目录
本文将讲述DNS协议、DHCP协议、HTTP协议、Websocket协议。其中HTTP协议将以进化史的角度带你快速理解HTTP的发展与演化,同时深入分析HTTPS是如何设计的来解决网络安全问题。
应用层是面向用户的一层
| FTP | HTTP | HTTPS | DNS | TELNET(远程登录协议) | SMTP(邮件传送协议) | POP3协议(邮局协议) |
|---|---|---|---|---|---|---|
| 21 | 80 | 443 | 53 | 23 | 25 | 110 |
DNS协议
- IP是网络设备的地址,但是对于一串没有规律的数字,人类难以记忆。
- DNS(域名系统)解决IP地址复杂难以记忆的问题,存储并完成自己所管辖范围内主机的 域名 到 IP 地址的映射。
域名解析的顺序:
- 浏览器缓存,
- 先找到本机的hosts文件
- 路由缓存
- 找到DNS服务器(本地域名、顶级域名、根域名) --> 迭代解析、递归查询
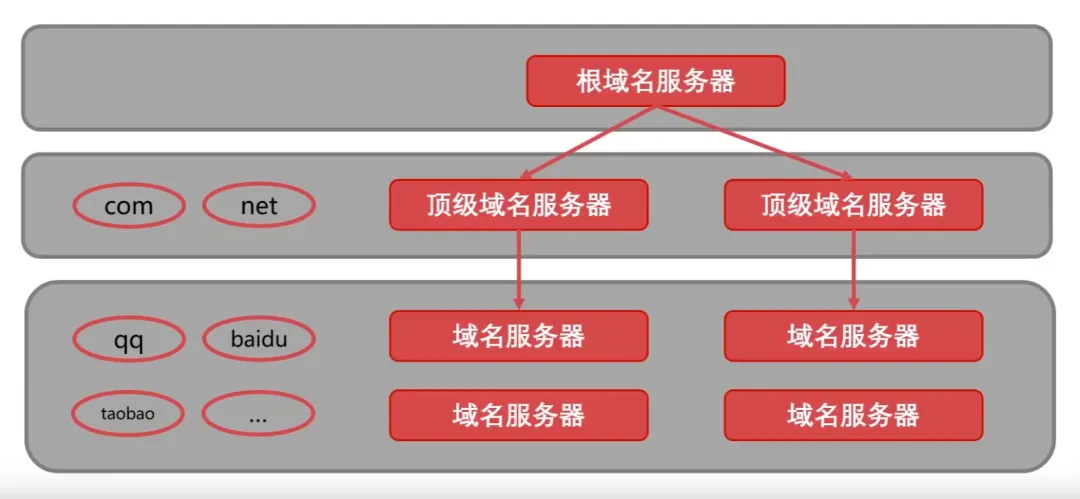
DNS查询方式
具体 DNS 查询的方式有两种
- 递归查询
- 如果请求者不知道所请求的内容,那么接收者将扮演请求者,发出有关请求,直到获得所需要的内容,然后将内容返回给最初的请求者。
- 通俗点来说 如果 A 请求 B,那么 B 一定会给A想要的答案
- 迭代查询
- 如果接收者 B 没有请求者 A 所需要的准确内容,接收者 B 将告诉请求者 A,如何去获得这个内容,但是自己并不去发出请求。
| - | 图示 | 描述 |
|---|---|---|
| 递归查询 | 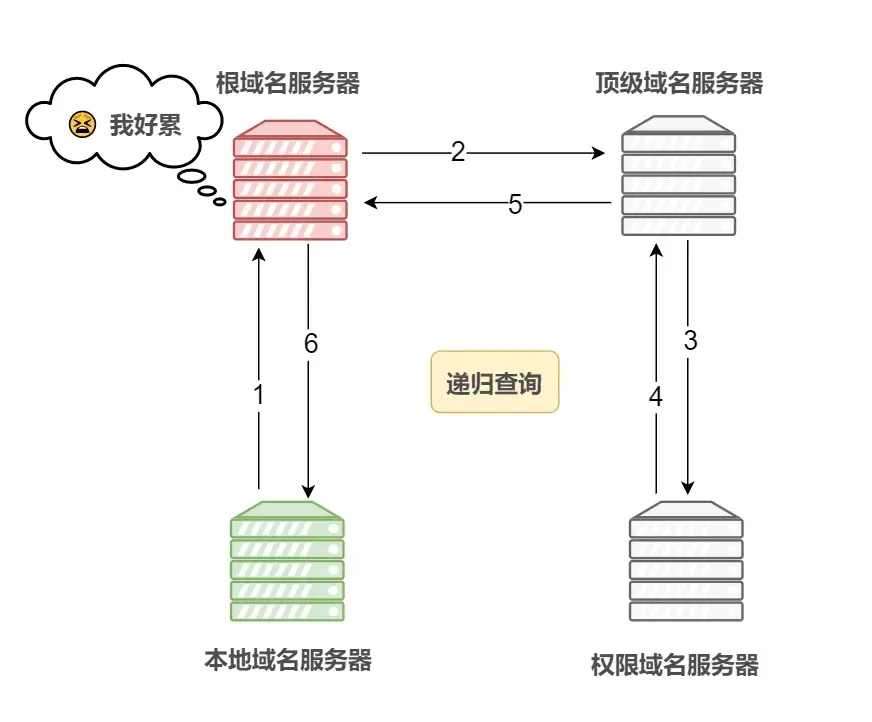 | 如果请求者不知道所请求的内容,那么接收者将扮演请求者,发出有关请求,直到获得所需要的内容,然后将内容返回给最初的请求者。 |
| 迭代查询 | 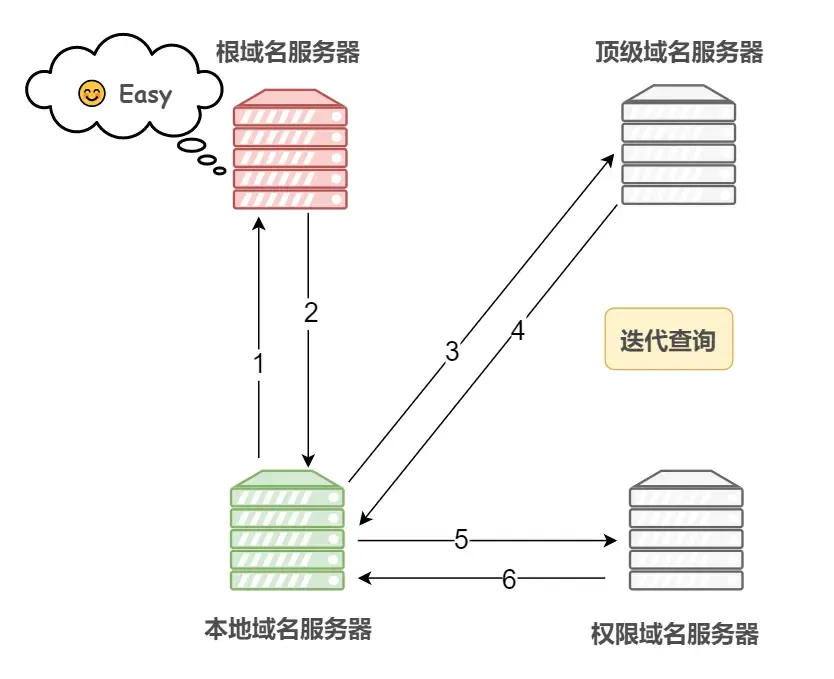 | 如果接收者 B 没有请求者 A 所需要的准确内容,接收者 B 将告诉请求者 A,如何去获得这个内容,但是自己并不去发出请求。 |
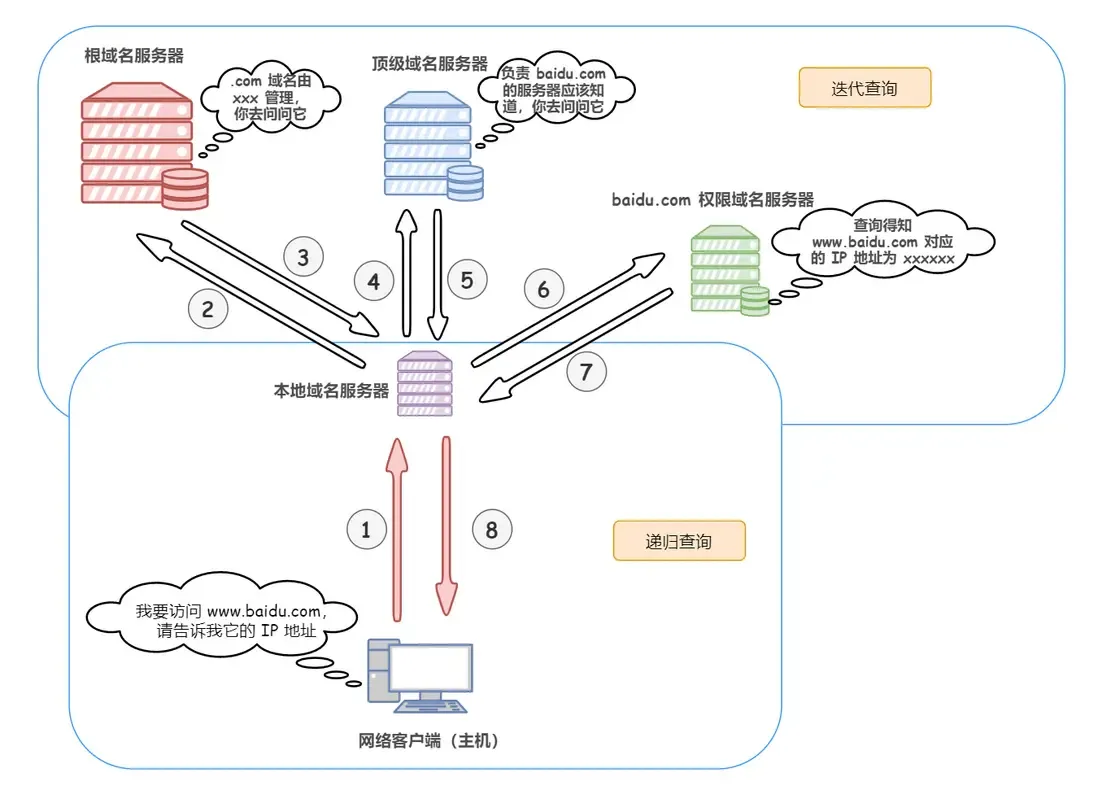
- 一般来说,域名服务器之间的查询使用迭代查询方式,以免根域名服务器的压力过大。
- 主机和本地域名服务器之间的查询方式是递归查询 这样可以让本地域名服务器更好的缓存
域名缓存
计算机中 DNS 记录在本地有两种缓存方式:浏览器缓存和操作系统缓存。
- 浏览器缓存
- 操作系统缓存
- 使用命令
ipconfig/displaydns可以查看电脑中缓存的域名。
- 使用命令
DHCP协议
我们有一台电脑, 在家的时候自动连接家里的wifi,在公司的时候自动连接公司wifi 并分配IP地址 这里就多亏了DHCP协议。
- DHCP(Dynamic Host Configuration Protocol: 动态主机设置协议)
- 它是一个局域网协议
- 它是应用UDP协议的应用层协议,采用67(DHCP服务器端)和68(DHCP客户端)两个端口号
