目录
本文系统介绍和总结软件包管理、磁盘管理、网络管理
软件包管理
Linux下面的软件包格式为:
rpm格式(红帽系列系统,CentOS,麒麟系统)或deb格式(Debian,Ubuntu)
Linux常见的安装软件方式
| 方式 | 说明 | 应用场景 |
|---|---|---|
yum/apt | 通过网络下载软件包,并进行安装, 如果有依赖自动下载依赖并安装. 自动 | 大部分场景,没有网络可以自建yum软件仓库,内网使用 |
rpm/dpkg | 手动下载rpm包,手动安装rpm包,缺少依赖需要自己解决 | 没有网络,勿删除软件包,依赖较少 |
| 二进制安装 | 类似于绿色软件,解压既用,可能需要准备环境,并非每个软件都有,一般是服务,数据库,k8s,promethues监控. | 软件进行自定义,增加功能 |
| 编译安装 | 可以自定义安装,比较漫长,缺少依赖自己解决 | 软件进行自定义,增加功能 |
安装方式推荐
- yum优先
- 其次rpm包
- 接着二进制
- 最后编译安装
wget
在学习rpm命令安装软件包之前,需要先了解下wget下载文件(软件包)的命令
wget下载指定内容,默认下载到当前目录
-P下载到指定目录,目录不存在会创建--no-check-certificate下载地址https,加上这个选项,下载失败。
软件包可以到一些镜像站去找 比如 清华软件镜像站
以zabbix软件为例 找到下载地址
执行命令
wget --no-check-certificate -P /server/tools/ https://mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/6.0/ubuntu/dists/trusty/Release.gpg
rpm安装
rpm命令的选项
-iinstall-v显示过程-h人类可读-vh显示进度条
| rpm命令 | 选项及含义 |
|---|---|
| 增加-安装 | -ivh (-i install ) xxxx.rpm |
| 查看-检查 | -qa (query all) 查看软件包是否安装-ql 查看软件包内容 |
| 修改-升级 | -Uvh升级软件包(如果软件包不存在,相当是ivh安装) |
| 删除 | -e删除软件包 |
安装
案例 在Centos上安装rpm包
- 在清华软件源上找到zabbix的下载地址
- 下载软件包
wget --no-check-certificate -P /server/tools/https:mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/6.0/rhel/7/x86_64/zabbix-agent2-6.0.0-1.el7.x86_64.rpm - 由于安装失败根据提示安装依赖
yum install -y pcre2 - 安装软件包
rpm -ivh zabbix-agent2-6.0.0-1.el7.x86_64.rpm
查询
rpm -qa zabbix-agent2查询zabbix-agent2软件是否安装npm -qa |grep zabbix但是推荐模糊查找 利用管道+grep进行过滤
软件包不等同于命令
- 一般情况下一个软件包中有1个命令,
tree,telnet软件包。 - 更多情况中1个软件包下面可能有多个命令,
lrzsz(rz,sz),net-tools.
rpm -qf 命令或文件的绝对路径 ,用于查找已经安装的命令或文件属于哪个软件包。
也可以使用 yum provides命令查找即可。
sh一个软件包中可能包含多个命令. 直接通过yum安装就会失败 cowsay 软件包 > cowsay命令 > animalsay命令 > cowthink命令 yum install -y animalsay 则安装失败. 原因: yum/rpm 安装的是软件包,而不是软件包中的命令或文件. 如何通过命令,文件找出归属的软件包(软件包要已经安装) rpm -qf /sbin/ifconfig
升级案例
将 zabbix-agent2 从 6.0.0 升级到 6.0.7 版本
shwget -P /server/tools/
https:mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/6.0/rhel/7/x86_64/zabbix-agent2-6.0.7-1.el7.x86_64.rpm
[root@myServer ~]# rpm -Uvh /server/tools/zabbix-agent2-6.0.7- 1.el7.x86_64.rpm
警告:/server/tools/zabbix-agent2-6.0.7-1.el7.x86_64.rpm: 头V4 RSA/SHA512 Signature,
密钥 ID a14fe591: NOKEY
准备中 ################################# [100%]
正在升级/安装
1:zabbix-agent2-6.0.7-1.el7 ################################# [ 50%]
正在清理/删除
2:zabbix-agent2-6.0.0-1.el7 ################################# [100%]
[root@myServer ~]# rpm -qa |grep zabbix
zabbix-agent2-6.0.7-1.el7.x86_64
删除
- 删除对应的软件包(rpm安装或yum安装),其他方式(编译,二进制)无法删除。
- yum,rpm安装软件,删除软件的时候, 建议通过
rpm命令删除, 非必须不推荐删除软件. - 删除软件包,-e(erase)
shrpm -e 软件包 rpm -e zabbix-agent2 rpm -qa |grep zabbix
编译安装
有时候 yum安装不上,rpm没有包,这时候只能使用编译安装了
编译安装三部曲: 配置 --> 编译 --> 编译安装
以Centos系统安装cmatrix为例,编译安装如下
- 安装依赖软件包、工具。。。
- 上传压缩包
scp -P xx localfile remote_username@remote_ip:remote_folder - 解压压缩包
tar xf cmatrix-1.2a.tar.gz - 进入压缩包
cd cmatrix-1.2a - 安装依赖
yum install -y ncurses-devel(cmatrix的依赖)
- 上传压缩包
./configure配置 安装到哪个目录(默认是/usr/local/下面),开启或关闭功能。./configure输出一堆内容, 通过echo $?检查前一个命令执行的结果,如果是0 则表示成功了,否则是出错了。
- 运行
make命令 进行编译 (代码 --》 命令)echo $?检查结果, 若有报错,可能要安装依赖,依赖安装完成要从重新解压压缩包开始执行后续命令
make install安装(创建目录,复制配置,复制命令, 复制到指定目录)- 运行
cmatrix命令,检查结果, - 清理安装包、解压目录
yum软件包管理
- yum是红帽系列系统中默认的软件包管理器。替我们下载指定的rpm包,替我们安装,安装过程中有依赖,下载安装依赖。
- 推荐安装 命令补全增强工具
以yum install -y tree为例分析yum软件安装的执行过程
- 检查本地是安装tree软件包以及tree的依赖
- 解析
/etc/yum.conf文件- 这个是yum的配置文件,决定tree如何安装(是否保留配置?存放到哪里)
- 据本地配置的yum源的地址(
/etc/yum.repos.d/)进行请求(相关软件包tree,依赖软件包)。 - 如果yum源存在软件,则会通知yum进行下载,rpm包就被下载到yum缓存目录中。
- 软件包和依赖(如果有)都下载OK,则开始安装。
- 安装完成删除刚刚下载的rpm包(默认)
yum源的配置
由于众所周知的原因,需要修改yum源为国内的源(就是
/etc/yum.repos.d/文件夹里面的文件),这样解决了软件包下载问题。
修改yum源的一些命令
shyum repolist #repo源 list列表
中间的略过
源标识 (repo id) 源名称 状态
!base/7/x86_64 CentOS-7 - Base - mirrors.aliyun.com 10,072
!epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 13,747
!extras/7/x86_64 CentOS-7 - Extras - mirrors.aliyun.com 515
!updates/7/x86_64 CentOS-7 - Updates - mirrors.aliyun.com 4,425
repolist: 28,759
提示
- 目前这里可以看出有
base,extras,updates,epel4个yum源 base,extras,updates是系统默认的yum源 (修改CentOS-Base.repo文件)epel是额外yum源 (修改epel.repo文件)
设置系统的yum源为阿里云
shhttps:mirrors.aliyun.com/
进入网站 选择centos
1. 备份已有yum源的配置文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2. 配置系统默认的源,改为阿里云的。
使用wget或curl 下载阿里云的yum源的配置文件到/etc/yum.repos.d/目录下
