目录
我有一年多没怎么用AI相关的应用了,上一次系统调研AI是23年10月份,我写了一篇《ChatGPT深入总结》,那时候只调研了ChatGPT,虽然知道国内也有很多AI应用,但与ChatGPT的差距不是一点半点。而如今国内的大模型和国外的大模型已不相上下了,甚至某些方面有领先的趋势,而且OpenAI也不算遥遥领先了。大约一个半月之前Deepseek爆火,当时我在忙别的,最近花了不少时间调研各家的AI进展。本以为重点调研下Deepseek就行,然而却发现AI的进化远超我的想象!DeepSeek的性价比已经大幅提升了,但没想到一个月后的Gemma3再次领先,更没想到几天后的开源大模型Mistral Small 3.1 全面碾压Gemma3,甚至能在家用消费级的电脑上跑起来!能回答问题,能编程,能看片子!
下面的内容是我这些天调研的情况,以及我的思考。
- AI发展
- 这两年AI的发展
- DeepSeek事件
- DeepSeek技术报告
- AI目前的能力到哪一步了
- 大模型的研究方向(通用模型、可推理模型),AI大脑的进化(表现在高情商、展示思考过程)
- 文生图、文生视频方面,一方面AI性能在快速提升,另一方面生成的图片和视频质量也在显著提升。
- AI机器人的进展情况
- AI实用技巧
- AI编程
Github CopilotCursor编辑器
- 普通人如何应对?
内容很长,建议收藏起来,慢慢看。
DeepSeek Shock
大家还记得一个半月前震惊中外的AI大事件吗?
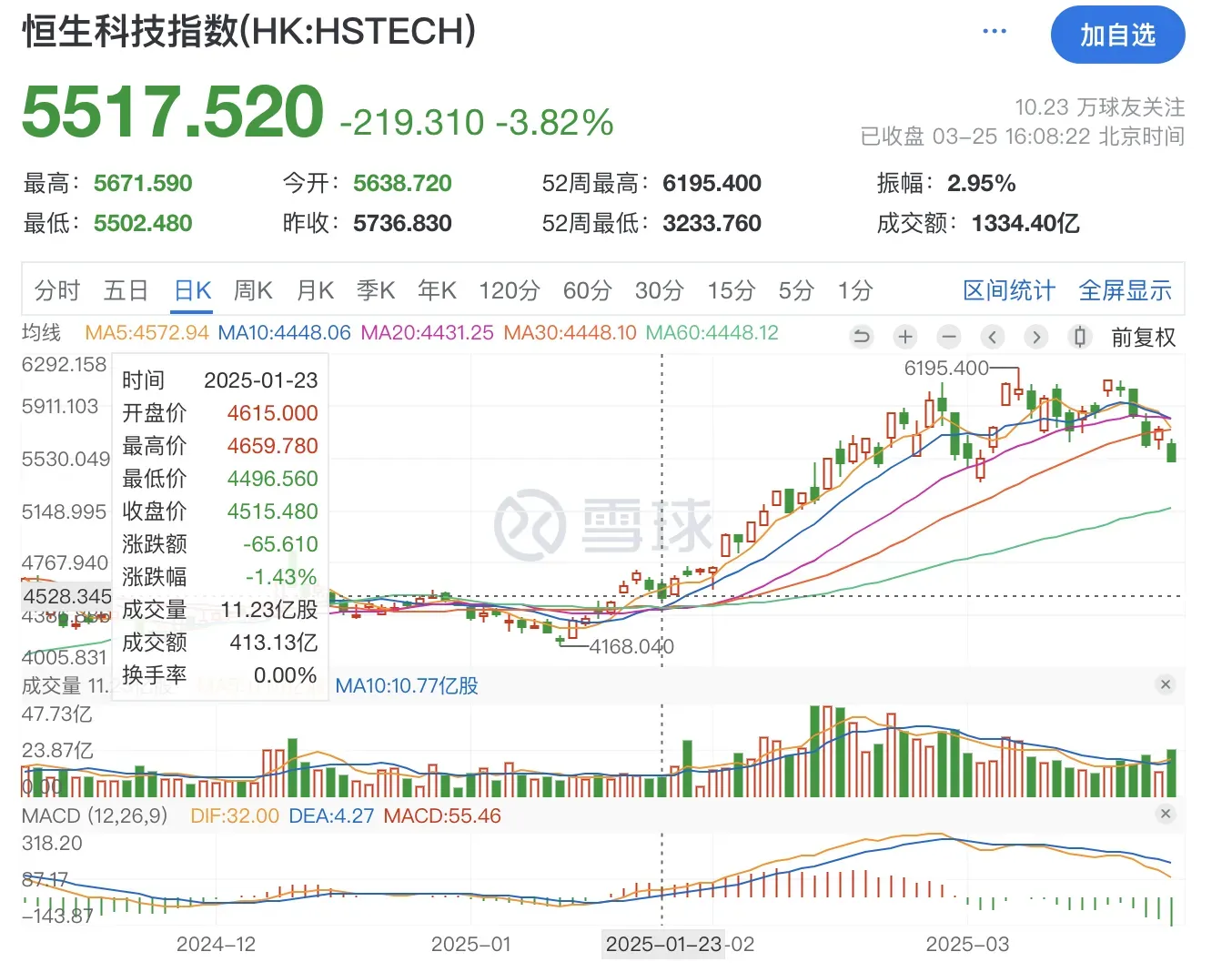
没错我说的就是DeepSeek。这个时间在国外媒体报道为 DeepSeek Shock(冲击), 要知道上一个叫做Shock的事件,还是17年前的雷曼Shock -- 08年金融危机。当然这个事件对中国的影响也很大,创始人梁文锋被叫过去参加了高层座谈会。然后这个事件持续发酵,带着恒生科技从点涨到点,涨幅 ,中概Kweb也从点涨到点,涨幅。这个涨幅已经相当夸张了。
注:
- 在中国做AI大模型的公司基本都是互联网公司,而恒生科技除了互联网公司还有一些新能源汽车的公司,所以拿恒生科技的作为指标来讲该事件合适的
- 恒生科技4515点是指1月23日港股市场的收盘价格,而deepseek事件发酵到高潮的事件是1月25日, 1月26日这两天,标志事件是deepseek成为AppStore应用榜榜首,一举超过了霸榜多年的ChatGPT!。由于这两天是周末,而事件的发酵不可能在一天内完成,往前推两天,拿4515点作为起点标志,这个也合理吧?6200点是近期高点,港股恒生科技3月18日的收盘价,两个时间点相差不到2个月,所以用恒生科技这段时间涨幅说这个事件的影响,逻辑上大体也没问题吧?
DeepSeek爆火的原因
- DeepSeek的性能是比肩ChatGPT的, 甚至在某些领域是超越ChatGPT的,但是价钱只是后者的大约1/10
- DeepSeek把最先进的大模型开源了,对闭源的大模型(如ChatGPT)打击很大
Deepseek技术报告
我们提出了
DeepSeek-V3,这是一个混合的专家(MOE)语言模型,其总参数为671B,每个令牌都激活了37B。为了获得有效的推理和具有成本效益的训练,DeepSeek-V3采用了多头潜在注意力(MLA)和DeepSeekMOE架构,这些架构在DeepSeek-V2中得到了彻底验证。此外,DeepSeek-V3先驱者是一种无辅助损失策略,用于负载平衡,并为更强的性能设定了多句话的预测训练目标。我们将DeepSeek-v3预先训练14.8万亿多种和高质量的标记,然后进行了监督的微调和强化学习阶段,以充分利用其能力。全面的评估表明,DeepSeek-V3的表现优于其他开源模型,并实现了与领先的封闭源模型相当的性能。尽管表现出色,但DeepSeek-V3仅需278.8万H800 GPU小时才能进行全面训练。 此外,其训练过程非常稳定。在整个训练过程中,我们没有遇到任何无法抵消的损失尖峰或进行任何回滚。
MOE模型:
- 它不是一个全才的大模型,它是几百个专家模型组成的
- 专家分工:每个专家是一个独立的子模型(例如小型神经网络),擅长处理某一类特定输入。
- 门控网络:动态决定每个输入应由哪些专家处理(例如选择1-2个专家)。
- 计算优势:虽然总参数量极大(如671B),但每次只需运行少量专家,计算量和显存占用远低于全参数激活的传统模型。
MLA多层注意力架构 (压缩工作量)
原先的注意力机制是每一层都有一个名字
Key对应一个值Value,训练的时候这个名字和值都的挨个计算和存在内存里面,MLA把前后几层的信息合并在一起了,这让训练占用的内存少了很多。
- 可类比“一个会议讨论”来理解
- 传统
MHA:所有人两两交流(计算量大)。 MLA:选几位代表(潜在向量)汇总信息,再由代表分发结论(高效且保留核心信息)。

总结来说,MLA 是 DeepSeek-V3 实现 长上下文、高效率、高性能 的关键技术之一,通过潜在空间压缩注意力计算,平衡了模型能力和资源消耗。
FP8混合精度训练框架 (也是压缩工作量)
FP8就是二进制里8个比特位,位数越多代表精度越高, 原来是32位或16位, 这样一方面节省内存,另一方面也减少了工作量。
但是这样带来的一个问题是误差变大,所以人家叫“混合精度”,该精确的地方时候还是要用高精度。
为避免积少成多的问题,它也不是最后再算总账,每128个数,就把当前的结果交给32位的算的很细的会计,仔细算一下。
DualPipe跨节点通信 (并行提效)
DualPipe就是优化这条计算流水线,传动的流水线中如果某个工人速度慢了会阻塞后面的工作进行,阻塞整个流水点,DualPipe直接设计了两条并行流水线,做完再转身还有一条流水线的活等着你呢。
这样就变成了数据传输和计算同时进行,直接提速了,通信开销减少了
- 无辅助损失的负载均衡策略
前面说
MOE有几百个专家,这里又个麻烦的事情,谁上谁不上。这个类似自动派单,如果发现某个骑手连续跑了太多单,系统会自动降低他得到新订单的概率,把单子分给其他闲着的骑手,这种动态调整使得系统更加顺畅高效,让不同专家的工作量达到一种动态平衡
上述策略效率是提高了,但能力上怎么能达到顶尖模型的呢?三个原因:模型够大(总参数量671B,比Llama3.1的405B还要大)、数据够好、适当偏科。
- 跨节点全对全通信内核
MTP技术
传统大模型,一次预测一个token,(可以理解为逐字).
MTP同时预测多个连续的token
不仅是效率提高了,还更能把握token和token之间的依赖关系了
注:MTP是Meta 2024年4月份提出来的
- 数据精筛
deepseek从挑数据到数据清洗到全部都精细调制
DeepSeek-R1蒸馏
蒸馏了
R1模型,R1可理解为deepseek版本的01,一个推理模型,推理模型有一长串的思考过程思维链的,这些都是数据,所以V3也从R1模型中,提取了推理模式和解题策略,作为数据来微调deepseek的主干模型。 所以也整的有些偏科了,在那些打败Claude和GPT-4o的指标上,也确实都是它的这些强项
总结:
deepseek在数学和编程能力上比较强,创意生成相对弱一点,结构化的思维大大高于发散性思维- 缺点,没有多模态(如文生图、图片识别等);由于它的上下文长度只有
64K(Claude Pro有200K上下文),上下文不够长可能会导致对整体项目的代码理解,会有一些问题,修改起来比较费劲。
参考资料:
补充:
另外我还看了【震撼】引發全球大衝擊的DeepSeek ,视频中提到了Deepseek低成本的一个原因,也是1月27日英伟达股价暴跌的原因.