DHCP指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址,子网掩码,Gateway地址、DNS服务器地址等信息,并能够提升地址的使用率
获取IP的方式有两种
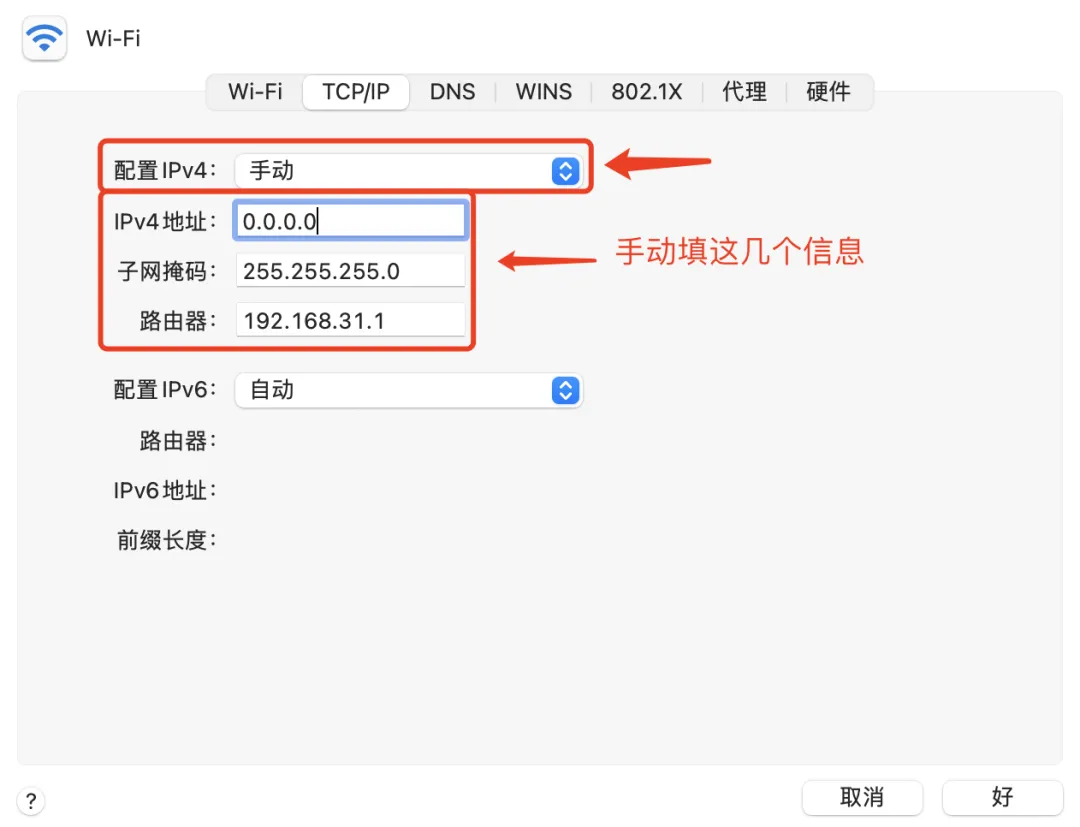
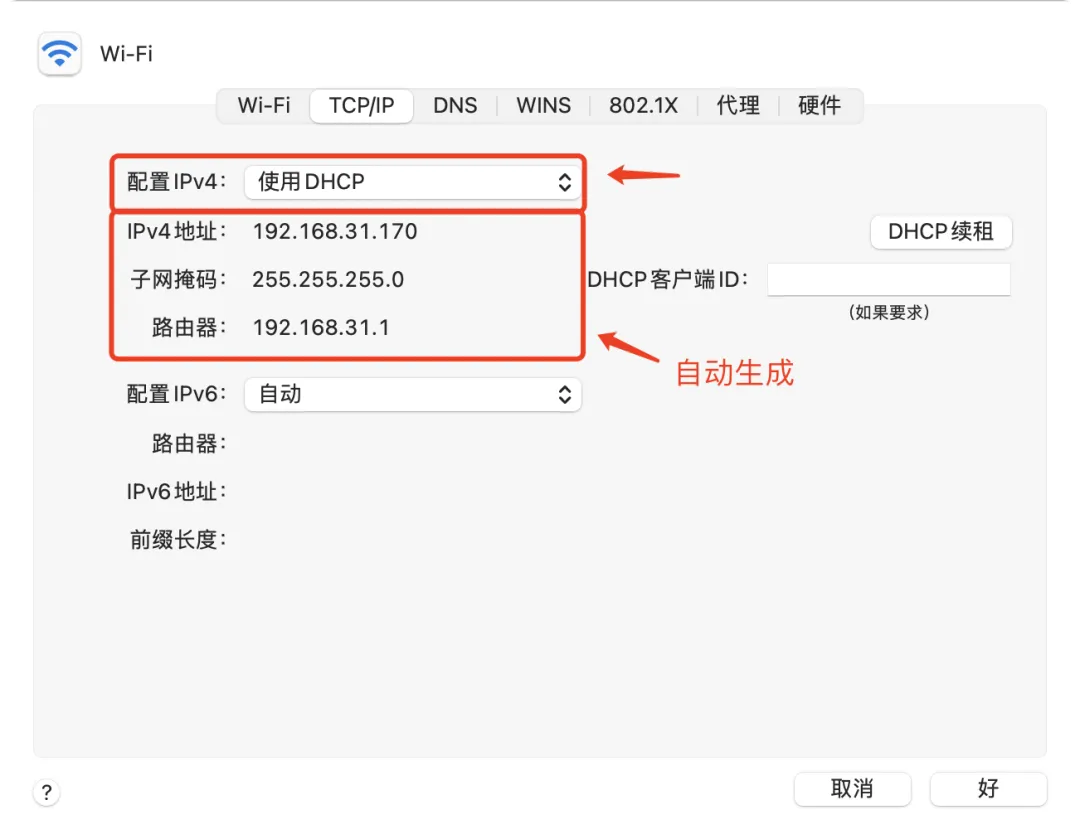
- 配置静态IP地址
- 使用DHCP协议
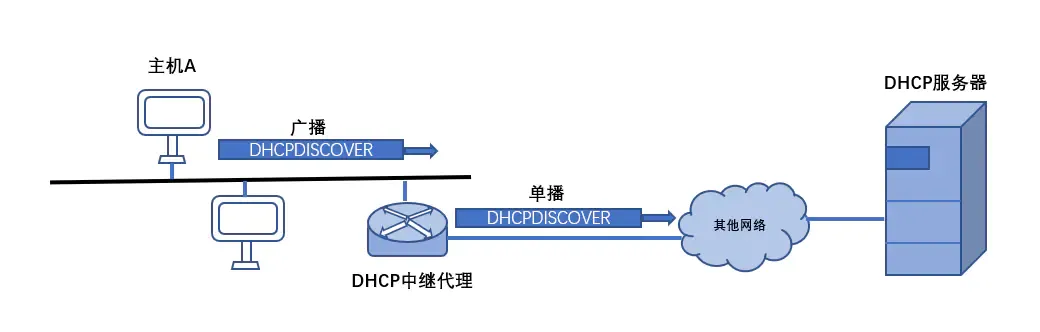
DHCP交互过程
- 第一步:Client端在局域网内发起一个DHCP Discover包,目的是想发现能够给它提供IP的DHCP Server。
- 第二步:可用的DHCP Server接收到DHCP Discover包之后,通过发送DHCP Offer包给予Client端应答,意在告诉DHCP Client端它可以提供IP地址。
- 第三步:DHCP Client端接收到DHCP Offer包之后,发送DHCP Request包请求分配IP。
- 第四步:DHCP Server发送DHCP ACK数据包,确认信息。

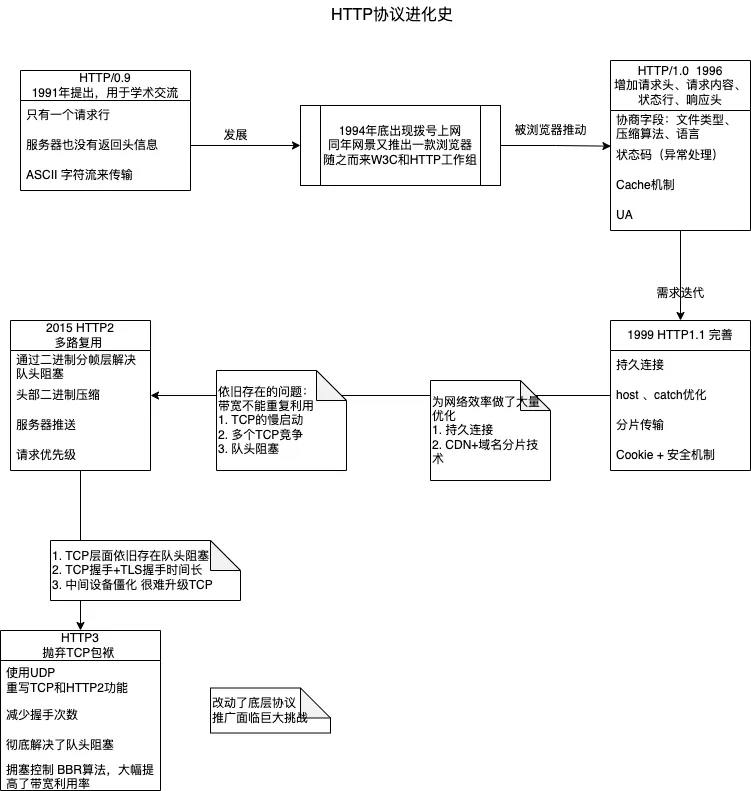
HTTP协议进化史
什么是HTTP协议?
- HTTP是超文本传输协议,从www浏览器传输到本地浏览器的一种传输协议,网站是基于HTTP协议的,例如网站的图片、CSS、JS等都是基于 HTTP协议进行传输的。
- HTTP协议是由从客户机到服务器的请求(Request)和从服务器到客户机的响应(response)进行约束和规范
发展史
- HTTP/0.9 1991
- HTTP/1.0 1996
- HTTP/1.1 1999
- HTTP/2 2015
HTTP/0.9
- HTTP/0.9 是于 1991 年提出的,主要用于学术交流,需求很简单——用来在网络之间传递 HTML 超文本的内容,所以被称为超文本传输协议。
- 整体来看,它的实现也很简单,采用了基于请求响应的模式,从客户端发出请求,服务器返回数据。
请求流程:
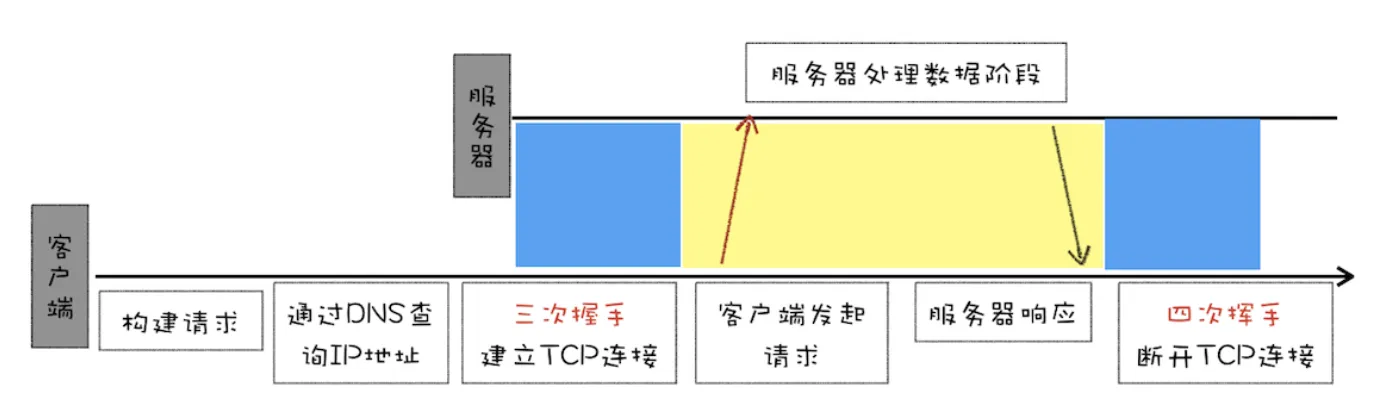
总的来说,当时的需求很简单,就是用来传输体积很小的 HTML 文件,所以 HTTP/0.9 的实现有以下三个特点。
- 只有一个请求行,并没有HTTP 请求头和请求体,因为只需要一个请求行就可以完整表达客户端的需求了
- 服务器也没有返回头信息,这是因为服务器端并不需要告诉客户端太多信息,只需要返回数据就可以了
- 文件内容是以 ASCII 字符流来传输的,因为都是 HTML 格式的文件,所以使用 ASCII 字节码来传输是最合适的。
被浏览器推动的 HTTP/1.0
1994 年底出现了拨号上网服务,同年网景又推出一款浏览器, 从此万维网就不局限于学术交流了,而是进入了高速的发展阶段。随之而来的是万维网联盟(W3C)和 HTTP工作组(HTTP-WG)的创建,它们致力于 HTML 的发展和 HTTP 的改进。
万维网的高速发展带来了很多新的需求,而 HTTP/0.9 已经不能适用新兴网络的发展,所以这时就需要一个新的协议来支撑新兴网络,这就是 HTTP/1.0 诞生的原因。
新的需求