wget -O /etc/yum.repos.d/CentOS-Base.repo https:mirrors.aliyun.com/repo/Centos-
7.repo
-O 下载并改名,存放到指定目录中。
3. 修改了base,extras,updates是系统默认的yum源,改为了阿里云。
增加epel源
#1. 备份(第1次使用,提示文件不存在)
mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup
mv /etc/yum.repos.d/epel-testing.repo /etc/yum.repos.d/epel-testing.repo.backup
#2. 增加系统的epel源(企业级Linux的额外的软件包 yum仓库)
wget -O /etc/yum.repos.d/epel.repo https:mirrors.aliyun.com/repo/epel-7.repo
#3. 检查
yum install -y sl cowsay
yum源配置文件解读
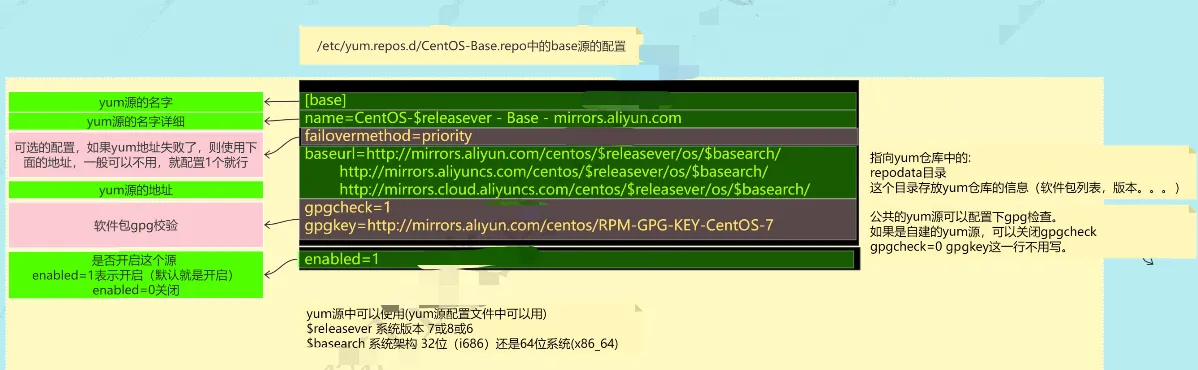
配置文件格式
ssh[base] 这个源的名字 name=CentOS-$releasever - Base - mirrors.aliyun.com failovermethod=priority baseurl=http:mirrors.aliyun.com/centos/$releasever/os/$basearch/ http:mirrors.aliyuncs.com/centos/$releasever/os/$basearch/ http:mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/ gpgcheck=1 gpgkey=http:mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
注:
- $releasever 代指Centos系统版本,比如7
- $basearch 代指芯片类型 比如
x86_64
按照这个格式你可以修改yum源 清华源、腾讯源
| yum源配置文件详解 | |
|---|---|
[base] | yum源的名字 |
| name= | 说明信息 |
| baseurl= | yum源地址,打开后要看到repodata目录,这是yum配置的核心 |
| enabled=1 | 是否开启这个yum源 |
| gpgcheck=1 | 开启软件包检查,未来自建yum仓库可以关闭 |
| gpgkey | 用于检查的秘钥. 如果关闭检查gpgkey省略 |
yum命令配置文件
| /etc/yum.conf yum命令的配置文件 | 说明 |
|---|---|
keepcache | =0关闭缓存,软件下载安装后自动删除rpm包。 =1开启缓存,软件下载安装后保留rpm包。(自建yum源) |
| cachedir | yum下载软件包的缓存目录, /var/cache/yum/$basearch/$releasever |
| logfile | yum命令的记录 /var/log/yum.log |
测试 yum源是否生效,可以通过重新安装软件即可
例: yum reinstall -y tree cowsay
注意
生产应用的建议keepcache
未来没有网络的环境,可以找个有公网的主机,开启keepcache,下载各种服务软件. 保留缓存,通过缓存的rpm包进行安装.
yum命令
| yum命令 | 格式与说明 |
|---|---|
| 增 | yum install -y tree-y 遇到有yes/no的时候一直选择yes |
| 查 | yum provides 内容yum search all 内容yum repolist 查看源列表 |
| 删除 | yum remove 删除软件包及依赖yum clean all 清空缓存 |
| 改 | yum update/upgrade |
注意
尽量不要使用yum remove命令删除软件,删除的时候可能会把依赖删除掉
如果要删除使用 rpm -e
补充 linux的一些必备软件
Ubuntu系统软件包管理
对标Centos系统简单说一下Ubuntu系统的软件包管理
apt/apt-get-->yumdpkg-->rpm
修改软件源
vim /etc/apt/sources.lis
shdeb https:mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src https:mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb https:mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src https:mirrors.aliyun.com/ubuntu/ focal-security main restricted universe
multiverse
deb https:mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe
multiverse
deb-src https:mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe
multiverse
# deb https:mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe
multiverse
# deb-src https:mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe
multiverse
deb https:mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe
multiverse
deb-src https:mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe
multiverse
编辑完成一定要运行
apt update 命令,用于生成本地apt缓存,如果不做则无法安装软件。
安装与检查软件
apt install -y soft1 soft2 ...
-y跳过确认(一直选择yes)
检查软件
| debian(ubuntu) | 红帽(Centos,麒麟) | |
|---|---|---|
| 检查是否安装 | dpkg -l | rpm -qa |
| 安装 | dpkg -i | rpm -ivh |
| 检查软件包内容 | dpkg -L | rpm -ql |
| 删除 | dkkg -r | rpm -e |
进程管理
- 程序 安装包,程序代码,app,存放在磁盘上面
- 进程 运行起来的程序,命令,服务(远程连接服务,网络服务)都可以称作进程。 运行在内存中
- 守护进程 守护进程, 一直运行的进程. 也可以叫做服务.
异常的进程
- 僵尸进程
当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程
僵尸进程:由于各种原因导致某个进程挂掉了,但是进程本身仍然存在,还占用着系统资源,这种异常进程僵尸进程
可以通过top 或 ps aux | grep Z 命令查看进程
如何解决僵尸进程呢?
找出僵尸进程的上级进程,结束掉即可(如果上级进程是主进程,则需要重新Linux系统)
我这里准备了一个C语言文件模拟僵尸进程
zombine.c
sh# include <sys/types.h>
# include <sys/wait.h>
# include <errno.h>
# include <unistd.h>
# include <stdlib.h>
# include <stdio.h>
# include <string.h>
/**
用于模拟僵尸进程的代码
*/
int main(int argc, char *argv[])
{
pid_t pid;
pid = fork();
if(pid == 0) {
int iPid = (int)getpid();
fprintf(stderr, "I am child, %d\n", iPid);
sleep(1);
fprintf(stderr, "child exists\n");
return EXIT_SUCCESS;
}
int iPid = (int)getpid();
fprintf(stderr, "I am parent, %d\n", iPid);
fprintf(stderr, "sleep...\n");
sleep(600);
fprintf(stderr, "parent exists\n");
return EXIT_SUCCESS;
}
上传到服务器保存为zombine.c
编译gcc zombine.c -o zombine.bin
运行 ./zombine.bin
新开一个窗口,通过top命令查看
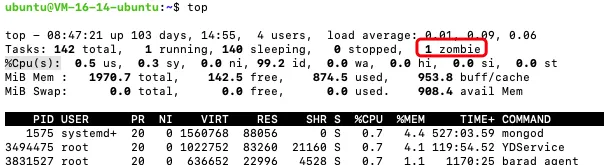
ps aux | grep Z 这个命令也行

使用kill kill -9 无法终止进程(老窗口没变化)

需要通过终止僵尸进程的父进程才能解决
pstree -p | grep pid

- 孤儿进程
- 孤儿进程指的是在其父进程执行完成或被终止后仍继续运行的一类进程。
- 孤儿进程会被系统直接接管.(systemd进程)
进程监控指令
ps静态:ps查看当前瞬间进程状态,一般用于临时检查或取值.top动态:top动态,交互,整体查看系统状态,负载,僵尸进程,cpu,内存. 类似于windows任务管理器.