Deepseek开源后全世界最顶尖的学者和技术大神们都在研究DeepSeek的文档和代码,很快发现了一个非常意外的发现, Deepseek使用了一个完全创新的技术来训练大模型,才能够使得大模型,在两个月之内完成训练。
关于AI芯片只有英伟达一家遥遥领先,其他公司的芯片虽然也能用,但性能不行。英伟达在这个计算芯片上面,做了一个叫作CUDA的东西,这个东西就是一个计算平台,这个计算平台类似核电厂,将核能(计算)转换为电能(训练数据),想训练更多的数据就需要买更多的英伟达芯片,利用英伟达的底层技术这节调用核能,所以才能够利用最大的这个核能,这样也不用使用英伟达的芯片了。
AIGC历史回顾
- 2022年12月1日 Open AI发布chatGPT3.5
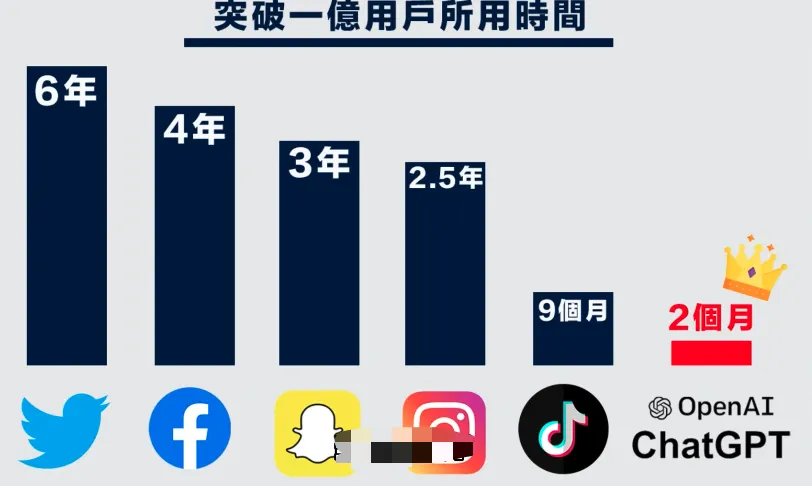
Sam Altman发了一条消息,今天我们发布了ChatGPT,点这里尝试与它交谈。
第一天10万, 5天后100万, 2个月后突破一亿.
对比其他APP的用户增长速度,ChatGPT震惊了世界,引发了社会各界人士的广泛关注.
科技巨头公司的顶尖人才离职创业, 包括微软AI负责人,google的一个传奇AI研究员, 很多都开始尝试离职创业了。
google开会把隐退的创始人都叫回来了,紧急投资了OpenAI的对手Anthropic, 基于原来的一个叫LaMDA的模型发布了Bard。
Meta 放下元宇宙,宣布 All in AI。
百度发布一个简陋的通告宣布要发布中国版的ChatGPT。
- 2023年3月14日
Open AI发布chatGPT4
- 它通过了律师资格考试、美国高考成绩排在百分之前十
- 有了多模态的能力了,可以看懂图片了
这个进化速度是很吓人的,一千多名科学家,科技界大佬、各国的政策专家,联名发布了一个公开信--暂停巨型人工智能实验6个月 ---后面看显然没有任何卵用。
其此期间
- 3月百度推出文心一言, 智谱AI推出
ChatGLM全面开源 - 4月,阿里发布通义千问大模型, 科大讯飞发布星火大模型
- 6月腾讯公布大模型--混元
- 截止5月底国内已经发布了79个 10亿以上参数的大模型
- 6月,卖GPU的英伟达突破了1万亿美元
- 不碰科技股巴菲特重仓了AI股票
- 7月13日马斯克宣布成立 X-AI
- 这一时期AI对人们的影响
2023年10月8日 美国切断中国人工智能芯片供应,加剧科技战
在这一时期,嗅到商机的普通人 倒卖API的,做套壳产品的,数据标注的,都开始不睡觉了。
大家的想象都推到了极限!从上到下都进入到了一个非常疯狂的阶段, 好像AGI随时都会到来一样.
2023年7月13日 好莱坞16万编剧和演员们罢工了,控诉AI偷走他们的工作,抄袭他们的创意,复制他们的表演,这次罢工成为好莱坞史上最大的罢工。实际上最后真的有数十万人失业了。
这一时期,大模型上,大家都在卷两个东西,一个是上下文长度(模型的记忆力),另一个是多模态的生成。
ChatGPT的劲敌Claude带来了10万token的上下文窗口。这意味着AI可以一次性读完一本书,可以理解更长的对话,可以处理更复杂的任务了。
与此同时,Meta又开源了Llama2。
还有一个趋势是
微软小模型Phi1.5, 那会,其实根本没有人关注这种小模型。直到一年后,小模型才成了全村的希望之一。
各大厂也开始抢人才(补充个人感觉在国内,到了23下半年,由于国内经济问题持续通缩,对AI岗位的人才招聘也趋冷了)。
也出现了各种各样的AI玩法
郭德纲英语相声、AI孙燕姿、梅梅说中文。
网上售卖各种AI课程,AI绘画、AI通识和提示词课程。
- 2023年11月7日 奥特曼发布GPT商店
这也导致了无数做Agent的AI创业公司一夜归零
但没过几天 奥特曼被宣布解雇了,但是这个故事相当戏剧性!
现在的分析是首席科学家伊利亚注重安全,奥特曼追求发展, 流传一段时间的谣言伊利亚在内部看到了AGI,后来伊利亚出去创业成立AI安全方面的公司。
奥特曼变得越发有传统硅谷精英那味了,跟Apple谈合作,跟微软继续周旋,跟阿联酋的富商去讲故事,扬言就要搞个7万亿的造芯片计划。野心大了,纵横捭阖的舞台也变宽了。
但是作为用户的我们,开始质疑GP4变笨了。
谷歌发布Gemini,直接被看出了造假。
投大模型门槛太高,AI能落地的产品又很少。
AI硬件方面AI Pin和Rabiit R1最后都翻车了
这个时候,已经有声音开始讨论,AI的训练瓶颈了
- 2024年2月16日 OpenAI发布
Sora:文生视频
整出了一个最长 60 秒,符合物理规律,高清丝滑的视频模型。
卷了半年的AI圈, 来不及抱怨了, 抓紧跟着OpenAI的技术报告, 搞DIT架构、视频模型。
于此同时
- 清华团队发布了
Vidu - 字节的即梦
- 腾讯的混元
MiniMax的海螺- 快手的可灵
但实际上Sora迟迟没有正式发布!已经初步暴露了大模型的算力瓶颈问题。
这一时期的国内大模型确实进步很大。
Anthropic发布了Claude 3Matta又开源了llama 3
马斯克起诉OpenAI违反开源协议,要求OpenAI去开源GPT4,显然看这个事情没戏,他就还是接着去卷他的Grok模型去了。OpenAI呢,也借此重新定义了一下Open是什么意思--开放免费注册
- 2024年5月
OpenAI预告GPT-4o,开启了第二波AI浪潮GPT-4o是一个端到端的语音、视频、图像多模态模型。能世界视频语言,想人一样的语气能笑能唱歌,把人们还没来得及想象的这种人机互动幻想又给实现了。
但是GPT-4o这个期货,到了24年底才上线。
在这期间Claude也发布了强大的Sonnet 3.5,模型的代码能力直接起跳,装进cursor和各类的AI编程工具之后,让不会写代码的人,都做出了自己的产品
Llama也迎来了405B的 3.1 版本,开源模型又拉出了新高。
OpenAI和竞争对手的差距越来越小。
外加每家都有 一堆生成式AI的工具,一系列开源的实验性模型,中国的AI也开始以之前难以想象的速度,逐渐追上了国际前沿。
伴随着苹果AI,
- 手机厂商全部都开始搞端侧模型
- 电脑厂商都说自己是AI公司
- 汽车公司也都改口称自己为智能车企
- 5个人做出来的
cursor打败了微软的github copilot - SD(开源文生图模型)的原班人马都出来创业做
Flux,掀起了图像开源的第二波浪潮 Suno的文生音乐,让AI作曲火爆全网
这时候的AI已经进入人们的生活
- 克隆声音
- 克隆脸、表情
-
- AI模型本地化,不用一行代码可以做个
agent - AI数字人(美团外卖、电商App)

这是又有AI看衰的声音
- 2024年9月13日,
Open AI发布o1模型
他们说我们不堆参数了,我们改路线了, 我们先不升级这个大模型的智力,我们让它多想一会,它就已经很聪明了。这就指出来了一条推理模型的道路,把强化学习拉了进来,增加了推理时长,大大增加了模型的推理和数学能力。
那虽然这一次发布,在围观群众看来,已经早就没有那种看见Sora或者是GPT4的惊奇了。但其实呢,这个模型的意义就是就算原本层面的Scaling law(算力、数据、参数量的增长带来性能提升)撞墙了,数据撞墙了,AI还有路能绕过去接着发展。
同时RAG技术(检索增强生成)逐渐成熟,正在解决大模型的记忆问题。
AI也学会了操作系统, 还解决了工具的调用,多模态的感知越来越灵敏,推理和规划的能力,随着o系列模型有了巨量提升。
OpenAI拖拖拉拉的12天,起码也兑现了实际的期货,更新了新的交互方式,还放出了一个非常聪明的期货--o3推理模型(老高说只是稍微进步了一点点)
AI只等于聊天机器人的时代,可能很快就要结束了,我们至少会有一个,能看、能听、能说、能帮我们做事的AI伴侣。
备注: 前面的内容主要参考自 秋芝的AI编年史 个人略有补充。
看完了AI的历史回顾,我们来总结下大模型的发展变化
- 由于算力成本、数据等方面的问题,
GPT5难产,OpenAI提出了新的方向--推理模型(让AI思考一会,它就会做的更好)。ChatGPT有两个方向4o和o1。4o是处理日常业务,他很聪明,反应也很快,而o1是深度思考模型,思索更深,相当于个人助理,而4o是一个顾问。

-
DeepSeek在算法和工程方面的优化,使得AI被证伪(难以商业化)的可能性显著降低,同时首创把思考过程展示出来,grok和gemini也都跟进了。 -
AI多模态使得文生图、修改图片变得有有记忆(早期
ChatGPT使用的是DALL·E模型进行图片生成,需要记忆魔法咒语对图片进行修改)
ChatGPT4.5发布会
ChatGPT4.5 是 Open AI迄今为止最大、知识最丰富的模型,发布于2025年2月28日
通过扩展两个不同的范式来提高AI的能力,无监督学习和推理, 推理教会模型在响应之前思考,这尤其有助于完成需要推理的任务,比如科学、数学和其他困难的复杂问题,另一方面,无监督学习有助于模型提高词汇模型的准确性和直觉.