- 支持多种类型的文件 浏览器中展示的不单是 HTML 文件了,还包括了 JavaScript、CSS、图片、音频、视频等不同类型的文件。
- 支持其他类型编码 文件格式不仅仅局限于 ASCII 编码,还有很多其他类型编码的文件。
为了解决新功能引入了请求头和响应头,它们都是以为 Key-Value 形式保存的,在 HTTP 发送请求时,会带上请求头信息,服务器返回数据时,会先返回响应头信息。
具体的请求流程
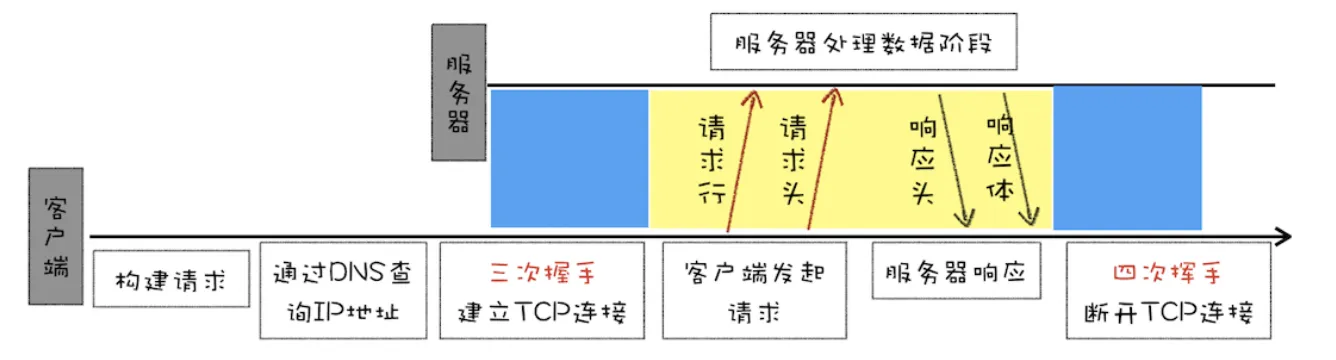
HTTP/1.0 的方案是通过请求头和响应头来进行协商。
请求头
accept: text/html期待服务器返回html类型的文件accept-encoding: gzip, deflate, br期待服务器可以采用的压缩算法accept-Charset: ISO-8859-1,utf-8期待服务器返回文件的具体编码accept-language: zh-CN,zh告诉服务器它想要什么语言版本的页面
响应头
content-encoding: brcontent-type: text/html;charset=UTF-8
除此之外还有一些问题要解决
- 有的请求服务器可能无法处理,或者处理出错,这时候就需要告诉浏览器服务器最终处理该请求的情况,这就引入了状态码
- 为了减轻服务器的压力,在 HTTP/1.0 中提供了Cache 机制,用来缓存已经下载过的数据。
- 服务器需要统计客户端的基础信息,比如 Windows 和 macOS 的用户数量分别是多少,所以 HTTP/1.0 的请求头中还加入了用户代理的字段。
缝缝补补的 HTTP/1.1
随着技术的继续发展,需求也在不断迭代更新,很快 HTTP/1.0 也不能满足需求了,所以 HTTP/1.1 又在 HTTP/1.0 的基础之上做了大量的更新。
- 持久连接
- host字段
- 支持分块传输 Chunk transfer 机制
- 客户端 Cookie、安全机制
- 缓存机制
改进持久连接 HTTP/1.0 每进行一次 HTTP 通信,都需要经历建立 TCP 连接、传输 HTTP 数据和断开TCP 连接三个阶段
为了解决这个问题,HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。
持久连接在 HTTP/1.1 中是默认开启的,所以你不需要专门为了持久连接去 HTTP 请求头设置信息,如果你不想要采用持久连接,可以在 HTTP 请求头中加上Connection: close。目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接。
我们知道 HTTP/1.1 为网络效率做了大量的优化,最核心的有如下三种方式:
- 增加了持久连接
- 浏览器为每个域名最多同时维护6个TCP持久连接;
- 使用CDN实现域名分片技术
- 下载100个资源的时间缩短为 100/6/cdn个数
HTTP1.1的问题
这些优化资源加载策略,也取得了一定的效果,但是HTTP1.1对带宽的利用率却并不理想 比如100M的带宽,实际下载速度12.5M/s 采用HTTP/1.1时,或许最大能使用到2.5M/S,很难将12.5M全部用满
主要有以下三个问题