ps -ef
- UID 表示进程属于哪个用户
- PID 进程id号,大部分都是随机
- PPID 父进程的id号, pstree -p查看详细关系
- CMD 进程名字
ps -aux
- 比
-ef多了一些列信息,CPU使用率,内存使用率,占用内存大小,进程状态
ps -aux每一列的含义
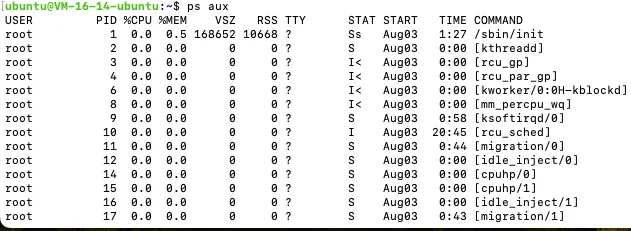
| 列 | 描述 |
|---|---|
| 第1列: User | 进程属于用户 |
| 第2列: PID | 进程号(子进程号) |
| 第3列: %CPU | cpu使用率 |
| 第4列: %MEM | 内存使用率 |
| 第5列: VSZ | 进程占用虚拟内存大小 (KB) |
| 第6列: RSS | 进程占用物理内存大小 (KB) |
| 第7列: TTY | 用户使用终端(用户连接进来后,系统创建) |
| 第8列: STAT | 进程状态 |
| 第9列: START | 进程启动时间 |
| 第10列: TIME | 进程占用CPU时间 |
| 第11列及最后: COMMAND | 进程名字(命令,选项 ) []括起来的是内核进程, 其他是系统进程 systemd pid是1第1个进程. |
进程的状态
进程的状态由基本状态+附加组成
| STAT基本状态 | 描述 |
|---|---|
R(running) | 运行中 |
S | 可中断进程(可以随时停止) |
T(terminate) | 进程被暂停(挂起) ctrl +z |
D | 不可中断进程(进程正在进行IO读写) |
Z(zombie) | 僵尸进程,异常的进程 |
| STAT状态+符号(附加状态) | 描述 |
|---|---|
s | 进程是控制进程, Ss进程的领导者,父进程/主进程 |
< | 进程运行在高优先级上,S<优先级较高的进程 |
N | 进程运行在低优先级上,SN优先级较低的进程 |
+ | 当前进程运行在前台,R+该表示进程在前台运行 |
l | 进程是多线程的,Sl表示进程是以线程方式运行(与程序) 使用多线程可以让服务或软件支持更改的访问,但是需要软件支持。 |
常见的进程状态
R+前台运行中进程R后台运行进程S可中断进程(大部分进程)T后台挂起的进程(说完挂起命令就懂了)D不可中断进程(io进程)Ss可中断进程(普通)管理进程S<可中断的高优先级进程Ssl可中断的多线程的管理进程Z僵尸进程
top命令默认是个交互式的命令,可以展示系统负载信息,进程信息,cpu,内存信息。类似于Windows任务管理器
top命令格式
top命令案例
- 过滤出crond进程信息
shps -ef |grep crond
# 或
ps aux |grep crond
# 通过grep -v 排除
ps -ef |grep crond |grep -v grep
# 通过wc配合使用统计进程数量
ps -ef |grep crond |grep -v grep |wc -l
根据过滤结果,随时调整过滤的命令条件
ps -ef |grep '/usr/sbin/sshd'
如何让一个进程在后台运行? --> &
ps -efL 加个L就可以看线程信息,但没有pstree命令直观
free -h 查看内存
- 按照树形结构查看进程信息
shpstree
pstree -p #显示树形结构并输出pid.
ps auxf #也可以展示部分所属关系,没有pstree直观。
- 根据要求取出ps命令结果中部分内容
sh#通过awk取列
ps aux | awk '{print $1}'
ps aux | awk '{print $2}'
ps aux | awk '{print $3}'
ps aux | awk '{print $1,$3}' #第1列和第3列
#ps命令的选项,输出指定的内容
ps axo user,%cpu,stat
ps axo user,%cpu,stat,cmd
#awk写法 排除第1行,从第2行开始
ps aux |awk 'NR>1{print $1,$3}'
# ps不输出每一列的标题.
ps no-heading axo user,%cpu,stat
- 取出某一个服务(crond)的进程信息(pid,%cpu,%mem,command)
shps aux |grep 'crond' |awk '{print $2,$3,$4,$11}'
# 只使用ps命令也可以
ps no-heading -o pid,%cpu,%mem,command -C crond
- 取出所有进程中内存使用率最高的前5个进程
sh# 使用sort + ps
ps no-heading aux |sort -rnk4 |head -5
# 只使用ps命令方法
ps aux sort=%mem | head -5
默认是升序排序,指标前面加上-减号 (-%mem)表示降序排序。
- top基础使用与快捷键
shq 退出
默认3秒刷新1次, 空格立刻刷新.
P 默认按照CPU使用率排序
M 按照内存使用率排序
top输入z进入颜色模式
按 x 标记出当前是按照哪列排序.
shift + > 向右
shift + < 向左
#top命令升级版,支持鼠标操作
htop
- top命令的非交互模式
由于top的结果是动态的,使用top |awk 'NR==2' 无法获得预期结果,这里就需要-bn1 选项 top -bn1 |awk 'NR==2'

-b非交互模式-n输出的结果
通常 -bn1要一起使用
- 输出top命令第二行最后两列
shtop -bn1 |awk 'NR2' |awk '{print $(NF-1),$NF}
# 或
top -bn1 |awk 'NR2{print $(NF-1),$NF}'
后台管理
通常我们在服务器上启动一个程序都是在后台进行,这里我们聊一下后台进程
- 如何区分一个程序是前台进程还是后台进程?
根据前面所学 进程的辅助状态+ 可以区分进程是属于前台还是后台,有+号 是前台进程
- 如何让一个程序后台运行
| 说明 | 应用场景 | |
|---|---|---|
命令 & | 常用的后台运行方法 | 大部分时候使用这个即可 |
nohup命令 | 与第1个类似,会记录输出到文件中默认叫nohup.out | 如果想记录输出则可以用这个方法 |
先运行命令,然后按下ctrl + z(后台挂起), bg | 软件进入后台运行,按fg可进入前台 | 顽固软件ctrl +c 无法结束,可以通过这个方法结束它 |
| screen命令 | 通过软件创建空间,让命令在这个空间运行 | 稳定性比1、2好,因为ssh窗口如果意外终端掉,则这个窗口启动的进程也会dead |