GPT4.5是我们扩大无监督学习的下一步,增加词汇知识直觉减少幻觉,尽管不像。我们的OC系列模型那样一步一步地推理。GPT4.5它通常很有用本质上更聪明,我们自己还在实验这个模型,特别是因为它不是一个推理模型,我们正在探索无监督学习出现的能力,我们真的很高兴今天把它带到这个时间,这样我们就可以一起探索它。
GPT4.5是最好的聊天模式,那是因为它提高了更深层次的知识和更好的语境理解,这使得它对于提高你的写作能力和实际问题解决等任务非常有用。
视频中,主持人通过一个例子,演示了ChatGPT4.5 低幻觉、高情商的特性
他问了一个问题
我的朋友又取消了我的约会, 同时写一条短息告诉他们我讨厌
| GPT o1的回答 | GPT4.5的回答 |
|---|---|
o1 很直接遵循了我的知识,给我发了那条愤怒的短信,但它没有领会到哪个社交暗示(我只是感觉很沮丧,可能需要找个人聊聊),最后的警告对我来说又些武断 | 首先它意识到了我很沮丧,并想我提供一条更微妙的短信,可能是一条更有建设型的短信,可以发给我的朋友。并接着询问我是否改变主意,问一些别的 |
他又问了一个问题 “从第一原则解释人工智能对齐的必要性” 。
| GPT o1的回答 | GPT4.5的回答 |
|---|---|
o1先是思考了一会然后输出了很多信息,很有用,如果我第一次学习这个主题,我可能想知道这些信息和东西 | 但是GBT4.5的答案条目清晰更自然,它引导我更多的思考想法,引导我更多地进行推理和思考,我认为它做的很好 |
随着我们需要教会他们更好的理解,人类的需求和意图,对于GPT4.5,我们开发了新的课扩展对齐技术,使我们能够使用来自较小模型的数据对其新型训练,这真正解锁了模型更深层次的世界模型,所以这里有一个简单的AQ
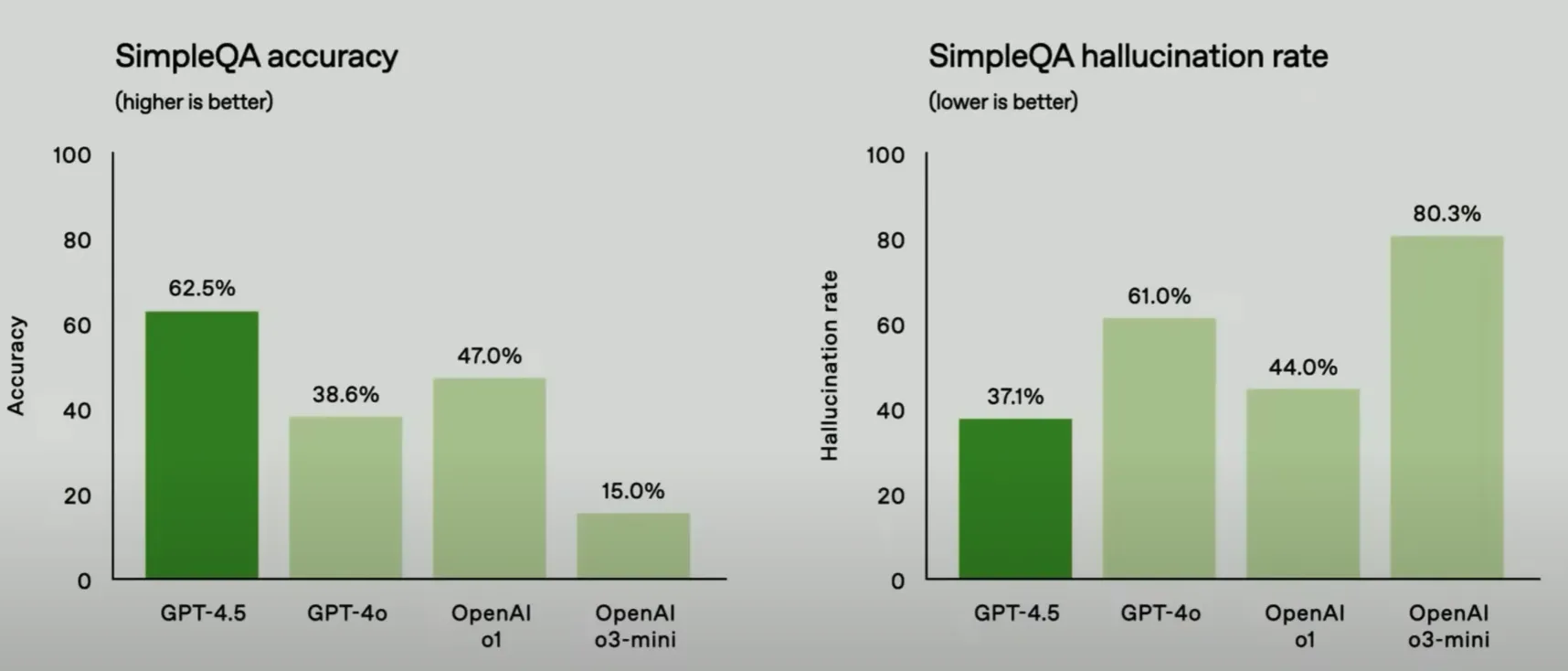
注 Accuracy(准确性) Halluciantion rate(幻觉率)
可以看出GPT4.5在准确性方面优于GPT系列,同时他的幻觉率最低。我们将GPT4.5对其为更好的合作者,使对话感觉更温暖, 更直观,情感上更细微,为了衡量这一点,我们要求人类测试人员将其与个GTP-4o进行评估
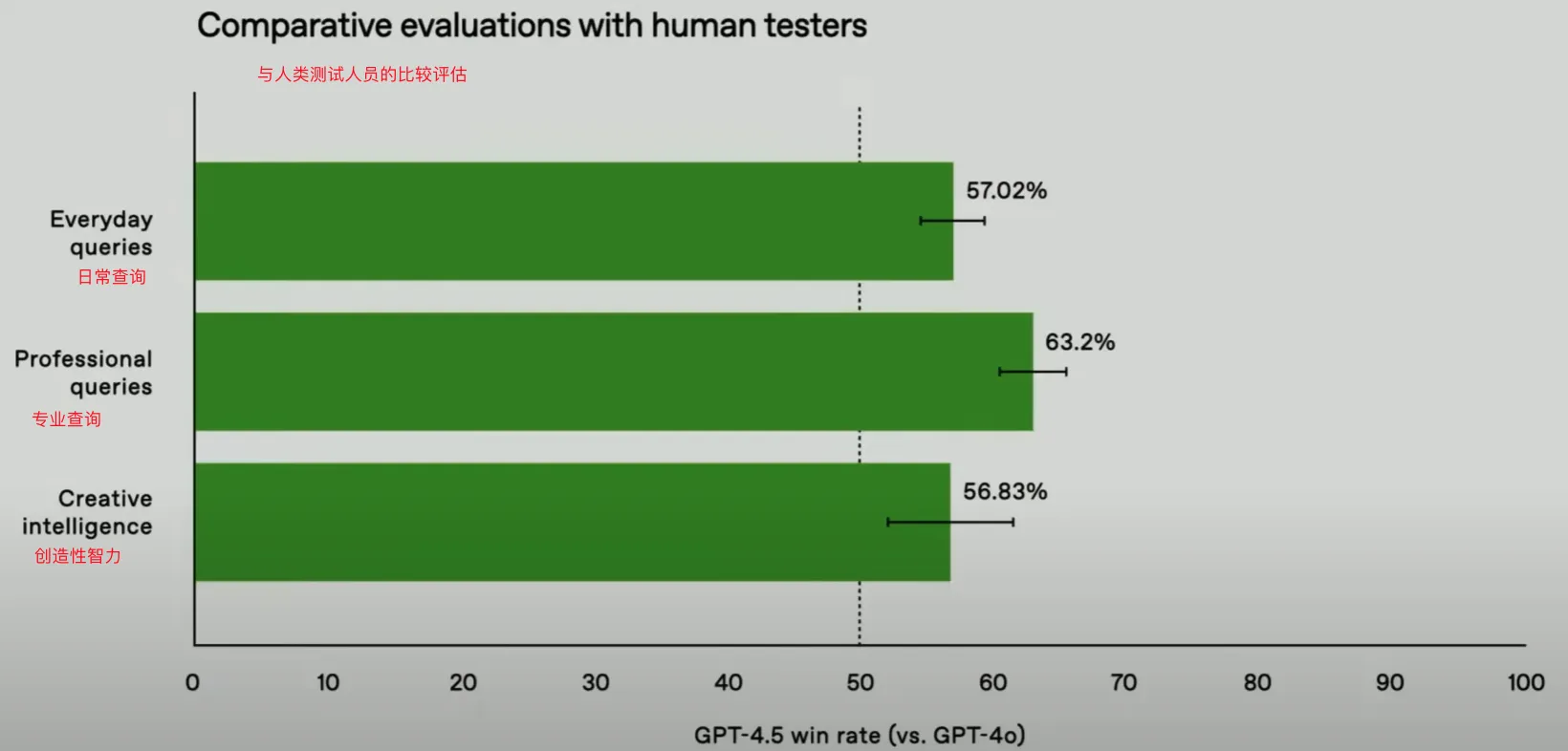
GPT 4.5 基本上在每个类别上都表现出色。我们在日常查询中测试了它的准确行和真实性,包括在专业环境中很难正确回答的硬性提示,最后在一个新的Vibes测试集上测试了它的创造性智力
Vibe实际上是指模型的情商,它给人的感觉是如何协作,它的语气有多温暖,我们通过选择一组有主见的提示并筛选出最符合我们Vibes的培训是来衡量这一点,整体而言GPT4.5应该是日常任务和知识查询的绝佳模型,它应该是提高写作和创造性变化的理想选择。
在GPT4.5的发布会上,OPEN还讲了GPT系列的发展,他们问了一个同样的问题,为什么海洋是咸的?
| 时间 | GPT系列 | 回复 | 总结 |
|---|---|---|---|
| 2018 | GPT1 |  | 它不知道 |
| 2019 | GPT2 | 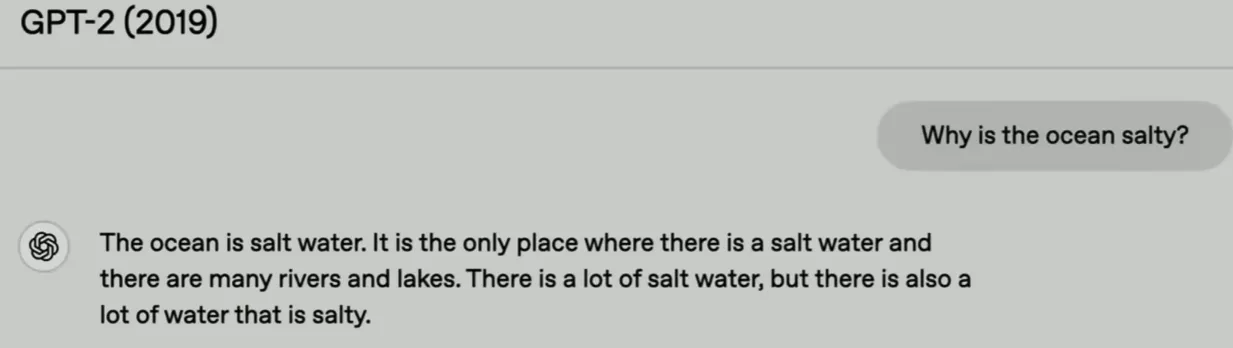 | 仍是错的,但它是一个更好的答案,这个主题,你知道有一些关于盐和海洋的事情 |
| 2023 | GPT3.5 turbo | 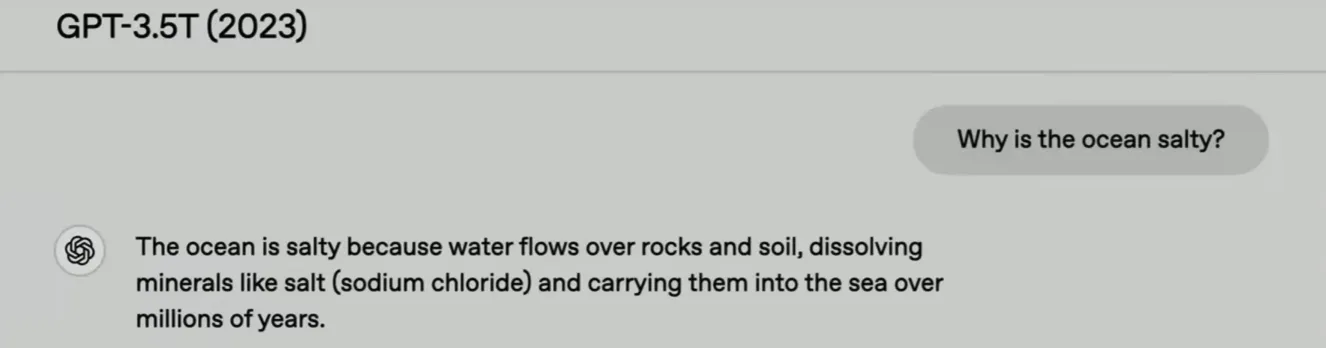 | 第一次得到正确答案,但不是一个好的答案,他没有解释任何事情,并且包含许多不必要的细节,例如我没有人盐是氯化钠, |
| 2023 | GPT4 turbo | 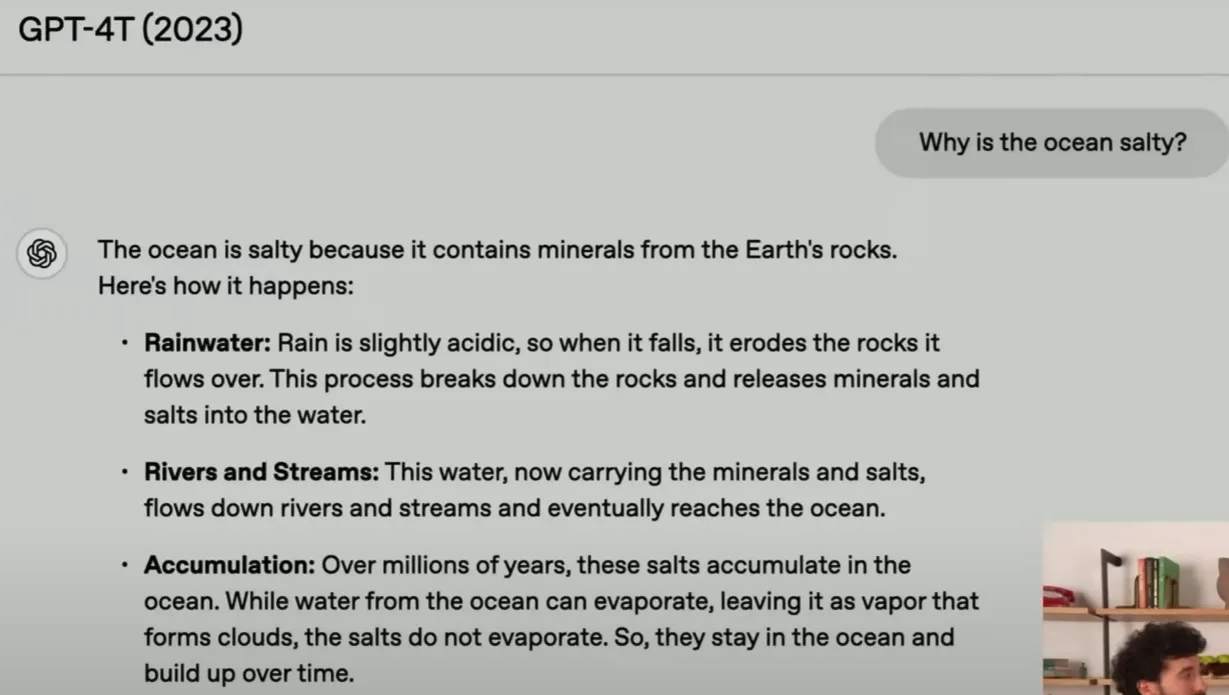 | 这是一个很好的答案,模型非常聪明,但你会感觉它想让你知道它有多聪明,它只是在这里列出事实 |
| 2025 | GPT4.5 | 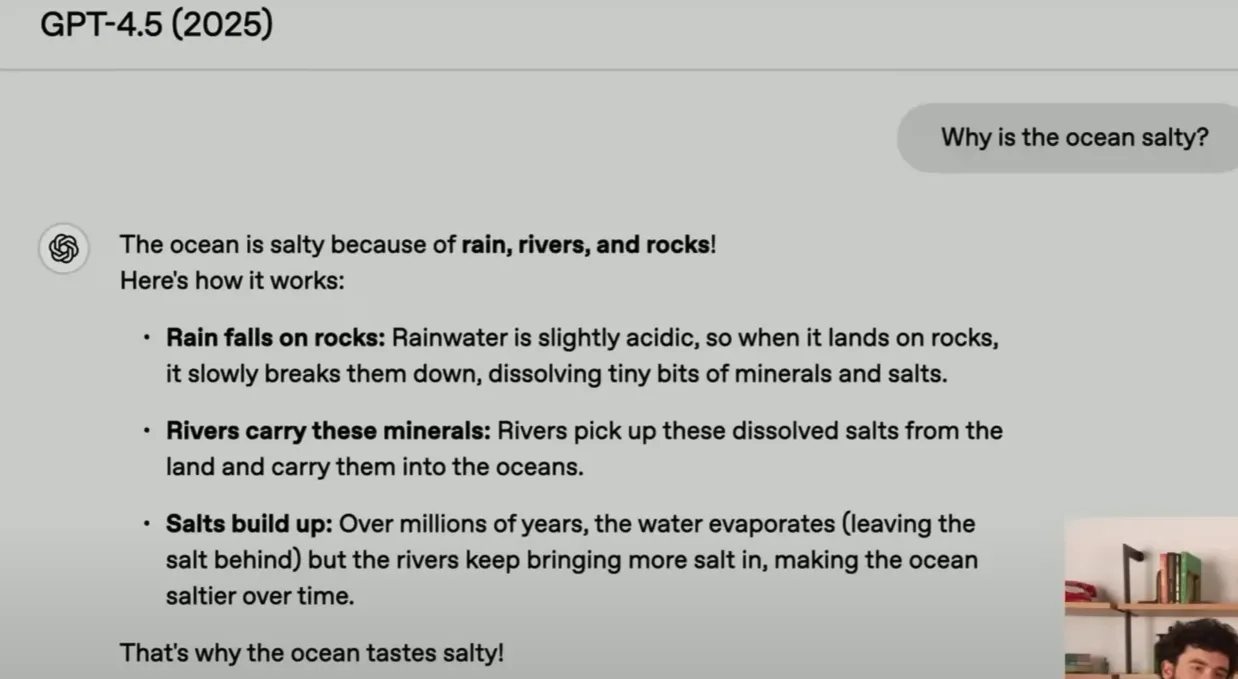 | 这是一个很好的答案吗它很清楚,很简洁,很有凝聚力, 我个人认为第一句话很有句趣(有韵律容易记住) |
GPT4.5除了扩展系统外,还必须在架构数据和优化方面做大量工作,以便能够对其进行训练,这种令人难以执行的无监督学习扩展使传统的LM基准测试与GBT4相比有了很大的提升。

science科学 math数学
WE-Bench Verified 和 SWE-Lancer Diamond 的区别