- TCP的慢启动
- 开启多条TCP连接这些连接也会竞争固定的带宽
- HTTP/1.1队头阻塞的问题
队头阻塞
TCP的队头阻塞
- 因为TCP时基于字节流传输的,一个HTTP请求或响应被分在多个tcp报文中,也可能一个tcp包含含有两个http请求或响应的片段
- 如果发生丢包后续报文只能缓存下来,不能继续处理交给应用层,必须等到选择重传确认后才能接着处理, 这就是队头阻塞
HTTP1.1的队头阻塞
- 每个域名开启6个TCP连接
- 那么该域名下的第七个请求就没放到某一个TCP管道中了, 必须等待前一个请求解析完成,才能解析当前请求。
队头阻塞的因素很多,一个请求被阻塞5s,后续的每个请求都延迟了5s,这是很严重的问题。
HTTP2多路复用提升网络速度
如何解决HTTP1.1无法充分利用带宽的能力呢?
首先慢启动和TCP连接之间相互竞争带宽 是TCP本身机制所决定的,我们没有换掉TCP的能力, 而队头阻塞是http/1.1机制导致的,这个可以优化。
HTTP/2的思路是
- 一个域名只使用一个TCP长连接来传输数据,这个整个资源下载的过程只有一次慢启动,同时也避开了TCP连接竞争带宽的问题。
- 另外队头阻塞问题,HTTP/2需要实现资源的并行请求,任何时候都可以发送和接收数据即传输中无序,接收时组装
多路复用
HTTP2引入了二进制分帧层,
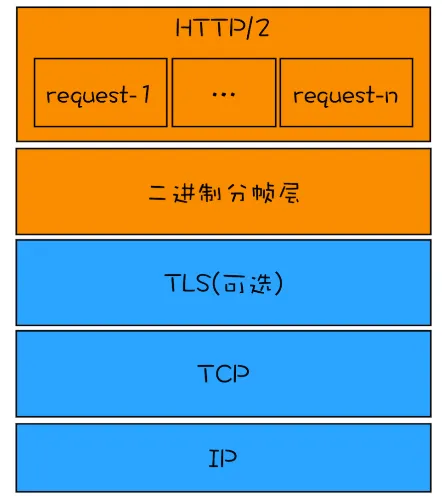
- 首先浏览器准备好请求数据(请求行、请求头、请求体)
- 经过二进制分帧层的处理,会被转换为一个个带有请求ID编号的帧,通过协议栈将这些帧发送给服务器
- 服务器接收到所有帧后,会将相同ID的帧合并为一条完整的请求信息。
- 然后服务器处理该条请求,将响应内容发送至二进制分帧层。
- 同样过程,这是这次是浏览器合并相同ID的帧了。
多路复用 流、消息、帧之间的关系
- 一个TCP连接包含多个流
- 数据流:双向通信的数据流,包含一条或者多条消息
- 消息: 对应http1.1中的请求或响应
- 数据帧:最小单位, 以二进制压缩格式存放HTTP/1中的内容,一个消息由一个或多个帧组成 注意: 消息在流中的必须有序, 在不同的流中可以无需
总结
- 一个域名一个TCP连接,一个连接上可以并行交错的请求和响应,之间互不干扰
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送因为根据帧首部的流标志可以重新组装。
虽然HTTP/2引入了二进制分帧层,但是语义与1.1依然一样的(可以将不支持2的代理服务器降级为1.1处理),复用TCP协议,推广起来会更轻松
如何理解HTTP/2解决队头阻塞
- HTTP/2只是解决了HTTP/1层面的队头阻塞,但是TCP层面仍旧存在队头阻塞
- HTTP/1.1队头阻塞, 如果前一个请求因某个tcp报未收到,即使接下来的一个或多个报文已经响应,这些报文是完整当前请求或响应的内容,由于TCP没有交付应用层所以应用层不能处理。
- 不同的消息放到不同的流中,不同流之间可以乱序传输,这就解决了http/1.1的队头阻塞的问题
其他功能
- 二进制分帧层有个优先级字段(31bit, 0最高优先级) 这样就可以设置请求优先级