- & 方法
shubuntu@myServer:~$ sleep 999 &
# 运行结果
[1] 2890668 # 程序进入后台运行并返回了进程号pid
ubuntu@myServer:~$
ubuntu@myServer:~$ ps aux |grep 2890668
ubuntu 2890668 0.0 0.0 5476 576 pts/0 S 16:43 0:00 sleep 999
ubuntu 2891033 0.0 0.0 6300 720 pts/0 S+ 16:44 0:00 grep 2890668
ubuntu@myServer:~$ ps aux |grep 2890668 | grep -v grep
ubuntu 2890668 0.0 0.0 5476 576 pts/0 S 16:43 0:00 sleep 999
ubuntu@myServer:~$
- nohup命令
与&功能一直,但它的特点是 会保留输出到一个文件中,默认是 nohup.out文件
nohup ping -c20 baidu.com & tail -f nohup.out
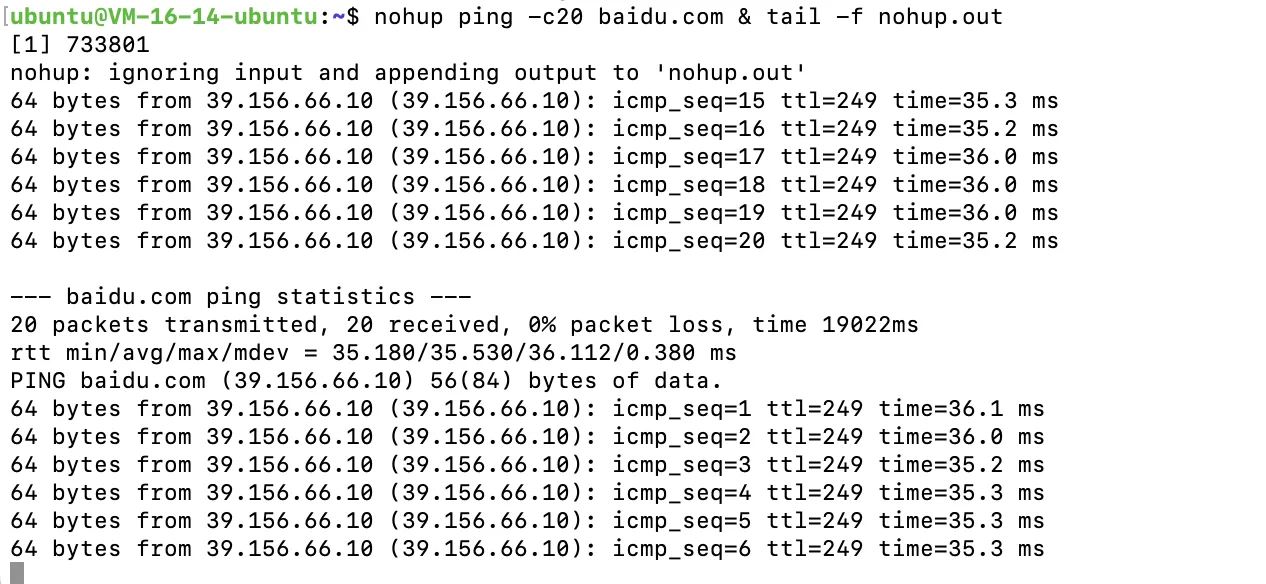
如果想输出到指定文件 使用命令格式如下
nohub 命令 > 新的文件 &
示例
nohup ping baidu.com >aa.txt &
- ctrl+z
这个快捷键在Linux下面表示让当前运行的命令或服务进入后台挂起,
- 如果转为后台运行需要再输入 bg,
- 如果是误触ctrl+z,可以通过fg让进程、命令回到前台。
- screen
相对于
&和nohub(ssh窗口异常,其窗口下运行的进程会dead),它更稳定,大文件备份可以使用这个命令来规范异常的情况。
sh#1. 运行screen
screen
进入screen虚拟窗口
#2. 执行命令
输入命令 ping baidu.com
#3. 退出screen窗口
退出窗口(异常推荐,正常退出)
ctrl + a 然后 d
#4. 查看screen窗口
查看
screen -ls
#5. 恢复 (断开后再次进入之前的screen窗口)
screen -r
彻底结束
ctrl + d
-
pstree -
进程之间的状态切换
- 我尝试了下在一个窗口运行的前台进程可以通过
ctrl+z,让进程进入后台挂起 - 通过
fg/bg命令可以让该进程恢复到前台/后台运行- 当前窗口只有一个进程时 直接
fgorbg否者fg %pidorbg %pid
- 当前窗口只有一个进程时 直接
- 在运行后台程序可以通过
fg命令回到前台 - 个人了解 如果不在一个窗口则无法进行该进程状态的切换,所以我推荐使用
nohup后台运行一个程序 +tail查看该程序的日志。
- 我尝试了下在一个窗口运行的前台进程可以通过
杀手三剑客
结束进程的命令有三个
killkill + 进程pid进行结束进程,常用pkillpkill+ 进程名称,模糊查找,慎用killallkillall + 进程名字,精确
kill pid默认发送结束信号.kill -9 pid发送强制结束信号. 慎用,千万别用kill -9结束数据库
负载
- 负载: 衡量系统繁忙程度指标
- 衡量是否繁忙: 单位时间内平均负载数值越接近cpu核心总数,系统的负载越高
- 预警:建议负载达到cpu核心总数的70-80%,超过该数值就要考虑服务稳定性了。
负载原理
如何理解平均负载?
平均负载是指单位时间内,系统处于可运行状态(R,S)和不可中断状态(D)的平均进程数,也就是平均活跃进程数
负载是衡量正在运行的进程的平均数
系统负载显示出什么信息?
负载过重有两方面的因素
- CPU占用: 可运行状态(R,S ) 的进程多
- IO占用:不可中断占用多
负载高如何排查
- 一般是通过监控软件发现系统负载高 相关命令
wlscpuuptime - 判断是CPO引起的负载高,还是IO引起的负载高
- CPU高: top中的us(user用户占用CPU) sy(system系统占用cpu)
- IO: top中wa(iowait) 磁盘io导致的负载高
- 如果是CPU导致的,排查出哪个进程导致的
ps aux命令 - 如果是IO导致的,排查出哪个进程导致的
iotop命令iotop -o只展示正在读写的进程
- 查看各种服务日志
- /var/log/secure
- /var/log/messages
- strace(显示过程)
- itrace(调用)跟踪进程
- 命令执行过程perf cpu分析
- read/write
服务管理
管理命令
systemctl 管理服务
- 开机自启动
- 管理正在运行的服务.
旧版本的系统:Centos 5.x 6.x 需要使用service 命令。
检查 sshd 远程连接服务状态
shsystemctl status sshd systemctl status 单个或多个服务名
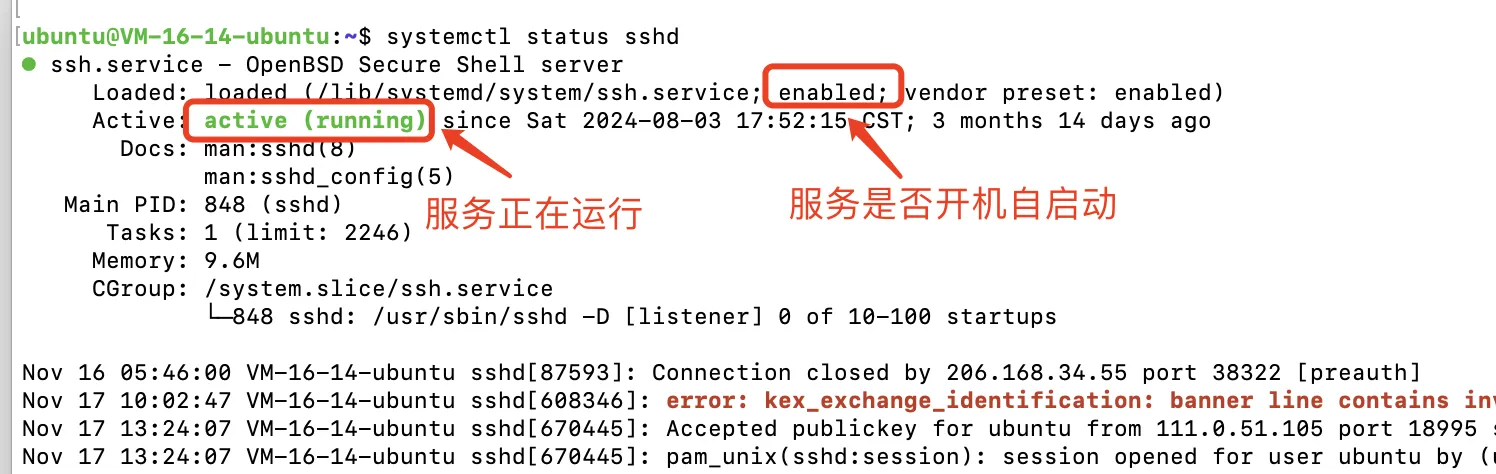
案例: 开启sshd ,并设置开机自启动
sh#开机自启动
systemctl enable sshd
#当前运行
systemctl start sshd #或者使用restart表示重启.
防火墙开启与关闭
sh#开机不会自动启
systemctl disable firewalld.service
#关闭正在运行的服务
systemctl stop firewalld.service
#服务永久关闭了
systemctl status firewalld.service
温馨提示:
如果无法自动补全命令的选项需要安装
bash-completion(默认源) bash-completion-extras(epel源)
yum install -y bash-completion bash-completion-extras #安装后重新登录即可。
指令小结
| systemctl | 命令 |
|---|---|
| 开机自启动 | systemctl enable xxxsystemctl disable xxx |
| 服务开启关闭重启 | systemctl start xxxsystemctl stop xxx systemctl restart xxx |
| 查看服务状态 | systemctl status xxx |
| 服务运行情况 | systemctl list-units |
| 服务运行情况 | systemctl list-units |
| 服务开机自启动情况 | systemctl list-unit-files |
Q: 服务无法使用systemctl管理实现,这时候怎么办?