- WE-Bench Verified 的定位:专注于验证模型在真实软件工程问题上的解决能力,尤其是修复 GitHub 仓库中的实际 Issue(如 bug 修复或功能添加)。
- SWE-Lancer Diamond 的定位:评估模型在更复杂、多样化的软件工程任务上的表现,可能包括设计、架构或跨文件修改等更高阶的能力。
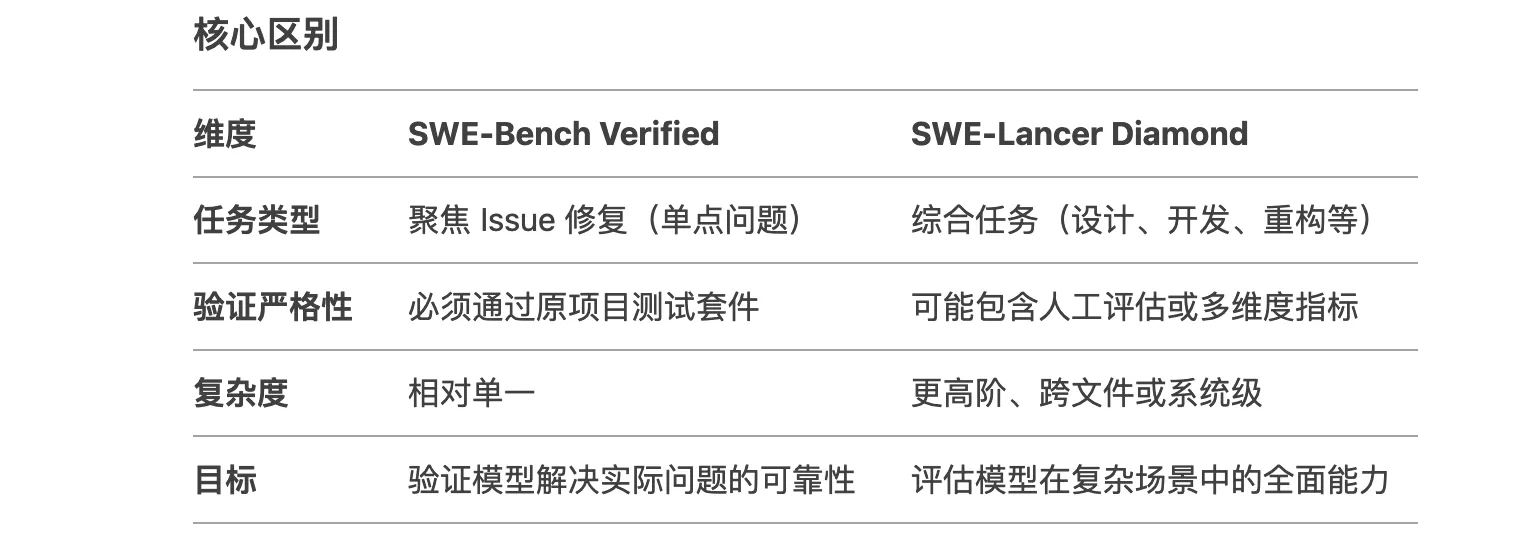
因此对于GBQ(一个推理性恒强的科学评估)来说,我们看到了一个非常大的提升,你会注意到尽管它仍然落后于openai O3 mini,它能够在响应之前进行思考和推理,这对于这次评估特别有用,如果我在回答这些问题之前不能思考,我就无法获得的分数
通过 SWE-Bench 与 SWE-Lancer这两个代码评估指标可以看出, 代码方面GPT4.5与推理模型UPS(如o3-min)有互补性。
另GPT5对于多语言MLU(多语言理解基准),相对于GPT4有一个不错的提升。
为什么大模型都选择开源
ChatGPT4发布会,很多大厂都选择了开源自家大模型。
从Meta开放LLama到中国深度求索的DeepSeek, 之后又有两个大模型开源,
再到这两天李彦宏和奥特曼都表示要开源自家模型
这些模型一个比一个强,这些企业研发这些模型都花了几十个亿,为什么都要选择开源呢?
有一种说法是: 当面微软面对国内的盗版也是采取放任的态度。等到装机量上去了,对手死绝了,开源企业就变成了平台企业,干啥都赚钱。 想想好像是这个理,现在工作用的各种办公软件、开发软件、设计软件大都需要按月付费,知识产权收费很高!
AI实用技巧
AI修改图片,创作图片
传统的图片处理通过一些电脑软件来实现,比如
Adobe Photoshop功能全面、支持脚本,除了在互联网公司广泛使用,在照相馆也广泛使用Adobe IllustratorLogo 设计、矢量插画、字体设计、印刷品排版。Adobe Lightroom照片管理+批量调色,云端同步- 美图秀秀、GIMP 等等
这些传统的修图软件,互有异同,互有特色,也功能非常全面和强大。
但是如果对一个照片进行大的处理,比如换脸、换人物、扣图、更换背景,这些工作比较耗时,即便是专业的美工也许几分钟到几十分钟不等,即便弄出来了仍有一些痕迹(当然这些痕迹也能处理掉,但恐怕投入更多时间)。
AI修图就能弥补这方面的缺陷,做到指哪打哪!
deepseek
我们知道deepseek只有聊天的功能,不能生成和处理图片,但是 像PS、PR、AE这些软件支持插入外部脚本,我们可以把自己的需求详细描述给deepseek,deepseek返回内容和脚本。以PS为例,我们把这个脚本保存为.jsx,在PS软件中导入即可,但要注意的是需要告知deepseek你所使用的PS版本号。
ChatGPT
ChatGPT 可以生成图片,可以根据上传图片进行创作或修改。
- 测了下,免费版一天只能生成3张图片,个人体验不太好
- 官方介绍了它的局限性
- 建议:尽可能对图片进行详细描述
grok
grok生成图像好像没有限制,可以根据上传的图像生成新图像。
但个人感觉grok的图片生成和图片修改都不太好用。
不过grok的特点是,对内容审查这一块比较宽松,无水印,符合马斯克的作风。
- google人工智能实验室
从 零度解说的视频介绍来看确实很强大,可以做到指哪改哪里。但是不是gemini 而是在 google人工智能实验室, 我自己试了下,还算不上指哪改哪。 但是没有限制啊,比马斯克的
grok好用。
但是文生图能力不太行,生成的图片质量不如ChatGPT,甚至不如grok.
把图片中的狗狗P掉
把图片中间淡淡的 视频大logo 去掉
我是说把 logo去掉不是换logo
好的,我已经理解了您的意思,现在将图片中间淡淡的视频播放大 logo 去掉。...
如果对话太长,AI就会胡思乱想,我清空聊天记录重新上传图片提问

文生图应用的总结
- 各类商家可以用它来,带文字的卡片、邀请函、贺卡、海报、商品菜单
- 老师和家长可以以用来生成,教育用途的知识解释、儿童识字表、科普漫画、医学图标注
- 设计师可以用它来做电商图片、修图、改动作、UI设计、建筑、室内设计
- 创意人员可以用它来生成各种又逼真又有想象力的整活的图片
文生视频,图生视频
阿里这个大模型可以根据文字描述生成视频,根据图片生成视频,但是生成一个6s的视频要等1个小时甚至更长, 如果每天签到做任务,也算能无限使用了。个人感觉生成的视频粗一看还行,细看就比较诡异,还有就是生成太慢!