- 服务器推送 当收到html请求,会分析页面将会使用的CSS/JS 资源,提前推送过去
- 头部压缩 (对于内容进行静态编码、动态编码、Huffman编码)
- 静态编码 比如请求头字段
:method: GET用2表示就行了 - 动态编码 key使用静态编码, value使用 huffman编码
- huffman编码 根据字符频率组成最大二叉树,用01路径表示编码,这样高频字符用短编码表示
- 效果,相似请求越多压缩越明显
- 静态编码 比如请求头字段
延伸:
- HTTP2的前身是SPDY
- HTTP2有两种实现方式
- h2 基于TSL协议运行的HTTP2 如nginx
listen 443 ssl http2; - h2c 直接在TCP协议运行的HTTP2
Upgrade: h2c
- h2 基于TSL协议运行的HTTP2 如nginx
HTTP3抛弃TCP包袱
- 因为HTTP2只是解决了HTTP1的队头阻塞问题,TCP层面还是存在队头阻塞问题。
- TCP握手+TLS握手 需要花费3-4个RTT
- 由于中间设备僵化问题 很难通过改进TCP协议来解决这些问题
中间设备僵化
- 我们知道互联网是由多个网络互联的网状结构,为了能够保障互联网的正常工作,我们 需要在互联网的各处搭建各种设备,这些设备就被称为中间设备。
- 这些中间设备有很多种类型,并且每种设备都有自己的目的,这些设备包括了路由器、防火墙、NAT、交换机等。它们通常依赖一些很少升级的软件,这些软件使用了大量的 TCP 特性,这些功能被设置之后就很少更新了。
- 所以,如果我们在客户端升级了 TCP 协议,但是当新协议的数据包经过这些中间设备时, 它们可能不理解包的内容,于是这些数据就会被丢弃掉。这就是中间设备僵化,它是阻碍 TCP 更新的一大障碍。
- 除了中间设备僵化外,操作系统也是导致 TCP 协议僵化的另外一个原因。因为 TCP 协议都是通过操作系统内核来实现的,应用程序只能使用不能修改。通常操作系统的更新都滞后于软件的更新,因此要想自由地更新内核中的 TCP 协议也是非常困难的。
为了解决上述三个问题, HTTP3 决定重塑 TCP功能(握手、拥塞控制、丢包重传机制)及HTTP2功能(多路复用)解决队头阻塞问题
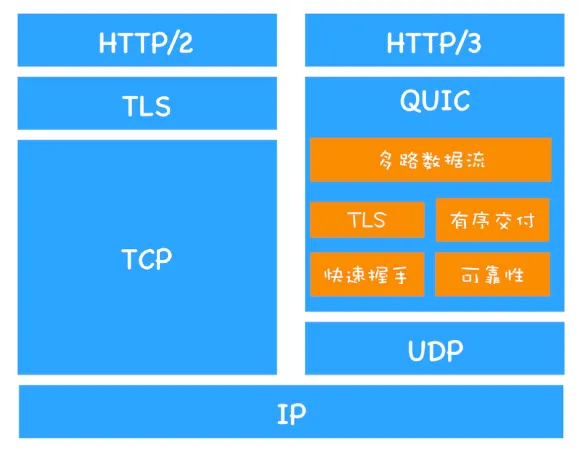
拥塞控制方面,
- TCP使用慢启动、拥塞避免、快重传、快恢复的算法
- QUIC协议使用google 的BBR算法(测量带宽)大幅提升了带宽的利用率
握手方面: 将TCP握手与TLS握手合并减少了握手次数.
队头阻塞: 借鉴HTTP2的多路复用功能。
虽说这套协议解决了 HTTP/2 中因 TCP 而带来的问题,不过由于是改动了底层协议,所以 推广起来还会面临着巨大的挑战。
总结
HTTPS协议如何设计
在学习HTTPS协议前需要先掌握加解密技术。
起初设计 HTTP 协议的目的很单纯,就是为了传输超文本文件,那时候也没有太强的加密传输的数据需求,所以 HTTP 一直保持着明文传输数据的特征。但这样的话,在传输过程中的每一个环节,数据都有可能被窃取或者篡改,这也意味着你和服务器之间还可能有个中间人,你们在通信过程中的一切内容都在中间人的掌握中,如下图:
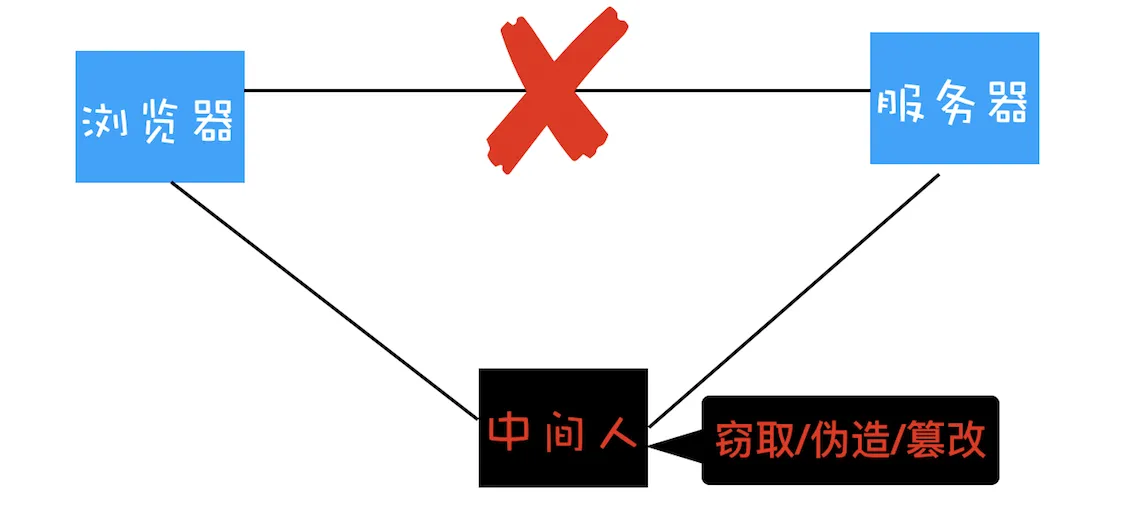
在 HTTP 协议栈中引入安全层
为了解决中间人劫持网络问题就必须使用加密方案
在 TCP 和 HTTP 之间插入一个安全层
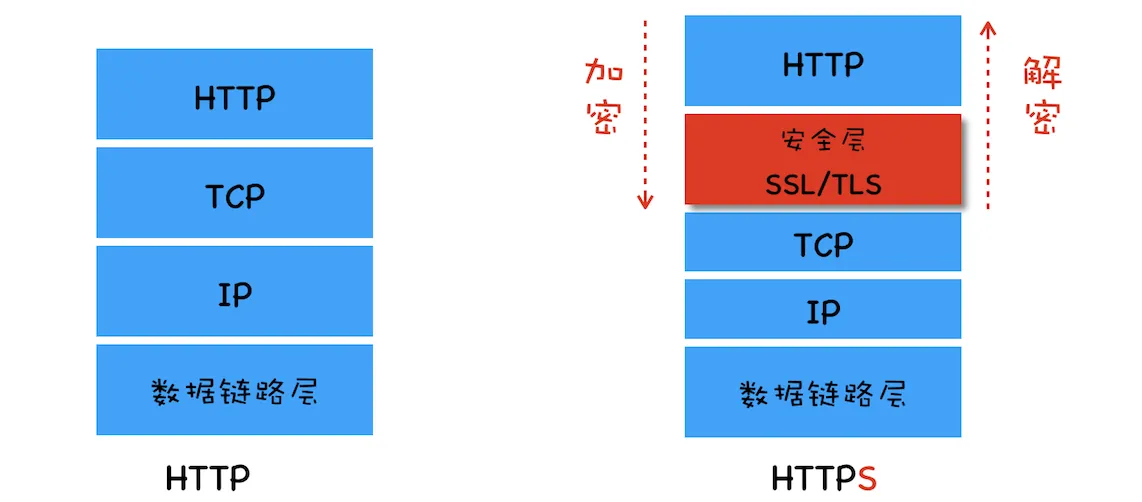
安全层有两个主要的职责:
- 对发起 HTTP 请求的数据进行加密操作
- 对接收到 HTTP 的内容进行解密操作。
设计思路
假如只使用对称加密
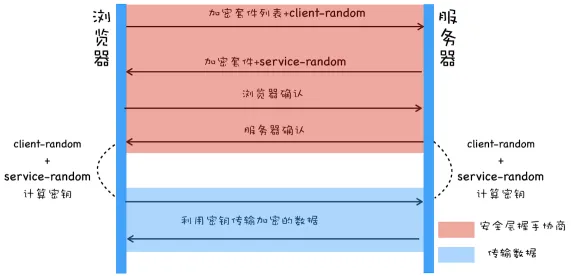
由于client-random、server-random、协商的加密套件是明文, 再加上公开的合成密钥算法就可以合成密钥,进而伪造和篡改数据
假如只使用非对称加密
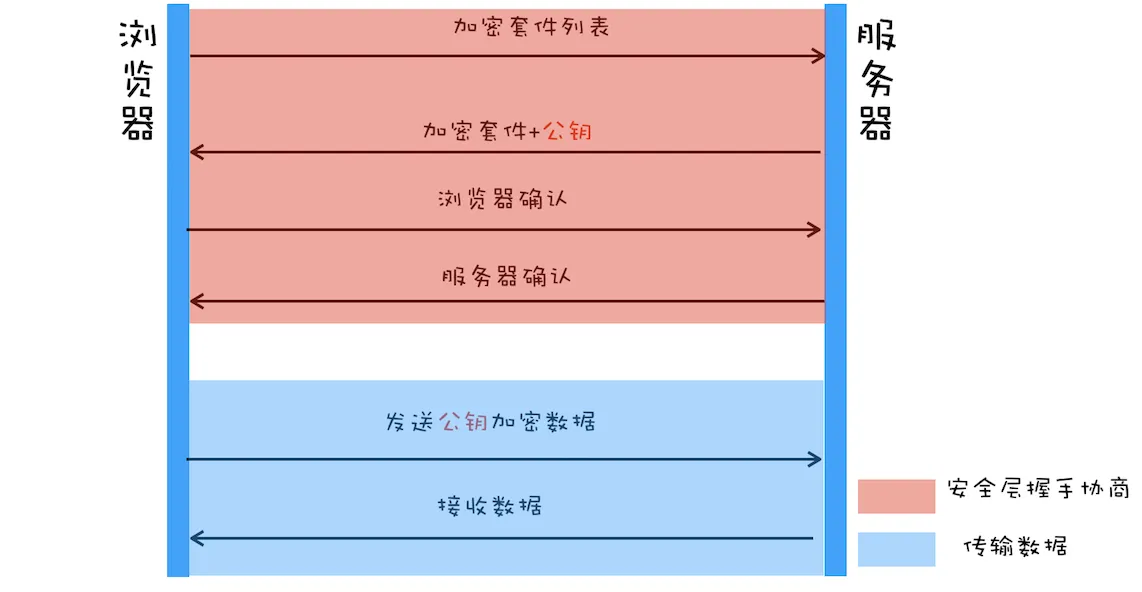
虽然使用非对称加密能保证浏览器发送给服务器的数据是安全的了,但是服务器发送的消息依旧存在被黑客解密的情况,因为公钥是公开的。
另外还有一个更严重的问题是 非对称加密效率太低!
对称加密和非对称加密搭配使用
先利用非对称加密计算出密钥,然后使用对称加密通信,这样解决了传输效率问题
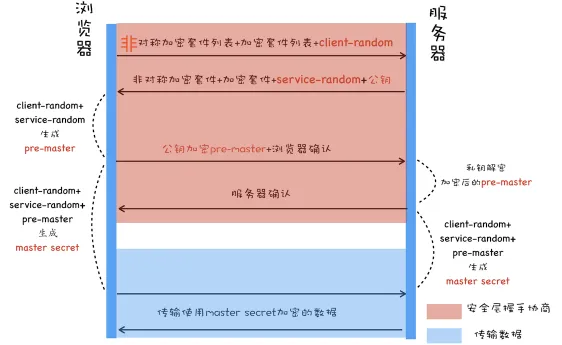
在DNS劫持的情况下,(伪造一个代理服务器作为中间人劫持),服务端发送的消息已经能被破解
引入数字证书
数字证书简单说就是第三方公证人,它能证明服务器是否为真,杜绝DNS劫持问题
- 网站拥有者 到CA机构 备案,CA机构颁发证书
- 备案信息有,网站域名、所有者、有效期签名等信息
- 颁发的证书包含 网站拥有者信息及hash签名 + 网站拥有者公钥
- 上述信息还要使用CA机构的私钥加密
- 客户端提前内置了合法的CA机构,所以CA机构不存在伪造问题
- 客户端拿到这个数字证书后,找CA机构验证网站是否合法,有效期,会得到 网站的公钥。
- 客户端使用前面沟通的两个随机数和这个公钥 合成pre-master, 服务端也会产生相同的pre-master,这个pre-master就是之后双方使用对称加密传输的密钥。
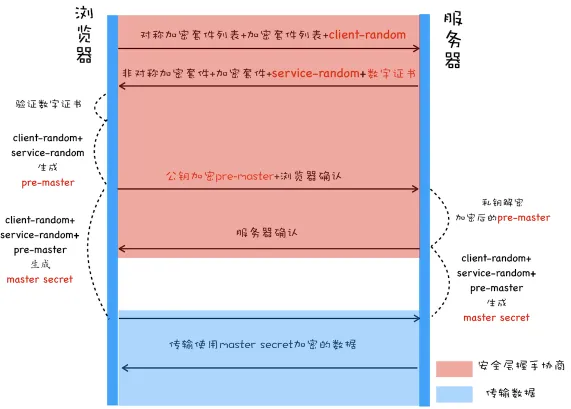
黑客能否合成这个pre-master呢? 如果黑客提前请求服务器,也会得到服务器的公钥,进而合成pre-master。
所以这里不是直接使用网站的公钥来合成pre-master,而是再产生一个随机数,加上之前的随机数合成pre-master,再使用这个公钥对这个随机数加密,由于黑客没有网站的私钥,所以无法合成pre-master,而网站服务器可能安全的合成pre-master,进而与客户端通信
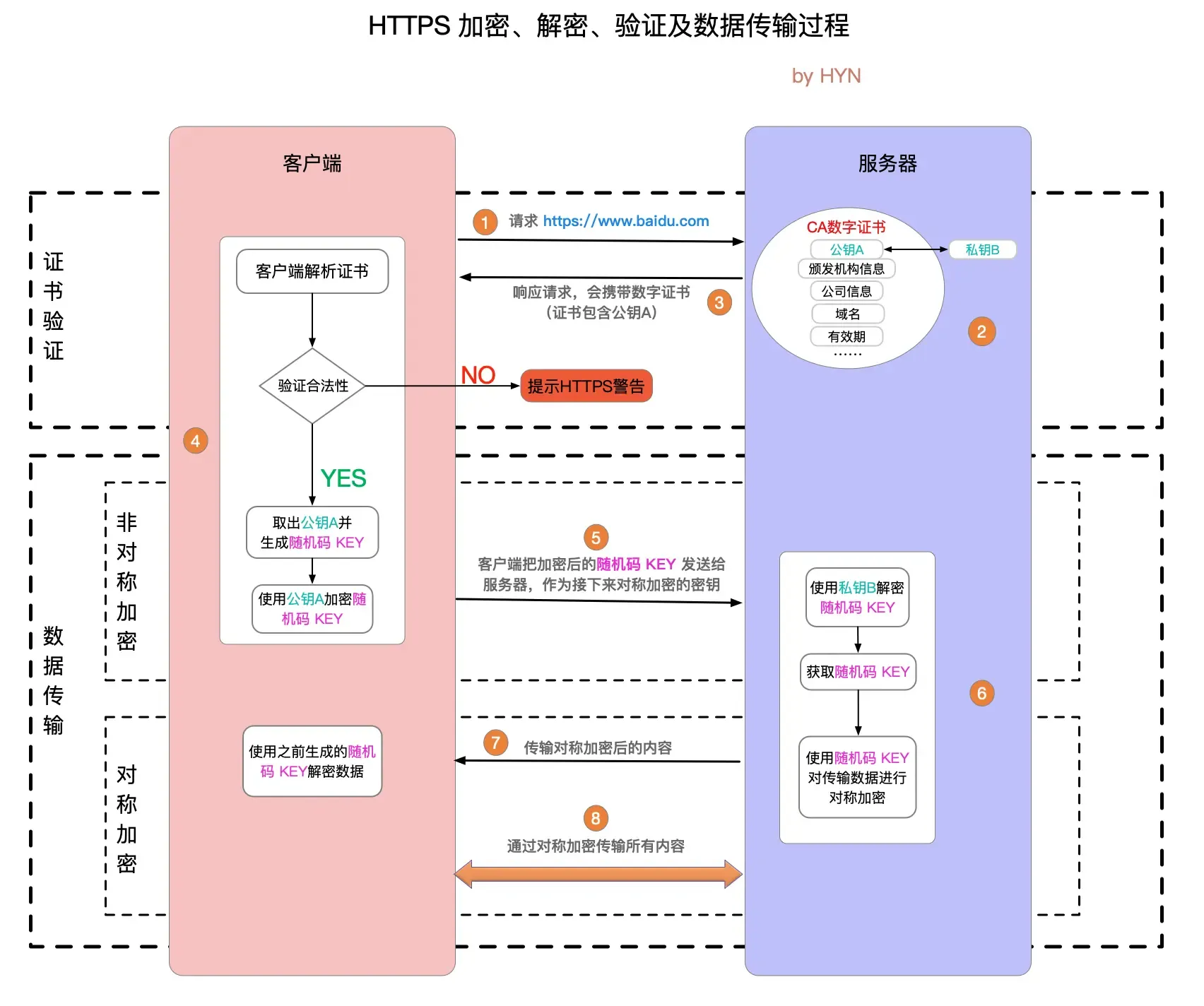
参考资料
注意:CA机构也分层级,有一个证书信任链关系,这样就能新网站的就很方便了。
其他:
- HTTPS协议的安全性由SSL协议实现,当前使用的TLS协议1.2版本包含了四个核心子协议: 握手协议、密钥配置切换协议、应用数据协议及报警协议。
- 关于密钥交换协议 请看我的另一篇文章《加密技术》
- 数字证书: 数字证书是互联网通信中标识双方身份信息的数字文件,由CA签发。
