行JS的时机。 一个task(宏任务) -- 队列中全部job(微任务) -- requestAnimationFrame -- 浏览器重排/重绘 -- requestIdleCallback
Scheduler的时间切片功能是通过task(宏任务)实现的。
- setTimeout:最常见
- MessageChannel:执行时机比setTimeout更早
所以Scheduler将需要被执行的回调函数作为MessageChannel的回调执行。如果当前宿主环境不支持MessageChannel,则使用setTimeout 在React的render阶段,开启Concurrent Mode时,每次遍历前,都会通过Scheduler提供的shouldYield方法判断是否需要中断遍历,使浏览器有时间渲染:
手写simple react
https://pomb.us/build-your-own-react/ 笔者建议 多写多练
TODO
- scheduler中使用了小顶堆
- 调度实现使用了messageChannel
- 在render阶段的reconciler中使用了fiber、update、链表这几种数据结构
- lane模型使用了二进制掩码
为什么条件语句里面不能写hooks?
- 如果我们写个多个hooks会创建一个链表, 如果hooks放在条件中,这些链表的顺序就可能不对了
legacy模式 与 concurrent模式的差异
legacy模式 使用ReactDOM.render()创建的应用 并发模式concurrent 使用ReactDOM.createRoot().render()创建的应用
- legacy模式下 useLayoutEffect与useEffect的差异
- 高优先级任务插队在两种模式下的差异
- setState差异
本文作者:郭敬文
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!