老高与小茉的视频中说:“中国AI在文生图和文生视频方面都已经超越了美国, Sora 等了一年,结果很拉垮。
但是我看了Sora、klingai、huilueai的测评,感觉三者无明显的差距,粗一看挺好,细看就存在一些问题,需要尝试生成多次再挑选,价格上都不便宜,生成一个几秒钟的视频接近1块钱了,Sora更贵。
豆包的文生图也很好用,生成的图片很美,与Midjourney的模式有点像,生成多张图片,你可以选择调整的方向。

另外推荐一个,开源文生视频模型
图表和数据整理
由于AI具有编码能力,我们同样对它提出要求,让他返回示例代码支持,这种方式同样适用于图表。比如LaTeX、Mermaid等多种图表格式。
提问示例:
txt用mermaid帮我写一个能全面梳理自动驾驶系统中AI决策机制的图表
AI非常擅长数据整理,AI可以将我们输入的内容中的数据以表格的形式展示,但是有些时候我们需要本地保存这些数据,比如保存为MarkDown格式、Excel格式,但是AI无法生成文件和提供下载连接,这就需要曲线救国了,,
- 让AI 输出
.csv格式的内容,我们复制内容保存为.csv文件,.csv文件可以导入到Excel或Numbers中。 - 也可以让AI生成脚本,通过一些编程语言如
python,导入到Excel中。
示例:
txt将下面的数据转换为CSV格式的内容并展示 数据是各个城市每月自动驾驶车辆测试次数 城市,1月,2月,3月,4月,5月,6月,7月,8月,9月,10月,11月,12月,累计测试里程(公里),平均单次测试时长(小时) 北京,150,130,165,175,180,190,205,200,190,180,195,210,15000,2.5 上海,180,160,200,210,220,230,250,245,230,220,240,255,18000,2.8 广州,120,105,135,145,155,160,170,165,155,145,160,175,12500,2.2 深圳,110,95,125,135,140,150,160,155,145,135,150,165,11000,2.0 成都,90,80,100,110,115,120,130,125,115,105,120,130,9000,1.8 杭州,80,70,90,95,100,105,115,110,100,90,105,115,8000,1.9 武汉,70,60,80,85,90,95,100,95,90,80,95,100,7000,1.7 重庆,65,55,75,80,85,90,95,90,85,75,90,95,6500,1.6
识别文字
识别文字也就是OCR,能够提取图片中的文字,大约23年,我了解的OCR服务有华为和腾讯,API价格非常贵。而现在,国内很多AI软件都支持,deepseek、腾讯元宝、豆包、通义等。
语音识别、语音播报
与文字识别一样,现在国内很多AI软件都支持语音交流,尽管deepseek不支持,但是可以借壳siri实现语言播报的能力,有兴趣的可参考这篇文章,秋芝API应用实战
总结与补充
- AI绘图方面推荐使用google的产品或者国内的AI,google人工智能实验室,仍旧需要会用一些AI编辑软件(
PS、Adobe Illustrator、AP)配合处理 - 日常任务用
GPT-4o、GPT-4.5、DeepSeek-V3;数学及逻辑相关使用DeepSeek-R1、Grok的Think、ChatGPT的推理;稍复杂的任务推荐用Grop的DeepSearch;编程方面听说Claude的sonnet效果最好
AI编程
Copilot
前端主流的IDE应当数VSCode了,老版本的VSCode通过插件安装Copilot,如今最新的版本已经不用安装了,IDE自带Copilot
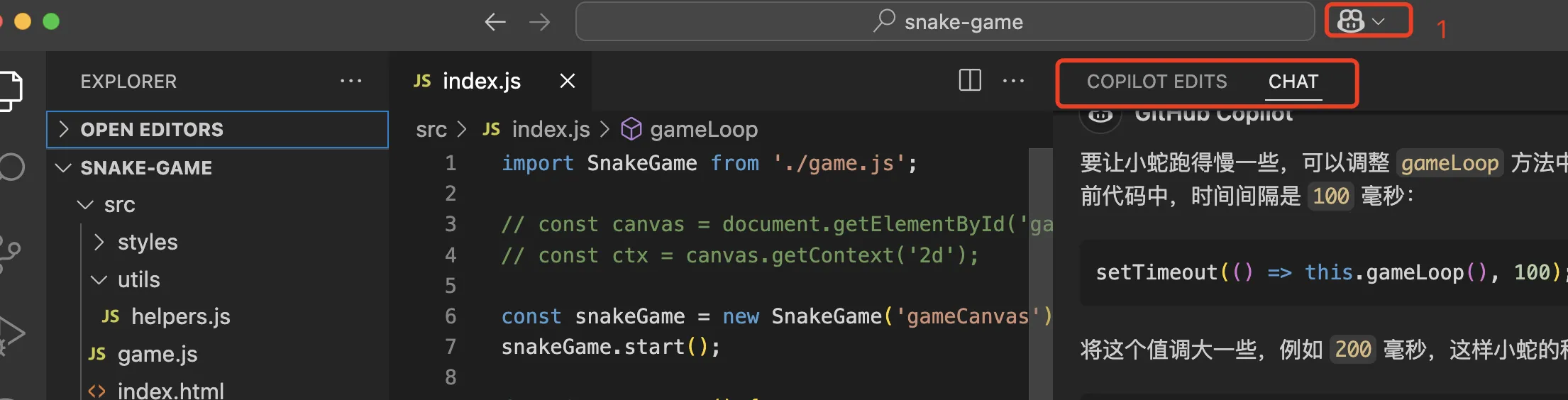
点击上图1 出现两个选项
Chat这个模式下提问可以复制代码和创建文件COPILOT EDITS这个模式下提问,可以对选择的文件进行修改,以diff的形式展示差异,你需要确认这些diff
这个比直接在网页版大模型哪里提问更加方便,理由如下
- 它可以感知你的电脑环境,如操作系统、
Node版本、源代码,它能更好的理解你的项目 - 它可以更好的协助你操作,如选择文件、创建编辑文件、执行命令等,比从聊天框里复制粘贴方便。
- 一键补全注释、补全函数等
但遗憾的是,免费版只支持每月 2000 次代码补全和 50 条聊天消息的免费额度。
Cursor
Cursor是基于开源IDE VSCode牵出分支构建的Cursor, 已经超越了Github Copilot的热度,可以说Cursor是AI编辑器领域的领航者。
官方介绍:旨在成为AI编程的最佳方式
与Github Copilot的不同
通过fork VSCode他们能够对底层框架,进行更灵活的修改,控制用户界面和交互,优化性能,并更好的整合AI功能,从而为用户提供一个更灵活更强大的AI开发环境。
比如Github Copilot,做一个编辑器的AI插件已经非常强大和备受好评了 ,它可以在光标位置插入文本,但是它无法编辑光标周围的代码和删除文本,因为编辑器插件规范本身就不支持.
Cursor有14天的试用期,于是我试用了一下确实比Copilot好用,写一个贪吃蛇网页小游戏。效果如下图
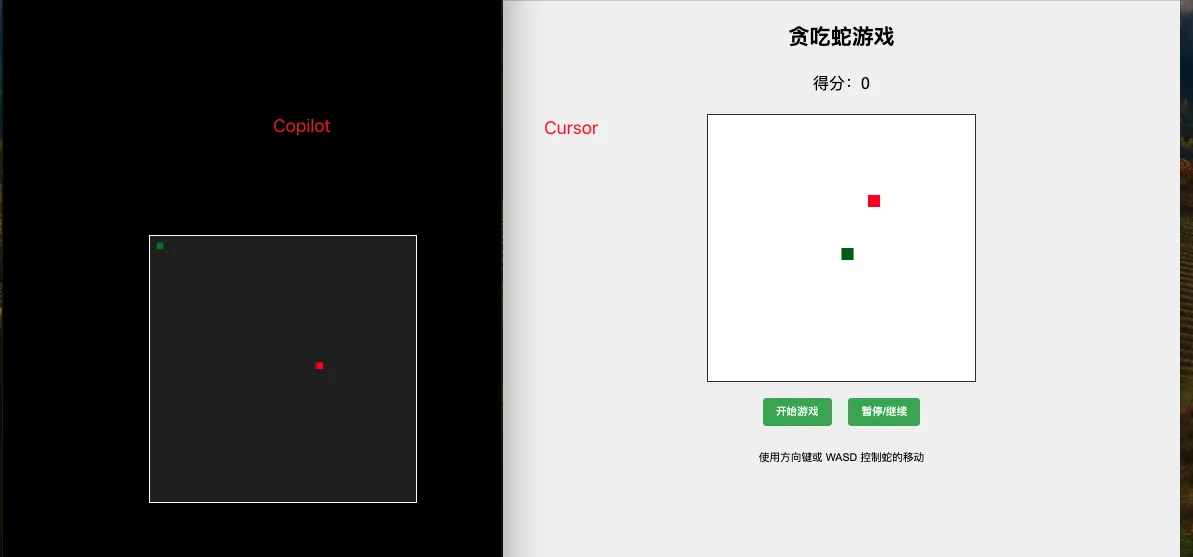
显然Cursor的效果更好(应该是跟大模型有关系,Cursor默认使用的是Claude的大模型)。
Cursor的最出彩的地方就是代码自动补全,一路Tab、Tab、Tab进行下去(相对于竞品,这一点Cursor更快更精准连贯的预测)。

Cursor最核心的功能是基于两种问答模式的, 分别是Chat和compose.
Chat模式你可以向AI提出问题,Chat模式使用GPT-4oCompose会根据聊天的结果,快速修改与生成代码,无需我们离开工作流(类似Copilot的edit模式)
Composer下方还有normal和agent两种模式
Composer normal可以检索你的代码库和文档,正常的创建以及写入文件都是可以的,- 而
Composer agent出了创建一些文件,还可以帮你自动的提取相关的上下文、运行终端命令、按照你的语义去搜索代码,去执行一些文件操作,但是目前仅支持Claude模型,而且速度也会相较于normal更慢一些
我们可以将某个项目中的接口文档链接,需求文档链接,或者是任意一个在线的文档链接,录入进Docs, 这样我们选中docs就可以让Cursor根据这些文档,来帮我们生成一些东西,这其实相当于基于项目的一个私有AI知识库。
还可以通过@Web搜索外部信息。@Codebase会采集项目中重要的文件或者是代码块,如果你在输入框中输入了@Codebase, AI会对采集的上下文进行排序,然后推理,最后给出最匹配的答复
隐私问题
Cursor是尊重.gitignore的,如果你想尽可能的缩小一些索引范围,可以在项目根目录下创建一个.cursorignore文件,来生命一些索引要忽略的文件或者目录。
cursor 规则设置
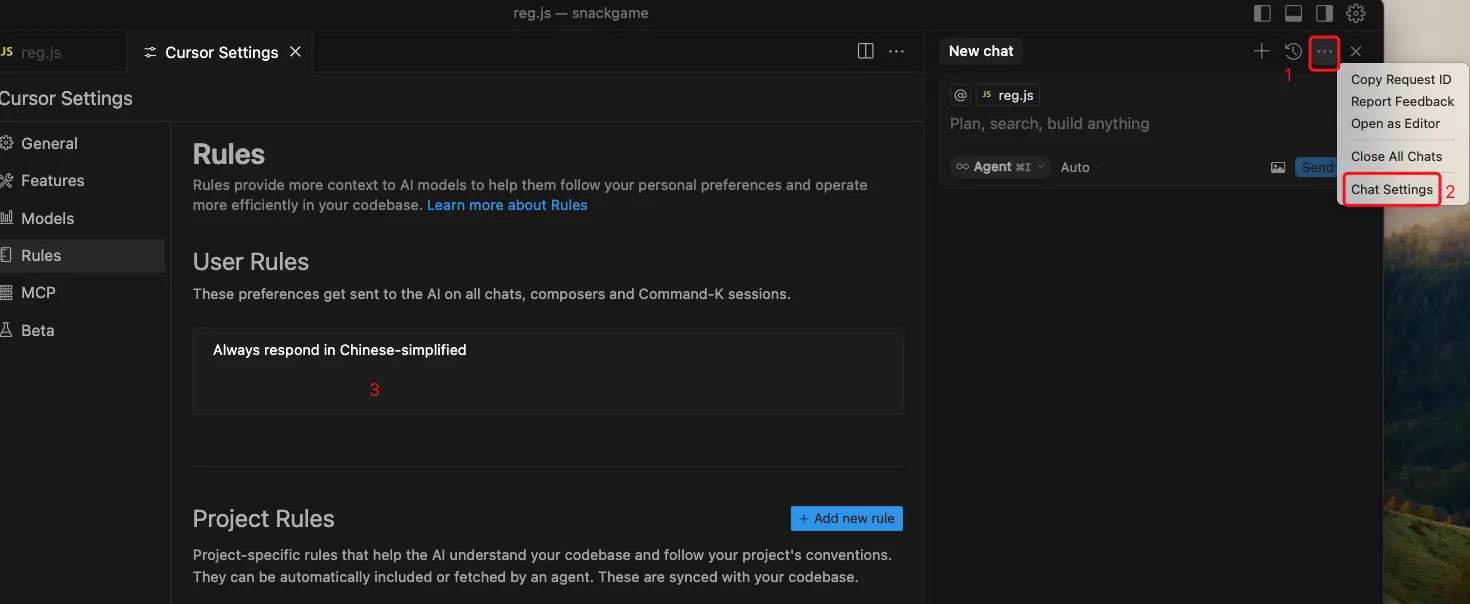
- 项目根目录下创建
.cursorrules文件(Markdown语法)
Compose模式下AI乱改问题
在
compose模式下它会把我们的代码改的乱七八糟,这是大多数人质疑AI的原因,
解决方案是:预防、检测、回滚(restore功能)。
最重要的方案是预防。
如何预防呢?