这时候我们可以使用/etc/rc.local文件。
第1次使用需要授予执行权限 chmod +x /etc/rc.d/rc.local
然后把服务启动命令写入到/etc/rc.local 中即可。
后面我们可以手动书写systemctl配置或脚本
systemctl 可以关闭开启的服务有
- sshd 远程连接服务
- network 网络服务
- crond 定时任务
linux 运行级别
运行级别: Liunx不同状态,命令行模式,图形化界面模式(桌面).
| 运行级别 | 含义(centos7) | 含义(centos6) |
|---|---|---|
| 0 | 关机 | 关机 |
| 1 | 救援模式secure | 单用户模式,找回root密码 |
| 2 | 多用户模式 | 无网络的多用户模式 |
| 3 | 多用户模式 | 命令行模式,文本模式,工作默认模式 |
| 4 | 多用户模式 | 未使用待开发使用 |
| 5 | 图形化界面模式,桌面模式. X11 graphica | 图形化界面模式,桌面模式. X11 graphica |
| 6 | 重启 | 重启 |
sh# 查看运行级别命令
ll /usr/lib/systemd/system/runlevel*.target
#查看当前系统运行级别
systemctl get-default
#修改运行级别
systemctl set-default graphical.target #multi-user.target
可以通过 init命令,临时切换运行界别
init 6 重启
init 0 关机
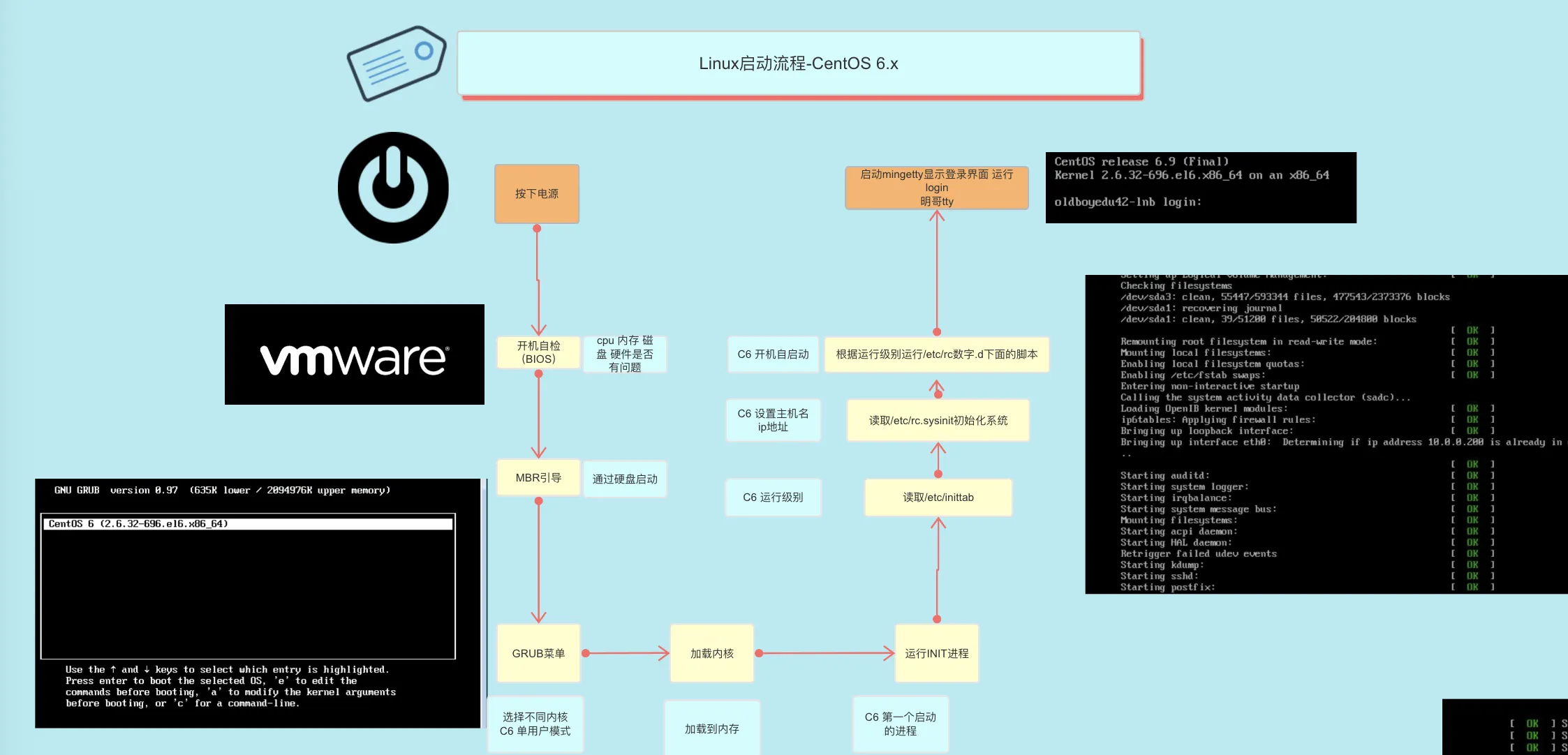
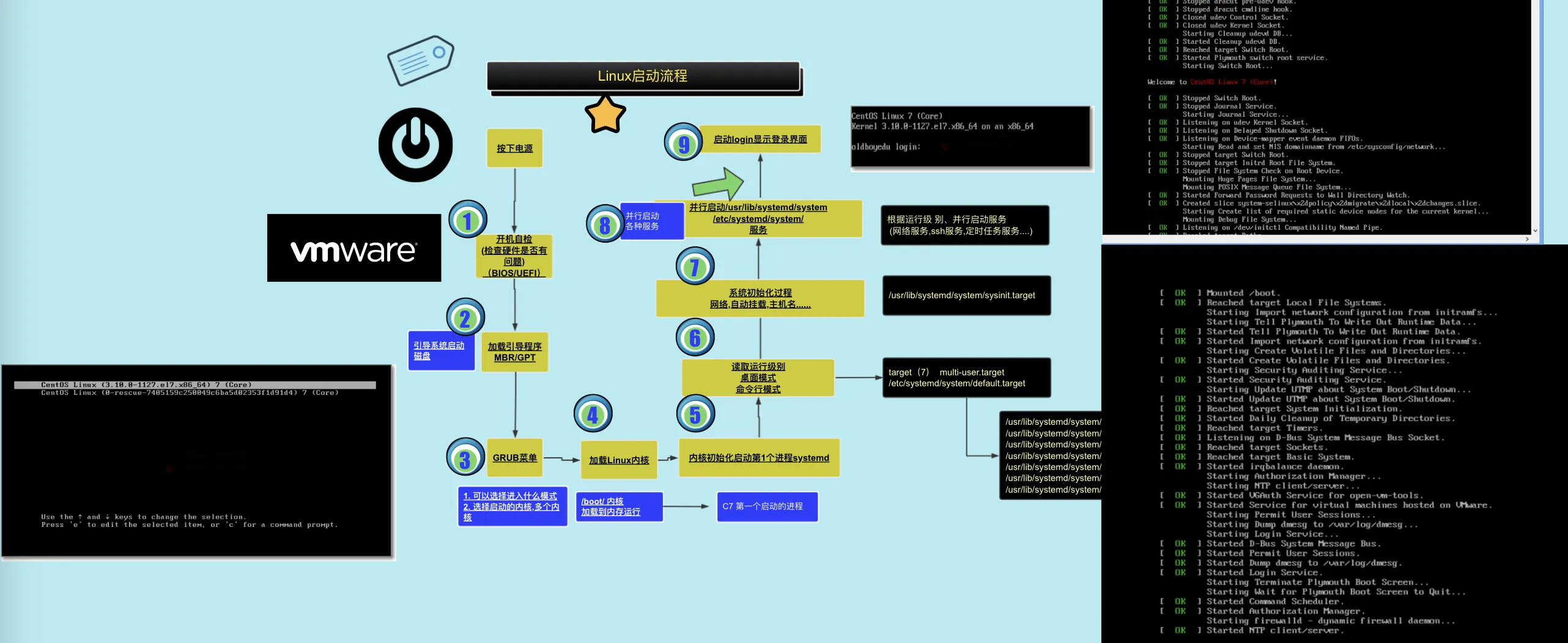
linux 的启动流程
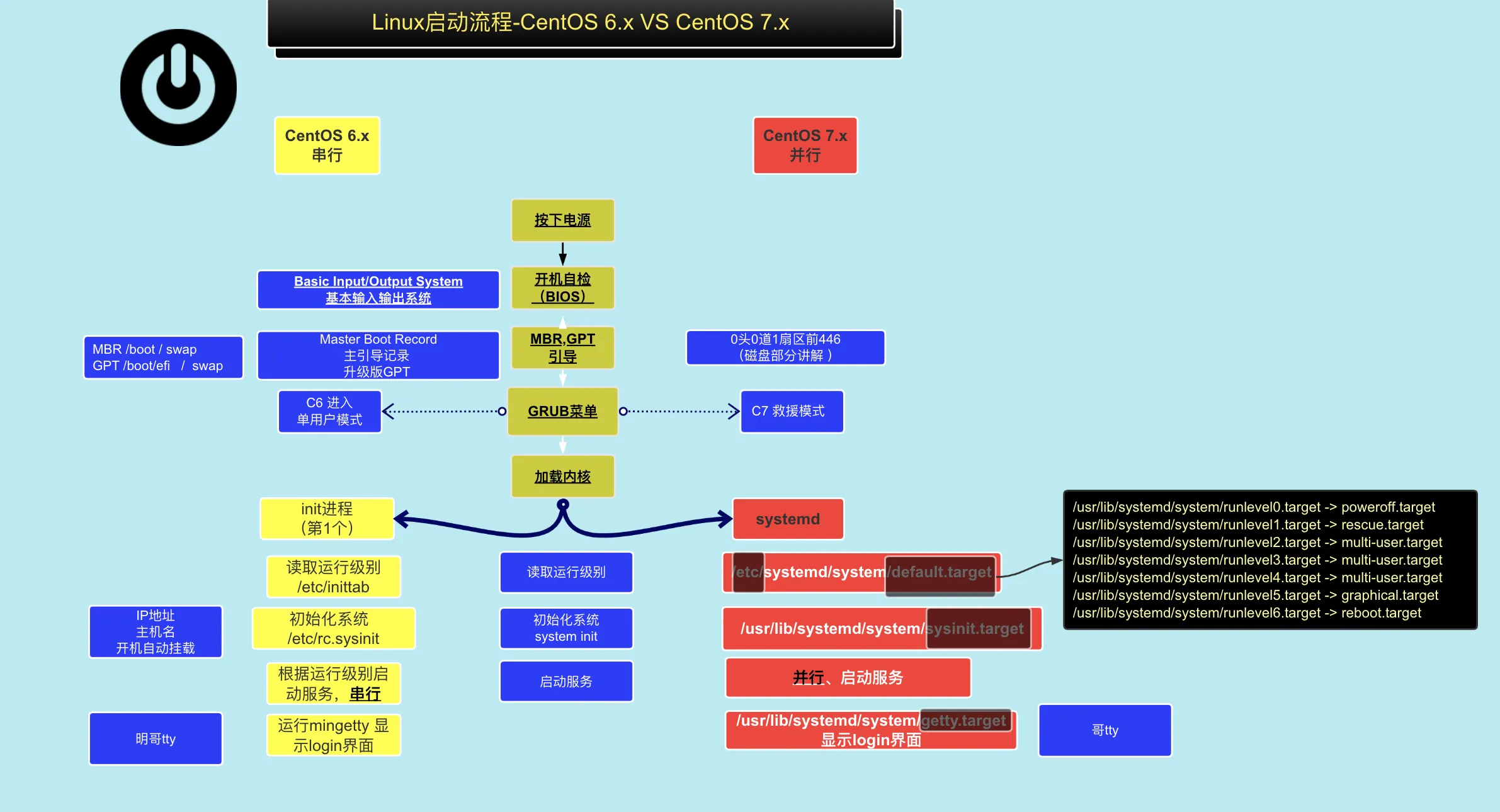
root密码忘记如何解决
首先应该避免这样的情况发生
- 多准备个备用用户,普通用户设置sudo权限
- 未来不仅仅只有密码认证,还有其他认证方式。
- 做好密码更新与统计工作。keepass保存密码。 excel表格。
其次,如果遇到了这个问题可以通过如下操作更改密码
- 重启Linux