- CA: CA(certification authority)是数字证书的签发机构。作为权威机构,其审 核申请者身份后签发数字证书,这样我们只需要校验数字证书即可确定对方的真 实身份。
- HTTPS协议、SSL协议、TLS协议、握手协议的关系
- HTTPS是Hypertext Transfer Protocol over Secure Socket Layer的缩写,即 HTTP over SSL,可理解为基于SSL的HTTP协议。HTTPS协议安全是由SSL协议实现的。
- SSL协议是一种记录协议,扩展性良好,可以很方便的添加子协议,而握手协 议便是SSL协议的一个子协议。
- TLS协议是SSL协议的后续版本从1.3版本 TLS1.0是SSL3.0的改进版本
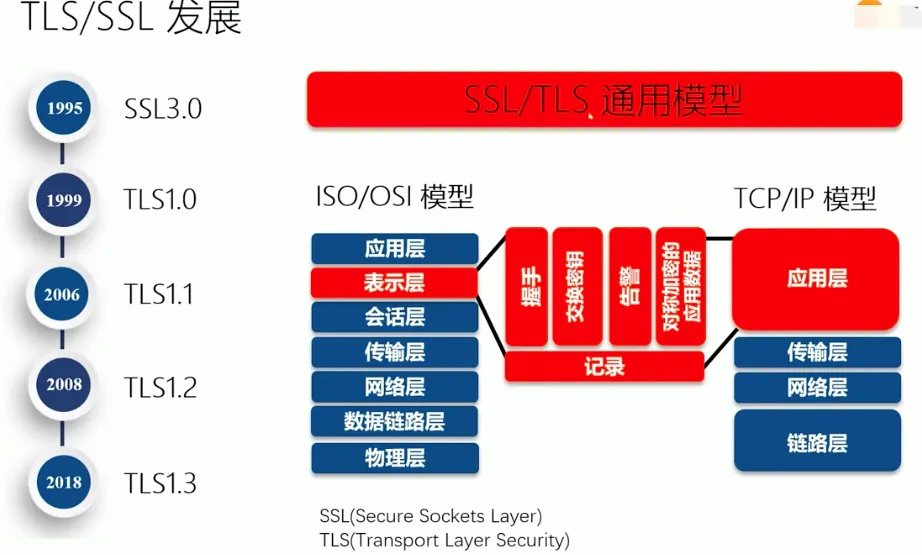
延伸:前面的内容知识为了快速理解HTTPS,完整的TLS协议要复杂很多,如下图,感兴趣的可以自行研究。
Websocket协议
为什么需要Websocket协议
在 WebSocket 出现之前,如果我们想实现实时通信,比较常采用的方式是 Ajax 轮询,即在特定时间间隔(比如每秒)由浏览器发出请求,服务器返回最新的数据。这种方式有一些缺陷
- 请求头浪费带宽 HTTP请求一般包含头部信息比较多,其中有效数据可能只占其中很小一部分,导致浪费带宽
- 服务器CPU占用 服务器被动接受浏览器请求后然后响应,数据没有更新仍要接受并处理请求,导致CPU占用。
Websocket内容
定义:Websocket是基于TCP的一种新的应用层协议,它实现了浏览器与服务器的全双工通信,即允许服务器主动发送信息给客户端。因为,在Websocket中浏览器和服务器只需要完成一次握手,两者就直接创建持久性的连接,并进行全双工数据传输,客户端与服务器之间的数据交换变得更加简单。
如何建立连接
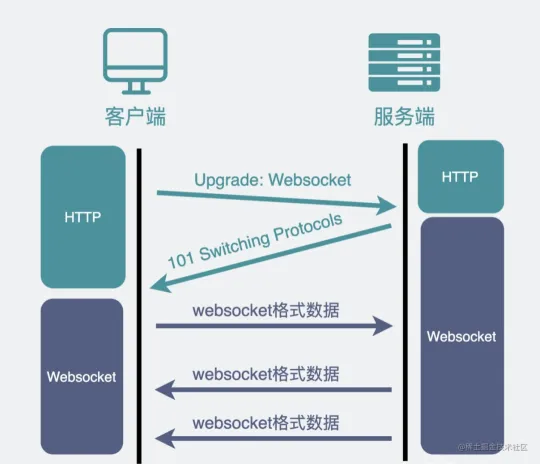
- Websocket复用HTTP协议的握手通道
- 然后协商升级协议(复用HTTP得Upgrade机制)
http# 请求头 Connection: Upgrade Upgrade: websocket Sec-Websocket-key: XXXXX # 服务端响应 HTTP/1.1 101 SwitchProtocals Connection: Upgrade Upgrade: websocket Sec-Websocket-Accept: YYY
Sec-Websocket-Accept 是由 Sec-Websocket-key加密得到的
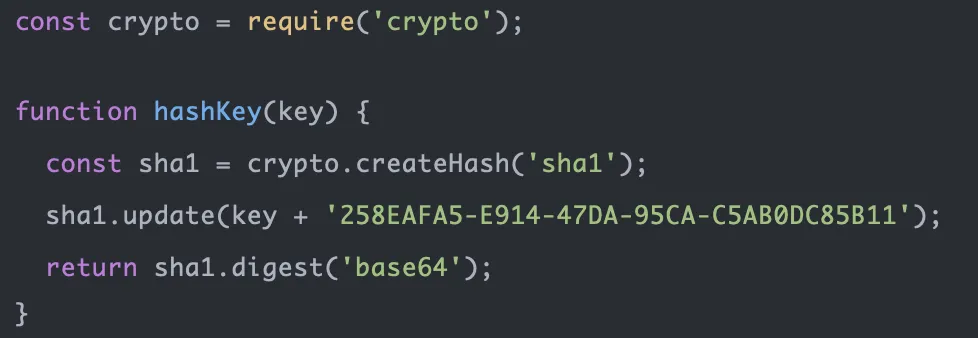 它有两个作用
它有两个作用
1) 用于确保服务器有Websocket的能力
2)它提供基本防护(恶意链接、无效连接)
经过以上两步就切换到一个全新的协议 websocket
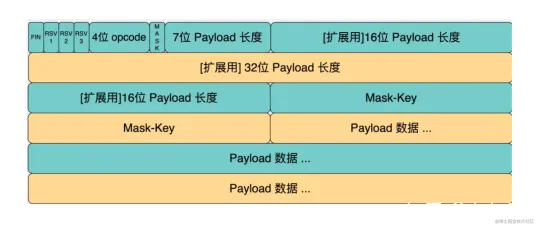
websocket 是二进制协议,一个字节可以存储更多信息。
利用HTTP完成握手有以下好处
- 让Websocket与HTTP基础设备兼容
- 可以复用HTTP的Upgrade机制,完成协议的协商升级
如何交换数据?