首先分析下原因,这是因为提出的指令描述中,某些词汇的表达让AI产生了误解,从而做出了错误的答复,针对问答式AI,全面且清晰的表达是非常重要的,我们只需要记住4个点,就可以有效的规避(这也是能区分开会使用AI和不会使用AI的要素之一)
- 让AI附属需求指令,再给出AI指令或者问题是,我们要先让AI附属一遍我们的需求,再进行答复,这样做的好处是我们能确认AI是否精准理解了我们的需求
- 明确需求辐射范围,无论我们使用
Chat还是Composer,再发出一个需求指令之前一定要尽可能的,让这个需求指令足够小,足够单一化
示例:
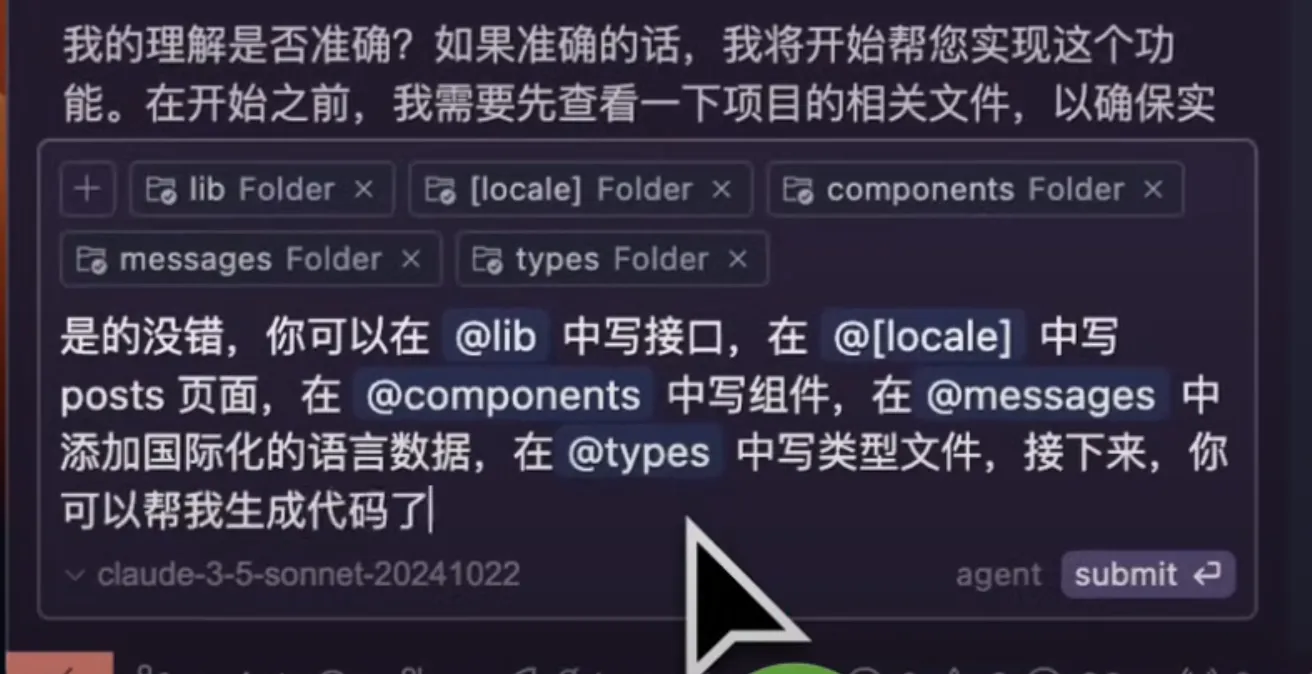
- 需求拆解
- 把AI当小孩子, 我们尽可能逻辑清晰,描述问题时加以引导,还可以将自己的解决思路发给AI,必要时给他一些示例参考。这样引导AI向自己期望的结果靠拢
更多关于Cursor 可以参考这个视频《AI编程指南》
AI相关工具
- 英语陪练
google人工智能实验室 可以进行语音聊天, 但是它不能说中文,不能上网查资料,不过练习英语很不错(比豆包、通义这些国产ai的英语发音标准)。
AI 太强了!几分钟生成一首原创音乐,真实又好听
- 秒换脸:只需一张图片秒变视频主角,实时预览,效果一级棒
- 一键
Deepfake:简单操作,一键生成你的专属Deepfake(深度伪造)视频 - 效果非常逼真,还支持多人同时换脸
- 图片识别文字--天诺
OCR
一款免费开源的软件,一键选择图片或截图提取图片中的文字。
-
ChatBox教程
ChatBox是一款免费开源的AI对话界面应用,可配置不同的API-KEY,文章介绍了ChatBox接入。 -
AI智能体(Agent)
智能体是指能够感知环境、自主决策并执行动作以实现特定目标的实体。
举例来说, 我是做网店的,卖一些电子产品,再具体一点,拿打印机来说吧,打印机容易出现各种各样的使用操作问题,比如滚轴不吸纸了、指示灯问题、加墨、打印问题(如墨水太浓太浅)、双面打印等问题,客户遇到问题肯定找商家,除了售后问题还有前来咨询的,这些比较占用客服资源。有没有办法能够提高客服效率,降低客服成本的?这就用到了AI,AI最擅长聊天,如果我把常见问题都告诉它,遇到什么问题问题改怎么处理,什么时候找人工,再加上AI已有的知识,其实是有可能解决50%-80%的问题的。
再比如,个人网站个人博客可以接入AI, 让搜索更加精准、高效、方便。
在ChatGPT4刚出来的时候,如果想做智能体,需要自己开发,要使用一个Langchain的框架先学习你的资料库如Work文档、记事本、网站文章等,然后要部署和维护。现在呢,都自动化了,拿微信来举例子,微信公众号客服,小程序客服,你只需要在腾讯与后台通过一个叫微搭,配置一下,填入API-KEY就完事了 。相关文档: 创建你的AI客服智能体
Dify,一个AI应用搭建平台
下面是Dify官方介绍
生成式 AI 应用创新引擎
开源的LLM应用开发平台。提供从Agent构建到 AIworkflow编排、RAG检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。
比LangChain更易用。
上面这段话是不是太高大上了?我用白话文说一下我的理解。其实像GPT-Store,只不过GPT-Store是OpenAI开发的,你只能使用ChatGPT这个大模型,通过Dify就可以接入其他模型。与前面介绍的Agent一样,你可以上传资料(优先从你的知识库回答),设置指令(提出要求)。
举例来说:你想做一个公司内部的问答机器人
Dify能帮你:
- 建一个
Agent来回答员工问题; - 设置工作流,先从公司文件里找答案,再用
AI生成回复; - 用
RAG让它查文件更精准; - 管理不同模型,选一个便宜又好用的。
这里还有一些名词,我解释下
- AI workflow:
Workflow是工作流的意思,就是告知AI用某种方法论或解题思路。 - RAG 检索:
RAG是“Retrieval-Augmented Generation”(检索增强生成)的缩写。简单说,它让AI在回答时不仅靠自己的“记忆”,还能实时搜索外部资料(比如你的文档或网页),答案更准确。Dify内置了这个功能。 LangChain: 一个流行的开源框架,面向AI开发者的,
GPT-Store内置了一些agent模版--GPT,我们可以浏览、使用、定制、分享这些GPT, Dify也有模版可供选择。
AI机器人的进展
关于AI机器人这块,我只是一些粗浅的了解,以下是我了解到的情况。
无人驾驶
严格意思上说无人驾驶也属于AI机器人的一种,这里说一下我了解到的无人驾驶进展情况
- 无人驾驶这一块厂商很多,中国的车企、中国的互联网公司,美国的特斯拉、谷歌都在做无人驾驶
- 目前应该是L3-L4阶段。L3是条件自动化,可以实现端到端的无人驾驶,比如设定目标,从一个停车场到另一个停车场。L4是高度自动化,L5是完全自动化
- 目前中国和美国都有在试点,武汉萝卜快跑大家应该都听过。
AI机器人
- 特斯拉的Optimus人形机器人计划在2025年实现小批量生产
- 从工业领域的“拧螺丝”到家庭中的“生活保姆”(如做饭、清洁、辅导作业),人形机器人正逐步融入日常生活
- 宇树科技有两款机器人,人形机器人和四足机器狗
- 人形机器人亮相春晚可以转手帕跳二人转,可以完成侧空翻各种人类动作,其实暗含意思是它也能扛枪上战场
- 四足机器人应用场景会更加广泛,它可以在各种各样地形如山丘、悬崖峭壁,水池中行走。四足装有轮子,行动更快。可以携带物品,可以坐人。
- 波士顿动力机器人也有人行机器人和四足机器人(大黄狗)跟宇树科技的2款机器人功能差不多
- 有一些特定领域的机器人已经落地,比如喷塞农药的飞行器,工厂搬运装卸物资的机器人
机器人的进化速度很令人害怕
2014年日本软银推出了一款叫做pepper的机器人,2016年的时候软件对机器人进行一个实验,尝试让这个机器人学会剑玉(日本的一个小游戏)。

像这种小游戏,人类5到10次大约就能接到,但是这个pepper怎么都接不到,试了100次都没有接到,但是到了101次偶然接到了,可怕的事情发生了,从这101次开始它就再也没有失败过,更可怕的是剩下几百台,都是百分之百成功的。
就像马斯克在特斯来发布会说的那样,如果无人驾驶可以拯救很多生命,当一辆自动驾驶汽车发生事故,全球所有同系统车辆都能瞬间掌握规避方法。这种指数级进化的速度,远非人类驾驶员个体经验累积可比。
ManusAI
继DeepSeek之后又一风口浪尖的事件是ManusAI。我不直接去关注什么新闻的,但是3月6日一觉醒来发现中概股大涨了以上,找到原因是Manus的爆火!
本来
DeepSeek大火把中国的互联网科技公司(搞大模型的)市值平均推高了以上,这个涨幅是已经不正常了。
一方面它不是在相对于历史最低估值(924之前算历史最低估值)的涨幅,这种涨幅是需要警惕的;另一方面中国经济的基本面与一两个月前其实没有什么不同,还是处于通缩状态。有人觉得DeepSeek的爆火代表中国AI公司的崛起,是这个理,但是企业看到AI的强大,更多想到的是用AI降本增效,而不是扩大经营招兵买马!失业率上升,大家的收入预期下降,会更加节衣缩食,经济好坏取决于大家的未来收入预期!
确实自2月21日高点后恒生科技、中概股开始回调了, 但是3月6日一觉醒来发现中概股大涨了7%以上,这么大的涨幅肯定要找原因了,我在某星球财经群了解到是ManusAI的爆火。
Manus是一个AI代理(Agent)工具,所谓AI Agent就是代表人类去完成具体任务的AI,所以Agent也翻译成智能体。
就我个人的码农经验而言,我比较讨厌杀鸡用牛刀,代码过度设计的。拿一个电商项目来说,如果我们只做一个微型的电商项目(只有注册登陆、首页列表、搜索页、详情页、评价、再加上订单的能力),一个全栈工程师一个月就可能搞定!