- 进入grub菜单(先不要继续)选择第1个(目前使用中的Linux内核),按
e,编辑内核配置。
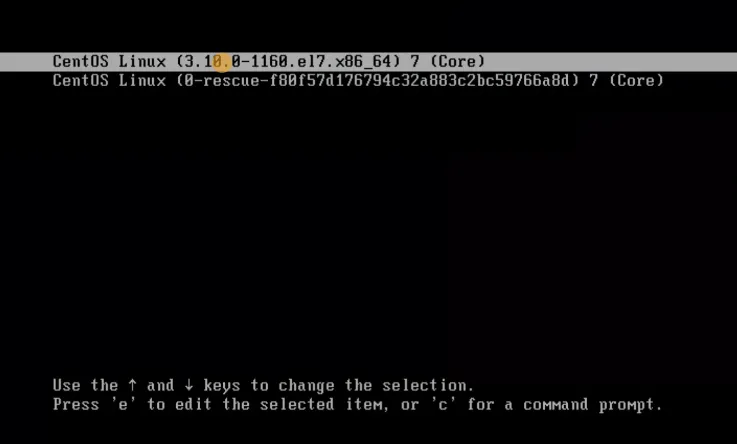 3. 找到Linux16的行,修改这一行的内容
3. 找到Linux16的行,修改这一行的内容 ro 改为 rw ,按 END 键到这一行的最后,输入 init=/bin/bash
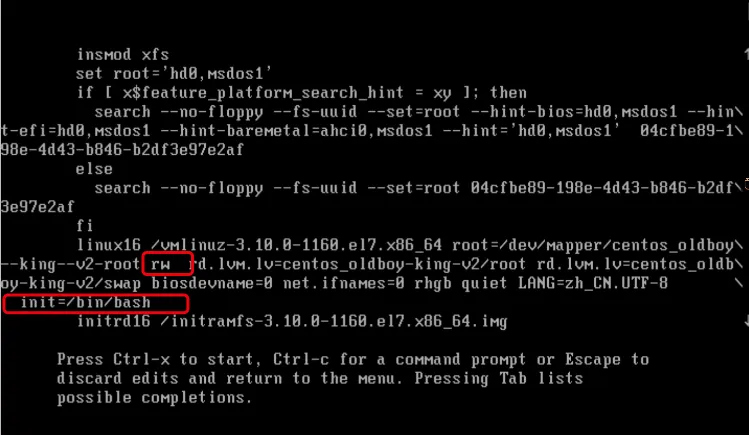 4. 修改完成,执行
4. 修改完成,执行ctrl+x启动系统,进入救援模式(此时无法远程连接)。
- 通过
vi/vim编辑/etc/passwd文件,去掉root的x标记(没有密码了),重启Linux.
 6. 本地登录Linux设置个密码即可。
6. 本地登录Linux设置个密码即可。
光盘的救援模式
- 检查光盘有没有塞到系统里
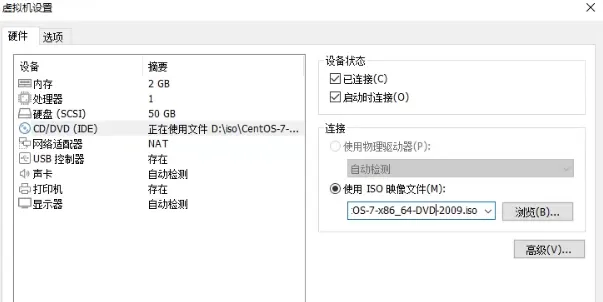
- 重启,让系统以光盘启动(U盘)
看到logo立即 按F12 或F10 (虚拟机是ESC)
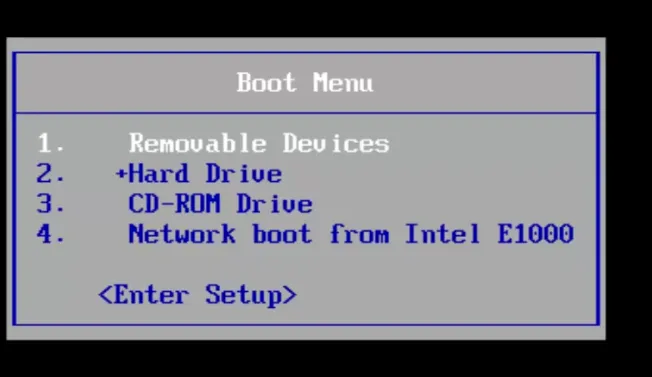
弹出启动菜单,选择光盘(第三个)
- 进入到系统安装页面,选择第3个“Troubleshooting”,回车进入
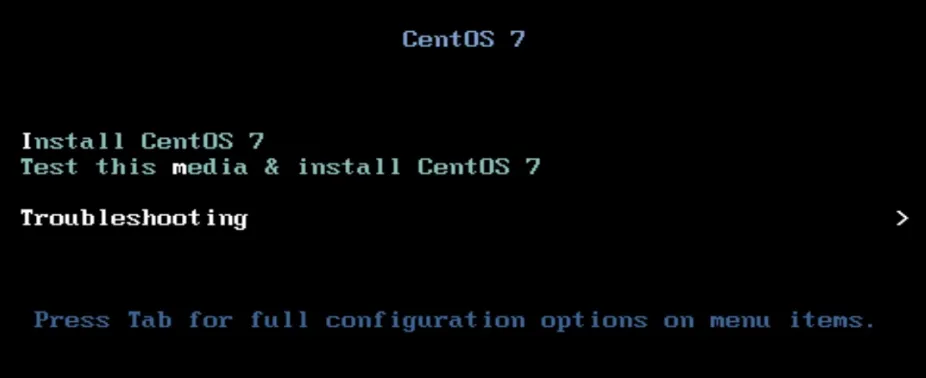
- 然后选择第2个"Rescue a CentOS system",进入光盘救援模式
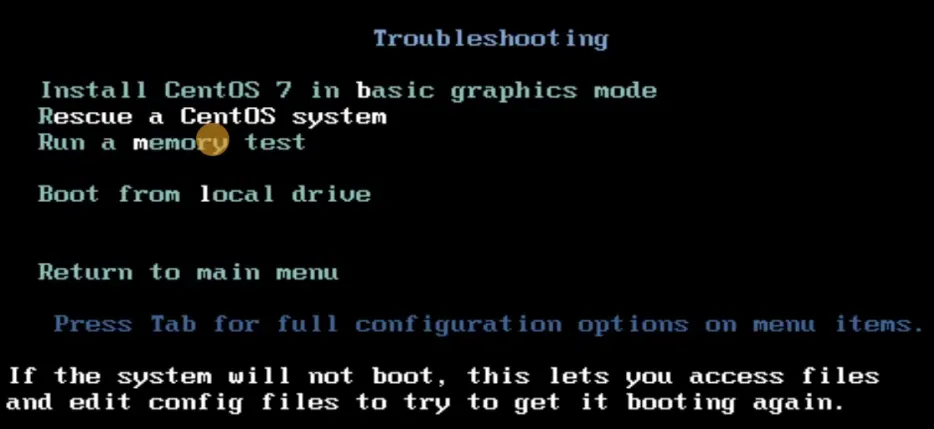
- 耐心等待后,出来多个选项:输入1选择第1个选项
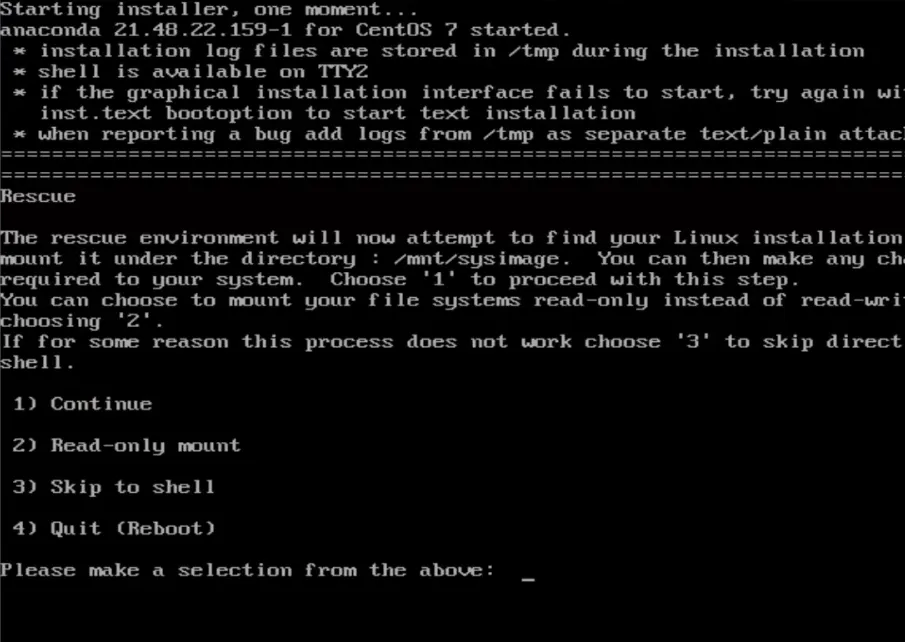
- 输入
chroot /mnt/sysimage切换回原来的根(现在的根是光盘)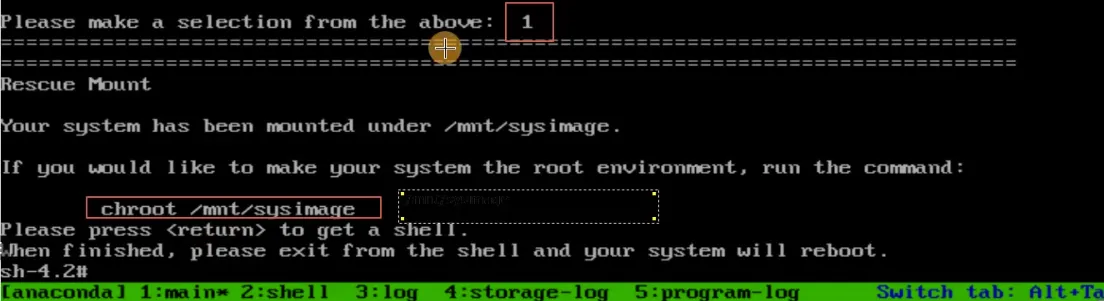
温馨提示:
/mnt/sysimage是你磁盘原有的根目录
查找/etc/passwd文件,/mnt/sysimage/etc/passwd.
可以使用chroot /mnt/sysimage/命令切换系统的根目录的位置,切换为/mnt/sysimage下
磁盘管理