- Websocket 会将每条消息切分成多个数据帧(最小单位)。
- 发送端会将消息切割成多个帧发送给接收端
- 接收端接受消息帧,并将关联的帧重新组装成完成的消息。
readyState
- CONNECTING 正在连接中 0
- OPEN 已经连接并且可以通信 1
- CLOSING 连接正在关闭,对应的值为 2
- CLOSED 连接已经关闭或者没有连接成功 3
Websocket的特点
- 建立在TCP协议之上;
- 与HTTP协议有良好的兼容性;默认端口80(ws)和443 (wss,运行在TLS之上),并且握手采用HTTP协议
- 较小的控制开销 连接创建后,ws客户端、服务器进行数据交换时,协议控制的数据包头部较小,HTTP协议每次通信要携带完整的头部
- 支持文本二进制数据
- 没有同源限制
- 支持扩展: ws协议定义可扩展,用户可以扩展协议,或者自定义子协议
为什么webscocket没有同源限制
美团一面面试题: 2023年10月18日
CORS是浏览器限制的是HTTP响应头,浏览器不把响应的数据给到JS,而Websocket握手响应头被忽略,所以CORS策略无效。
因此攻击者可以视图建立跨源WS连接并发送恶意数据或从订阅的通道接收数据(即使服务器不响应 CORS 标头,如果服务器支持 WebSocket 并发送 101 切换协议状态,也会建立 WebSocket 连接)。 这类似于跨站请求伪造 (CSRF)。因此服务器实现应验证升级请求上的 Origin 标头,以防止跨站点 WS 连接。
jsconst io = require("socket.io")(httpServer, {
allowRequest: (req, callback) => {
const isOriginValid = check(req);
callback(null, isOriginValid);
}
});
参考资料: websocket绕过SOP/CORS
Websocket可以携带Cookie吗
Websocket 可以通过设置请求头中的 "Cookie" 字段来携带 cookie。代码实现取决于使用的编程语言和 websocket 库。例如,在 JavaScript 中,使用 WebSocket API 可以通过如下方式设置请求头并携带 cookie:
jsvar socket = new WebSocket('ws://example.com');
socket.onopen = function () {
socket.send('hello');
};
socket.setRequestHeader("Cookie", "cookiename=cookievalue");
注意:服务器必须允许 websocket 请求携带 cookie,否则请求将失败。
HTML5与Websocket
Websocket API 是 HTML5标准的一部分 但这并不代表 WebSocket 一定要用在 HTML 中,或者只能在基于浏览器的应用程序中使用。 实际上,许多语言、框架和服务器都提供了 WebSocket 支持,例如:
- 基于 C 的 libwebsocket.org
- 基于 Node.js 的 Socket.io
- 基于 Python 的 ws4py
- 基于 C++ 的 WebSocket++
- Apache 对 WebSocket 的支持:Apache Module mod_proxy_wstunnel
- Nginx 对 WebSockets 的支持:NGINX as a WebSockets Proxy 、 NGINX Announces Support for WebSocket Protocol 、WebSocket proxyin
不同的 socket框架 之间不能共用
- 如scoket.io, 客户端只能使用socket.io-client 而不能使用原生 websocket
- 服务端使用原生websocket 客户端也只能使用原生websocket
参考资料:
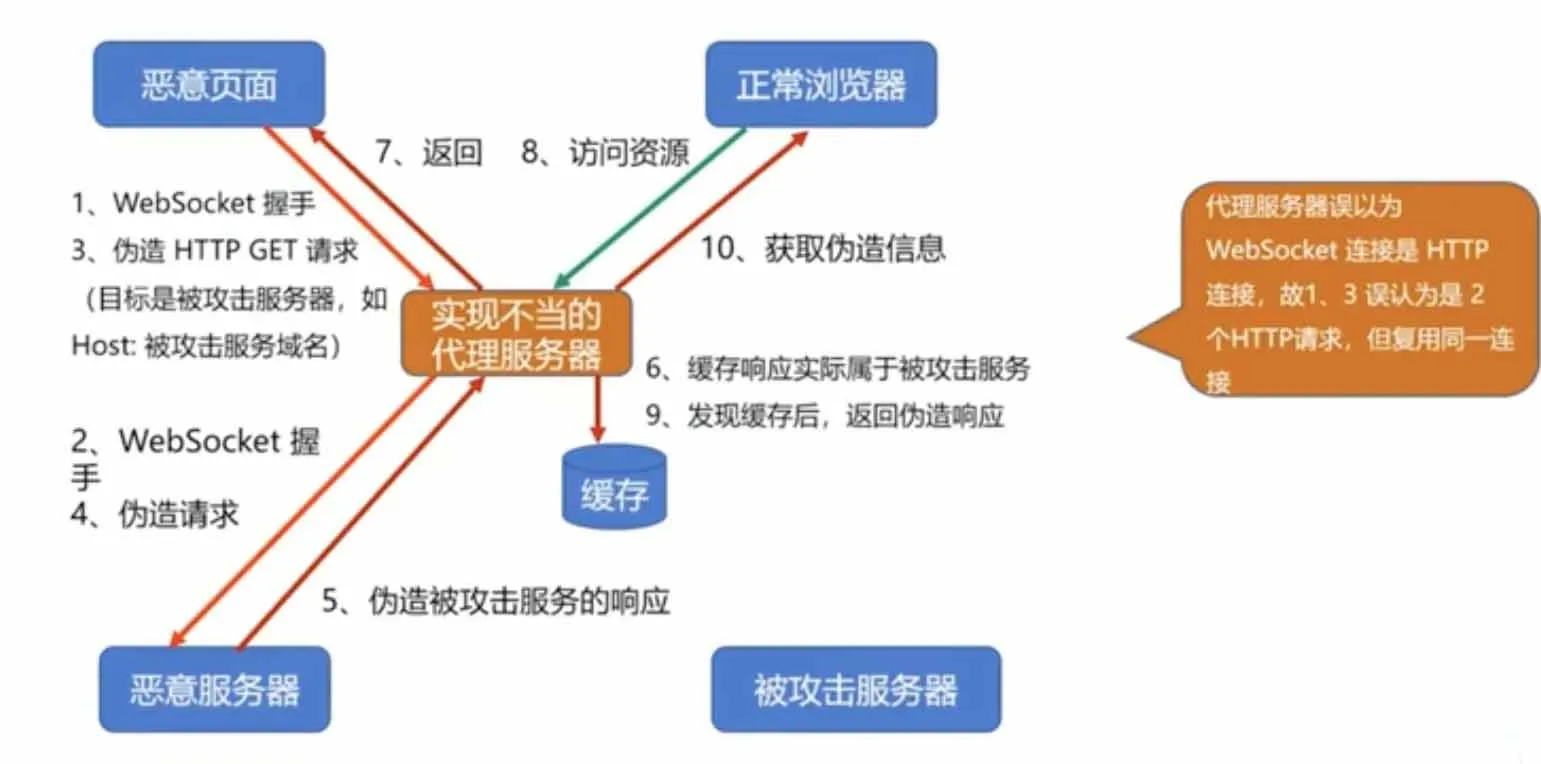
MaskKey的作用
websocket协议头部有个MaskKey,用来防止代理服务器的缓存污染攻击
它的原理是 强制浏览器执行以下方法:
- 生成随机的32位frame-masking-key,不能让JS代码透出(否则可以反向构造)
- 对传输的包体按照frame-making-key执行可对称解密的XOR异或操作,使代理服务器不识别
主要参考资料
- 极客时间--浏览器工作原理与实战
- 慕课网--编程必备基础-计算机组成原理+操作系统+计算机网络
- youtube--web协议详解与抓包实战
本文作者:郭敬文
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!