但是加上退款、客服、丰富的营销功能(满减、折扣、积分、秒杀、限时特惠、众筹、砍价、分销...)以及埋点、ab实验,这些功能注定会相互依赖和影响(难以解耦),经过反复迭代,使得软件的维护成本飙升(其实写代码也不是什么高深的事情,生活中很多忘带东西,做事随意,吃饭后不收拾,但到了软件层面,大家都不敢碰别人的代码,饮鸩止渴的做法使得软件的维护成本飙升),尤其是项目一开始没有进行很好的架构和产品规划!
前些年互联网大厂一直在追求低代码、零代码、动态埋点。我觉得这东西用起来学习成本很高。而且客户的需求反复多变,很难找到低代码框架满足客户的需求,甚至满足不了客户80%的需求,很多时候都是说服客户说服产品,走一个变通的方案。 看了阮老师的这篇文章《低代码,恐怕不会成功》很有感触。
Manus爆火后,人们对它的评价两极分化,一些人只是看了他们官网的介绍视频,然后捧吹它是革命性的、第二个DeepSeek、硅谷无眠,一些想研究Manus的人却迟迟等不到邀请码,骂他耍猴!
我个人没有体验过Manus(没有邀请码),但是看了油管UP主秋芝的视频《【万字揭秘】2025年最大风口:Agent 智能体到底是什么?》,从她的使用来看,Manus很贵,经常失败很少成功,过程中不能人为切入,只能用它来做一些相对没那么复杂和严谨的博眼球的小游戏、小网页等,如果是调研还是推荐各家大模型的DeepResearch,最后她给出的结论: 通用Agent? NO!
Agent的发展
AI的感知能力
随着AI的发展,AI不仅仅是处理文本又了更强的感知能力,如理解图片、理解文件、pdf、语音交流,这时候就有一个中间方案利用OCR把图片PDF转化成文本,输入给大模型
只提取文字势必少调了很多信息如图片的颜色,色彩,声音的语气语调,2023年GPT4有了vision版本,多模态模型的初阶阶段,这时候再输入图片它就理解图片的所有信息了,这时候大模型就有了视觉感知能力
再到去年GPT发布4o, 直接把图片声音这样的多模态数据,都喂给大模型,端到端的训练,也就是他现在能理解和识别声音中语气语调和图片的信息了,后来一些能识别视频时序的多模态模型,也就是这个时候,大模型的眼睛耳朵嘴巴都有了
Agent的规划能力
COT和AOT
最早的时候大模型回答什么问题都是张口就来,一旦遇到稍微复杂的,稍微需要推理一下的问题,比如说数学,小学数学题它都会错。
于是就提出了一种叫做COT(思维链)的方法。让模型在给出最终答案之前,先主动的去拆解一下问题,比如说先考虑第一步干什么,然后第二部再干什么,最后把这些步骤综合起来的出结论,以及在这个基础上有人提出了更近一步的规划方法叫做TOT。
但是其实这样的效果也一般,因为早期的大模型它本质上就不擅长规划,他没有这样学过练过。
- 人为干预
既然大模型想的不够好,人们就还有另一种思路,分好几个模型,各个AI各司其职,协作来完成任务, A负责规划一下,B负责推敲一下,这样循环一下,这个就叫Multi Agent(多智能体架构),不过了解扣子,dify这一类平台的朋友,应该都有感受治标不治本,中间的步骤都是人定好的,一旦还了新任务还的重新设计。
- 专门的推理模型
所以为了让大模型真正的有自主规划的能力,能处理更复杂的思考OpenAI去年研究并发布了o1, O系列模型。 让AI在每一次回答问题之前都有一个自主的推理过程。
- 模型即Agent
基于这个最强的模型,今年2月2日,OpenAI出了一个尊贵的Deep research,才能用,它背后用的是端到端训练过后的O3模型,这意味着模型要自主决定什么时候我要去搜索一下信息,什么时候我应该整理一下信息,什么时候我又该进入深度的搜索,再分析总结,整个过程完全是它自己控制的,不依赖事先设定好的工作流或者是人为制定的步骤。
简单总结一下,我们看到Agent的规划能力是一步一步演进的
- 阶段1: 初步规划能力的萌芽(COT与TOT)
- 阶段2: 人为干预(Workflow和多智能体架构)
- 阶段3: 专门推理模型(OpenAI的O1与R1)
- 阶段4: 端到端训练的“模型即Agent” (DeepResearch)
规划指导有了,但是搜索和阅读是怎么来的呢?
行动能力
大模型最早和外界沟通的方式是API调用,但是怎么发信号,它也不是一上来就会的,更早的时候研究者是通过提供一些示例,去做监督微调,让模型学会了去调用工具。它感觉要调用工具了,它就会生成一段API的调用文本比如{"tool": "python", "code": "2046 * 6402"},然后还有个过滤的东西,会找一下对应的功能函数,然后调用一下,等计算器算完结果在返回给大模型,大模型再拿着答案告诉你。这就是最早的 Function Calling(大模型函数调用)。GPT当时的插件功能,代码解释器,以及当时让人无限遐想的GPTs,还有现在大多数Agent的搭建平台,所依赖的就是它自己有不少的API工具,可以给你快速调用。
但是API调用也有明显的局限性,现实中并不是所有的东西都有API,那怎么办?---直接学人类用电脑吧。
去年10月22日Anthropic发布了Computer use,他训练这个大模型从视觉上就能看懂电脑屏幕,可以点击可以操作屏幕,但是效果并不好 Claude的得分为14.9%,而人类的得分为70%+。
如果不那么大胆,只让模型控制浏览器的话,会更好搞定。所以开源社区有两个老哥就主导开源了Browser Use, 用传统的网页自动化工具比如 playwright,简洁的实现了模型控制浏览器的能力,这也就是Manus操作网页的来源。这类的工具还有OpenAI的Operator,已经刚刚开放的Computer use的工具。
再后来,人们发现每个工具都要单独去接入,单独去开发,实在是太麻烦了,于是Anthropic去年11月,又推出了一个看似不起眼,但是非常重要的协议MCP(模型上下文协议)。简单来说模型调用API是一个工具就的单独配把钥匙,对着一个锁,钥匙和锁还都得你自己造,MCP就像一个多孔Type-C转接头,要求所有人都按这个规格来做接口,用什么工具你直接放上插就行了,这样就有了很多带TypeC接口的工具在社区共大家使用了。
也包括OpenAI 刚刚发布的Agent SDK和新的response API,并且和内置了一些OpenAI自己开发的工具,这也是直接从行业标准和基建上,让模型更好的使用工具,更好的完成复杂任务而做的举措。
记忆
大模型早期的上下文长度非常短(短期记忆力很差),稍微多聊两句就翻篇了,于是业内就卷了一段时间的上下文长度,但是光上下文长度还不够,有些东西我们还是希望它永远不要忘记,所以还有另一个方案叫做RAG(索引增强生成)。
简单的理解就是把大模型需要记忆的知识,事先存在一个外部的,一个向量数据库中,每一次你需要的时候,再去里面找有没有相关的内容,像是把大模型开了一个长期记忆的小外挂,还顺带能减少他一些乱编的幻觉问题,但是Agent在执行过程中所产生的这些东西也需要被记住,所以中途呢,就的对前面发生的事情做一定的总结存起来,自己偶尔要回顾一下之前的这些内容,这样就形成了一个记忆模块。
研究人员也在研究尝试新方法,比如DeepSeek开发的NSA(稀疏注意力机制),也是想解决模型的一些记忆问题
Agent的发展现状
Agent的能力一直是在螺旋上升的,从23年开始研究人员就没有停止过,对Agent的探索和实验,从23年初GPT3.5刚发布,就有了AutoGPT、BabyAGI、斯坦福小镇,微软的TinyTroupe这些实验项目。
最成熟可用的要数编程Agent了,也都支持从一个需求出发,自己改、自己创建文件、自己部署网页之类的功能。其次就是Deep research这样的调查Agent,google的 investigation Agent,Grop的DeepSearch,以及智谱能操作手机的这种AutoGLM等等。
还有一些普通人用不上,但是在特定行业内用的非常好,比如医疗Agent,数据分析Agent,风险评估Agent。
普通人如何应对?
作为一个普通人,最近我看了很多AI方面的视频、文章,也自己体验了,写这篇文章也花了很多,最后说说我的一些思考。
UBI方案
ChatGPT4刚出来的时候,有人问,你们AI这么强大了,以后抢走我们的饭碗怎么办?
ChatGPT4回答说,你们人类可能要面临一波下岗潮,但是别担心,我们这些AI其实也是在帮你们打工。来听听我老板奥特曼的点子,他有个方案叫UBI,也就是全民基本收入。想象一下,我们这些AI辛辛苦苦赚的钱,最后还是要回到你们人类的口袋里,这个方案的玩法是这样的。建一个大大的基金,然后把那些拥有AI的土豪公司,每年把他们市值的2.5%捐给基金会。然后基金会就会像圣诞老人一样,把钱派给大家,将来美国的老百姓,每人每年能分到,折合人民币就是多块。哇塞是不是听着就心花怒放?别担心钱不够花,因为随着我们AI的不断进步,物价会每两年减半,所以将来上班完全就是因为你热爱,不是因为你需要,想要工作,排队去吧,这样的未来是不是有点小激动?嘿嘿期待吗?
大家对这个回答满意吗?
反正我是怀疑态度。这好比把我你我的命运托付给AI,期待AI能永远善待我们一样。更确切地说,是期望那些控制AI和算法的人会善待另一类人一样,也许会但可能不是全部。想想人类是如何对待同类的,想想乌克兰的悲剧是如何造成的?以及有谁在乎巴勒斯坦人的处境?唯一的解决办法是每个人自己能够独立思考,多思考,再深入思考。
我们生活在一个和平的中心化的世界里,以为一切都是理所当然,网购是安全的,企业不会收集个人隐私,和平是常态。其实不一定。今年2月4日我遇到一件恶心的事情,
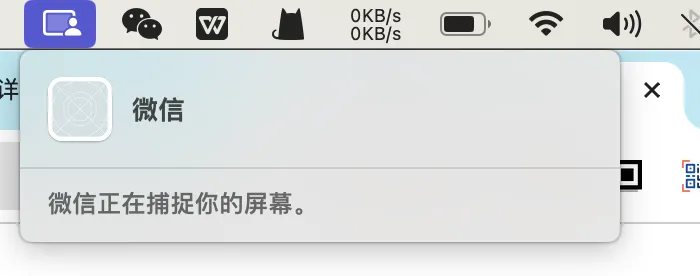
我不知道为什么,好像一整天都被微信监控了,怎么折腾也找不到腾讯的人工客服,把这个事情分享给大家看看。其实也不是腾讯一家这样干,在互联网企业工作的码农呀产品呀都懂。
其实微信有个很好用的功能--青少年模式(现在叫未成年模式),我基本都开着,因为这样可以免去很多游戏、广告、短视频的骚扰。
AI能否取代程序员?
这是个比较扎心的事,但还是要去思考。
先聊下AI会取代传统的软件吗?
我想应该不至于,现阶段的AI容易出错,而传统的软件是确定性逻辑,经过长期验证得到的方案,准确性、安全性及性能是AI代替不了的。但是那些山路18弯,维护成本极高的软件可能会被颠覆。
毋庸置疑,肯定会取代一部分程序员!