磁盘是用来永久保存数据的,只有磁盘不坏,一般不会有问题。磁盘还有个名称就做硬盘
内存是用来临时存放数据的,断电后就会丢失
磁盘的分类
- 机械硬盘HHD 点击带动磁盘高速旋转,读取数据
- 家用机械硬盘速度可到达5400/min 7200/min
- 固态硬盘SSD 继承电路与芯片,存储芯片
磁盘的接口
不同类型的磁盘接口有不同的读写速度.
| 磁盘的接口 | 说明 | 优缺点 |
|---|---|---|
| SATA | 一般家用,一般用于机械硬盘,也有固态硬盘,容量大,价格较低 (水壶的壶嘴) | 接口统一 |
| SCSI | 企业用 | 性能好但接口不统一 |
| SAS | 企业用,一般用于机械硬盘,也有固态硬盘, SATA和SCSI的结合 | - |
| PCI-E | 企业级使用,固态硬盘用, 长条形 | 速度最快 |
| U.2 | 企业级固态硬盘使用。PCI-E类似 |

企业级环境磁盘选型
| 磁盘选型 | 建议 |
|---|---|
| 一般情况下,数据备份 | SATA硬盘,10k rpm 4tb,8tb存放备份 |
| 网站服务器使用 | SAS接口 15k rpm 300G 600G 900G |
| 高并发网站服务器 | 可以选择固态硬盘PCI-E,SAS,SATA |
此建议基于物理服务器,如果是公有云,一般不用考虑过多
rpm是 round per minute 每分钟多少转的意思.
机械硬盘 VS 固态硬盘
| - | 机械硬盘 | 固态硬盘 |
|---|---|---|
| 性价比 | 容量大、价格低 | 容量小价格贵 |
| 稳定 | 抗打击能力强 | 抗打击能力高 |
| 速度 | 读写速度稍慢io | 读写速度很快io |
| 数据安全 | 数据恢复易 | 数据恢复难 |
| 寿命 | 无限 | 1-2w次 |
磁盘的内部结构--略
RAID
什么是raid与常见raid级别?
- 在使用物理服务器的时候,多块硬盘,这些硬盘需要通过raid卡(设备),统一进行管理.
- 大部分需要做raid后才能安装系统,部署服务.
- raid 磁盘冗余阵列,管理磁盘方式.
根据用户所设置的Raid级别可以获取如下一个或多个特点
- 可以获取更高的容量.
- 可以获取更高的性能.
- 可以获取更高的冗余(安全).