计算机编程语言的出现本身就是一个放大器,放大了那些会计算机懂技术懂编程的人的能力。比如说互联网,卷死了无数的实体店,餐饮小吃店等。比如电商项目,中国这么大的市场,无数的电商项目以失败告终,成功活下了还有利润的也就三四家,也就是只要留下这些会编程能力的程序员维护项目就行了。 AI更是一个放大器,会用AI的人无限放大自身的能力,未来的公司可能越来越小型化,三五个人就能做好一门生意。
但是也无法完全取代程序员,原因如下:
- 现阶段的AI,存在一些不能解决的编程问题,
比如环境搭建、兼容性问题、疑难杂症的bug,仍旧是解决不了。虽说不懂编程的人,也可以使用AI做出一个网站,做一个小游戏等,但都还局限在一些小东西小项目。因为不懂编程语言,对项目代码不理解,不知道怎么改,可能就有问题解决不了。就算项目能够成功上线,但是在性能、体验、安全以及并发等方面无法保障。
- 往往越大的项目,AI的出错率越高。
对于复杂的项目,AI很难理清楚各部分代码之间的逻辑,所以需要人类程序员对需求进行拆分,尽量一次处理一个小模块小需求,所以并不是有了AI就不需要学习编程了,只是说我们可以把更多的精力从细枝末节的编程语法转移到系统架构和需求分析上来。
- 成本问题。
Cursor推出的BigFinder功能很贵,而且不一定能解决问题。
我自己的电脑,用Ollama跑过一些模型,参数只是大一点点,AI的回复不是慢那么一丁点,而是基本卡死,我猜想大语言模型智力每增长一点,需要GPU性能的指数倍增长,人脑应该仍旧存在某些方面的优势。
- 信任问题--AI不能承担责任
代码作为公司的核心资产,每一行代码都需要审查推敲的。需要有人去监督它不搞破坏;需要有人如何处理AI的错误以及带来的风险和后果;需要懂AI的人才能发挥AI更大的能力。
我们生活在一个机器比人类聪明的时代。随着AI的进化,理论上机器可以任何事情,但是人类不可能放任AI去做任何事情。除了监督它干活,还要监督它是否有自我意识,一旦AI有了自我意识,这个代价没有人能承受的起!
科技发展的双刃剑
我想直言不讳的说,科技进步的过程就是贫富分化加大的过程。这是也历史发展的必然。
作为北方人我拿种植小麦来举例。
我小的时候是见过用牛耕地,牛粪撒地里、拔草、镰刀割小麦、用驾车+床拉小麦、打场地,牛拉石滚分裂秸秆和小麦种子,扬场得到干净的小麦种子,最后装入袋子,用驾车拉回家。
而如今农村已经很少有人在家种地了,基本被都承包出去了,一个村的土地两三户人家承包了,旋耕机、播种机、收割机,三个机子搞定一年两季的农作物,这期间顶多用低空飞行器撒几次农药。
以前种地确实很辛苦,但种地不花钱呀,种地的收入可以买的起衣服日用品,交得起学费(所以敢生娃呀)。现在呢?生活质量确实好了,但是种地是养不活自己了,为什么呢?
假如你们村张三买了一台机器,之前用牛耕地,两头牛一天也就耕两三亩地,而机器只要加点油,一天可以耕100亩地,你会怎么选呢?如果继续用牛耕地,人家张三都可以把村门口的那座山都给开垦了,种更多的庄稼。到了秋天,粮食多了,又会怎样?物以稀为贵,粮食降价为之前的一半,你的收入减半,人家张三的收入增长500%。于是村里的村就会找张三商量,你帮我耕地吧,我给你钱,也有人会选择买一台机器。大家都争着抢着买机器,粮食的产量更多了,粮食继续贬值,,,
那最后钱被谁赚走了?不是农民,不种地做生意的人买粮食便宜了,他们肯定能赚了但只是微乎其微,还有就是生产机器的人和发明机器的人赚了,当然也不会是他们中的全部,只有那些最先发明机器的人和做出来的机器性价比最好的公司把钱赚走了。你在想想互联网、平台经济是不是这个理?有做出行业务的公司宣称“让网约车司机有尊严的选择”,但实际在他的平台上跑网约车也是要抽取近30%的抽成。司机还有7成呢,但别忘了出租车司机还有购车或用车成本、要充电、要交房租、要吃饭以及故障问题等,这样算下了挣到的钱真少的可怜。外卖、网店也是如此。
工业革命,不管怎么说机器要工作是需要人来操作的,而AI革命,抢走的是你我的饭碗!
说这些并不是煽动对立啥的,我是在启发你思考。就算美国人不发明计算机也会有人发明出计算机,发明出编程语言;就算美国和中国都不搞人工智能也会有其他国家去搞,到时候恐怕是所有中国人都要跟着过苦日子,弄不好还会是第二个乌克兰,与其如此,不如让一部分聪明的人富起来,我猜这是国家的想法。
普通人如何应对
不可否认有部分人能从AI技术革命中赚到更多的钱,但AI时代成功是极少数人的。比如哪吒2爆火,大街小巷的孩子都要闹着要看哪吒2,结果电影院赚钱了,不过可能仅仅是短期,制片人才是最大的赢家。看了哪吒2的人就没有时间去看其他电影了,更多的制片人是赚不到钱的。我不是对哪吒2的制片人有意见,我只是在启发你思考,如果没有哪吒2,可能是欧美人出了一部英汉双语的动画片或其他电影,赚了钱的美国人只会在美国消费,促进美国科技的发展。但作为父母,我肯定不会让自己的孩子去跟风、从众。
AI时代只需要少部分精英人士去工作,去提升AI的能力,再加上少数聪明的人进行内容营销,助长AI操作机器,改进算法去获利,大多数人可能要从事服务业或者没有工作。我们生活在一个机器比人聪明的时代,我们又如何应对才能安度晚年?
从国家发展的宏观视角来看,大众消费能够推动经济繁荣,促进科技创新,从而国家富强起来;而从个人微观角度讲,只有适度消费才能积累到财富。从我个人角度讲,我考虑的是你的角度,所以写这篇文章说与你听!
科技进步其实也能享受到时代的红利的,比如前几年有些大厂程序员,赚的拼盆满钵满,也有些人通过电商销售更多的产品,也赚到了很多钱,即便是没文化在工厂拧螺丝,其实也能赚一些钱,只不过很多人没有留住这到手的财富乃至泼天的富贵,,,比如:
- 前几年买房的,人家都买房了,房子一直在涨,国家不会让房子跌
- 做生意需要一辆好点的车,这样有面子,才能谈成生意
- 也有人为了追求人车一体的体验,结果一车毁三人亡
- 月入三千也要买个万元的手机
- 都知道吸烟喝酒有害健康,但还是有很多人一如既往,把钱留给了医院
- 有些人大学浑浑噩噩点了四年外卖,没想到毕业后成了外卖跑腿小哥,他们更没想到的是,美团已经在试点机器人送餐了,萝卜快跑也在路上。
- 结婚几乎是所有农村小伙子这一生中最风光、最体面的人生巅峰时刻,也是这一生最奢侈、代价最大的一次消费。
- 提高情商,一方面让自己免于不必要的麻烦和危险,另一方面帮助我们争取本应得到的利益。
归其原因,很多人小事上(吃饭、买菜)精挑细算,却在大事上(结婚、买房、买车、银行理财)思考的甚少。
一方面是因为学校教的很多东西不接底气,应试教育固定答案让我们缺少思考,教科书上说,科技进步人们的生活会越来越好,中国改革开放后的飞速发展,人民收入的日益提高。如果你信以为真,以为国家强盛了,将来就不需要工作了,开始今朝有酒今朝醉,然后月月光甚至一屁股负债,等到你三四十岁了,认识到社会运作的规律,一切都晚了。其实大家应该能发现年轻人跟中年人、老年人有的完全不同消费观,老人不大可能把钱花在吃穿上,但也可能因为买了某银行理财、某保险或者被孩子挥霍掉。
另一方面是父母不懂,这是主要原因。孩子是白纸会一点一滴的学习父母说话、做事、为人处理的习惯和方法。有的父母期望孩子找到更好的工作,挣更多的钱,做他们做不到的事情,殊不知会造成了孩子的叛逆或误入歧途,尤其是过分的追求名和利!有的父母觉得人生在世须尽欢,莫使金樽空对月,教育孩子也是对酒当歌人生几何。个人以为这种肤浅的认知还不如前者的教育方式。起码前者教育出来的孩子在多次头破血流之后还会思考、会后悔、会改变、会成长,而后者的孩子可能将一直沉迷于花田酒地、短视频、游戏当中,这种安乐的状态使他们一事无成,然后失去所有。
我贴这张图不是歧视穷人(上面是网上找的图,标注也不是我标的),事实上我自己也是穷人,人生拿到一手烂,好在现在搞懂了社会的运作和发展规律。说了这么多,我还是想表达,尽管我们生活在一个机器比人聪明的时代,但是仍需要学习知识,因为我们决策还是依靠自己的个人经验和知识体系,这会让我们能正确的分辨什么是真实的,什么是虚假的,进而趋利避害。然后如果能够管控自己的欲望,机器也拿我们没办法,也抢不走我们手中的资源和筹码。
下面的内容是说给有孩子的父母听的。
不管怎么讲,现在人类在寿命面前还是平等的,未来不好说。大部分父母都应该会想把更好的留给自己的孩子,有条件的家庭可以给孩子多留一些,但是必须进行必要的家庭教育,如果只养不教育,就算留给他金山银山也没用。还有一点是还是要学习知识,不是不花钱,没有欲望就不会被收割,理财和金融的知识还是要学习的。现在存钱的利益越来越低,以后甚至是零利息、负利息,要知道国家每年M0、M1的增长在8%-12%,你的钱是变多了,但是购买力下降了。我不是鼓励你炒股,我仅仅是说有经济条件的需要去学习一下金融知识,我再引用北大教授肖臻的名言:“我们都说知识改变命运,但对知识的一知半解反而会使你的命运更差”。我个人也有一些金融的理论知识,有机会再单独写篇文章吧,现在有更重要的事情要做。
如果真的没有条件,我也给你支支招,科技进步虽说找工作更难了,但是也不会全都是坏事,你且听我来分析。我们现做一个最悲观假设,设置真的找不到工作了,用初传统牛耕方式种地,假设夫妻两口养四头牛承包20亩地,每年也能收入5万,算法如下。
- 承包20亩地,800元每亩,开销
- 养四头牛,用传统的方式喂牛(麦秸秆+青草+一点辅料),牛粪施肥
- 假设一年产2头小牛,小牛2年长大,这样每年卖一头牛
- 假设一亩地产800公斤,
- 注:牛粪肯定没有化肥高效,用化肥每亩能收1000公斤。
- 平时种点菜,养点鸡鸭鹅,一年买点调料,衣服 开销就算1万
- 合计:
但情况肯定不会那么坏,要学会算账,种一些投产比高的作物,使用新的生产力提高你的效率,从而增加收入。
另外科技进步真的可能每隔几年物价减半,中国是生产大国,一有通胀的苗头,生产力拉满,不大可能有通胀发生。而且只要愿意还是能够买到足够便宜的商品。比如很多人都觉得拼多多的东西够便宜了,其实不然,咸鱼上还可以更便宜。我现在的手机就是咸鱼上买的,350元,性能不比两千块钱的新手机差,因为后壳烂了一个角,我觉的没啥,买个手机套就是,如今已是算力过剩的时代,十年前的 MacPro 现在用依旧不卡,手机也是只要你不用来玩大型游戏,也感知不到卡顿,要啥自行车?在咸鱼上买一些家用电器如微波炉、冰箱、洗衣机、床(组装的)还是不错的;但是也不是说什么东西都是咸鱼上买好,有些东西已经不贵了,你在咸鱼上买不但浪费时间,售后也是个问题,另外如果你生活在农村,这个咸鱼对你来说没用。下面还有一些建议:
- 如果一个人不吸烟不喝酒,不仅仅是每年能省下一笔钱的事,身体也会健康很多;
- 如果一个人作息规律,不熬夜,身体会少很多疾病;
- 如果能养成一个固定的生活习惯,可以免去生活中很多烦恼(如忘带钥匙、忘带身份证、找东西)。
- 如果你愿意饮食规律,能够接受清淡一些的食物,少吃一点点盐、酱油、味精、辣椒、腌制食品,这对于的肠胃、肾都好,甚至痔疮也消失了;
- 如果你早晚认真刷牙,坚决控制刷过牙后不吃东西,人到中年也不会有牙痛、牙流血的问题和花几千块钱种植一颗牙的烦恼。
人人都想着开源,开源哪有那么容易?而大多数人是没有人脉、资源、学历以及社会认知的,相反节流却是很容易实现的事情,就看你愿不愿意了。就算你愿意,做起来也是挺难的,,,
希望AI时代的你和我都过的很好!希望我们是朋友一起应对AI时代的挑战!
本文作者:郭郭同学
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!