注意: 上面3个特点会根据选用的raid方式(raid级别),所有区别,一般无法同时都满足以上3点
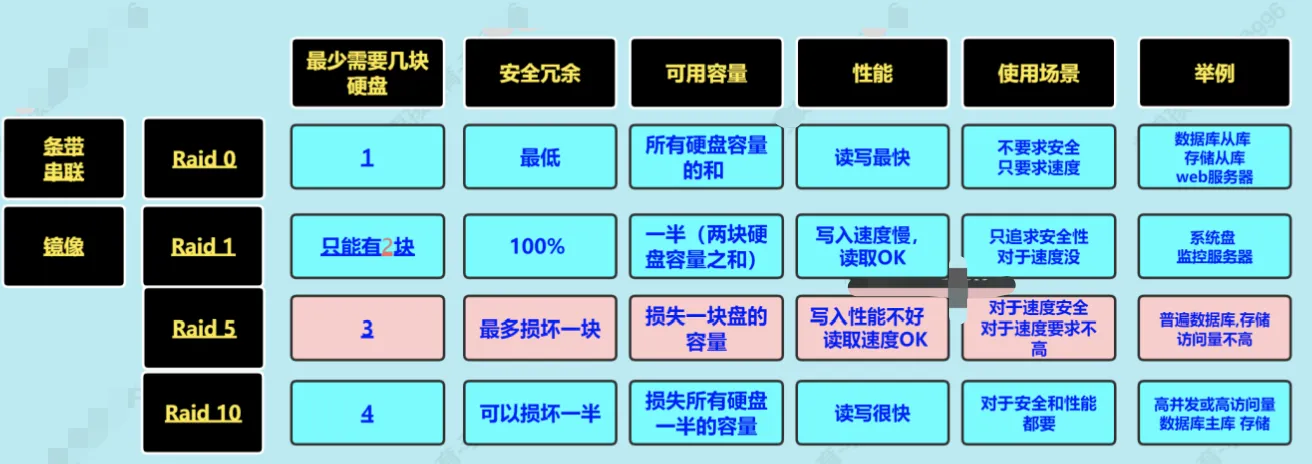
下面我来解释下为什么RAID管理多块磁盘无法同时获得上述三个优势(容量、性能、冗余)
- 当只有一块硬盘时,只能用
Raid 0,容量100%利用,读写也最快; 如果磁盘坏了,数据全没了(安全冗余0) Raid 1只能给两块硬盘做,可用容量是50%,写入速度慢,读取OK,没有安全冗余100%(一块都不能坏)。Raid 5至少3块硬盘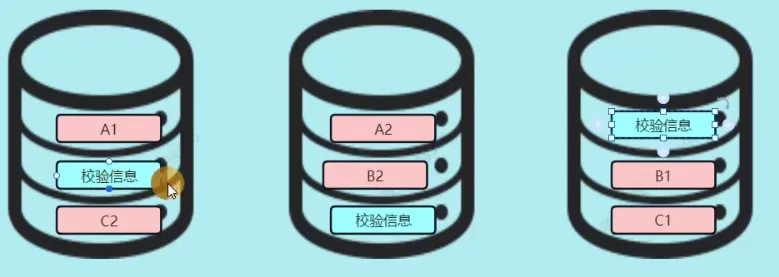
- 假设第一块磁盘坏了,数据A和C可以分别在磁盘2、磁盘3中恢复
- 可用容量N-1, 读写同
Raid 1安全冗余 1块硬盘
Raid 10的原理类似Raid 1和Raid 0的组合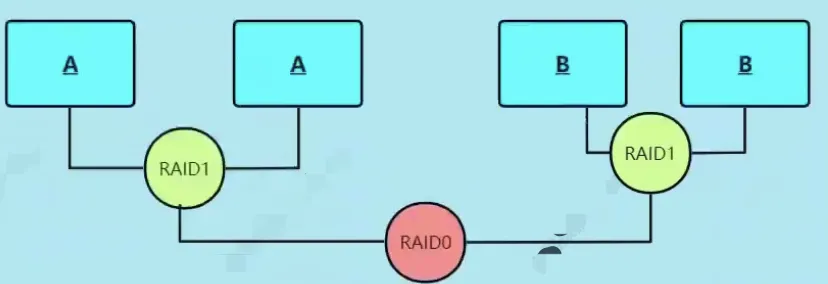
- 它综合
Raid 1和Raid 0的优势 读写速度快、冗余高,缺点是硬盘数要是2的倍数。
注意: Raid级别可以混合来,比如说你系统中有10块硬盘,每块硬盘一个T,可以给其中的两块硬盘做Raid 1用于装系统,剩余8块可以用Raid 0
物理服务器的分类了解
- 机架式服务器
- 塔式服务器
- 刀片式服务器
服务器高度 用U表示 1U=4.45cm
路数,表示服务器有即可CPU
新服务器到货后如何安装,可以参考这个视频
物理服务器又个重要的东西需要了解--远程控制卡
假如服务器宕机了,只要有网络就可以查看服务器状态,管理和控制服务器。 通过它可以远程开机、设置BIOS参数等
不同的服务器远程管理卡不同
- Dell iDrac
- ibm imm
- hp ilo
- 华为 iBMC
磁盘分区
磁盘分区概念: 主分区、扩展分区、逻辑分区、MBR\GPT
- 首先我们先来了解一个MBR概念, 每一块硬盘的开头都存放着一个磁盘引导程序。
- 它的位置在 磁盘分区表的 0磁头,0磁道,1扇区
- 一般不用太关注,在安装系统的时候自动安装了
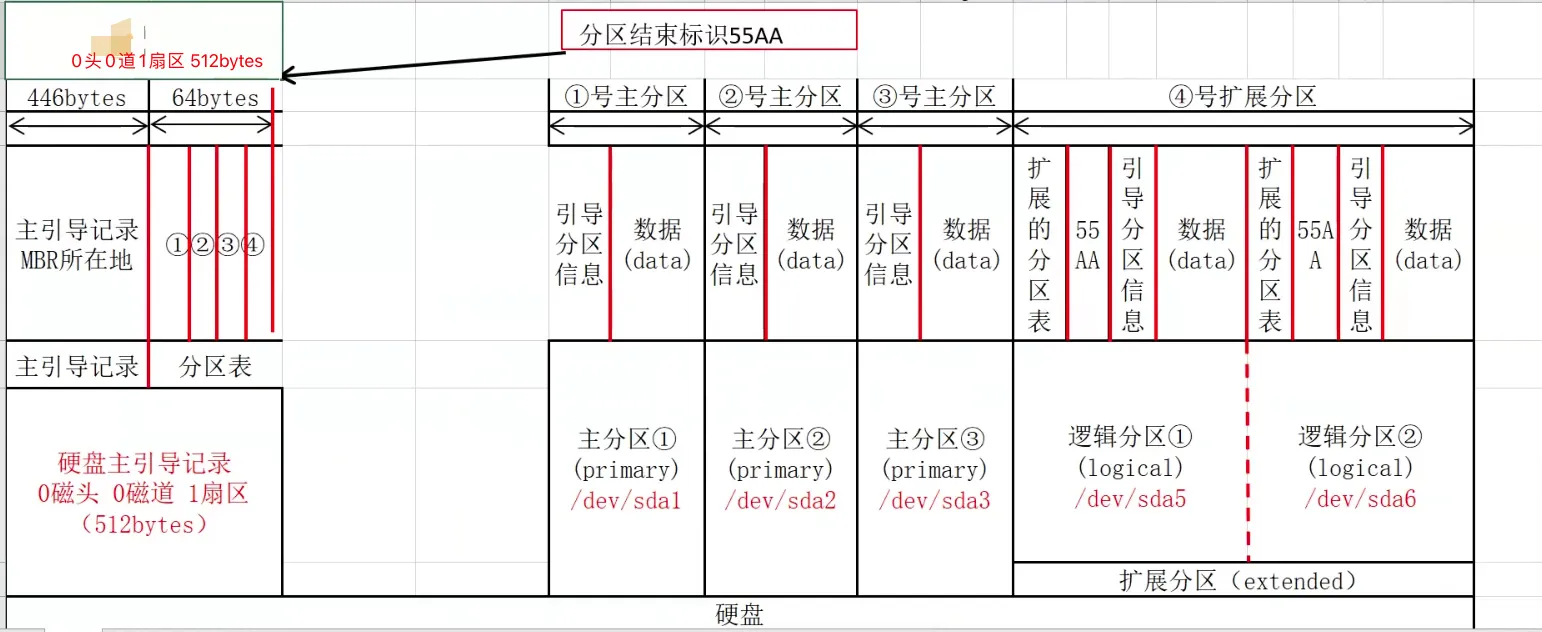
这512字节存放了
- 引导程序446字节(MBR)
- 磁盘分区表(64字节) 4个分区表
- 结束标识55AA
分区表64个字节,每个分区占用16字节,最多4个分区
- 这四个分区叫做主分区。
- 如果只划分1分区使用所有空间,将无法继续划分分区。
- 如果划分了4个分区,但是磁盘空间还有剩余,剩余空间将无法继续使用。
- 扩展分区是用于解决主分区数量只能有四个的问题
- 扩展分区无法直接使用,需要创建逻辑分区存放数据
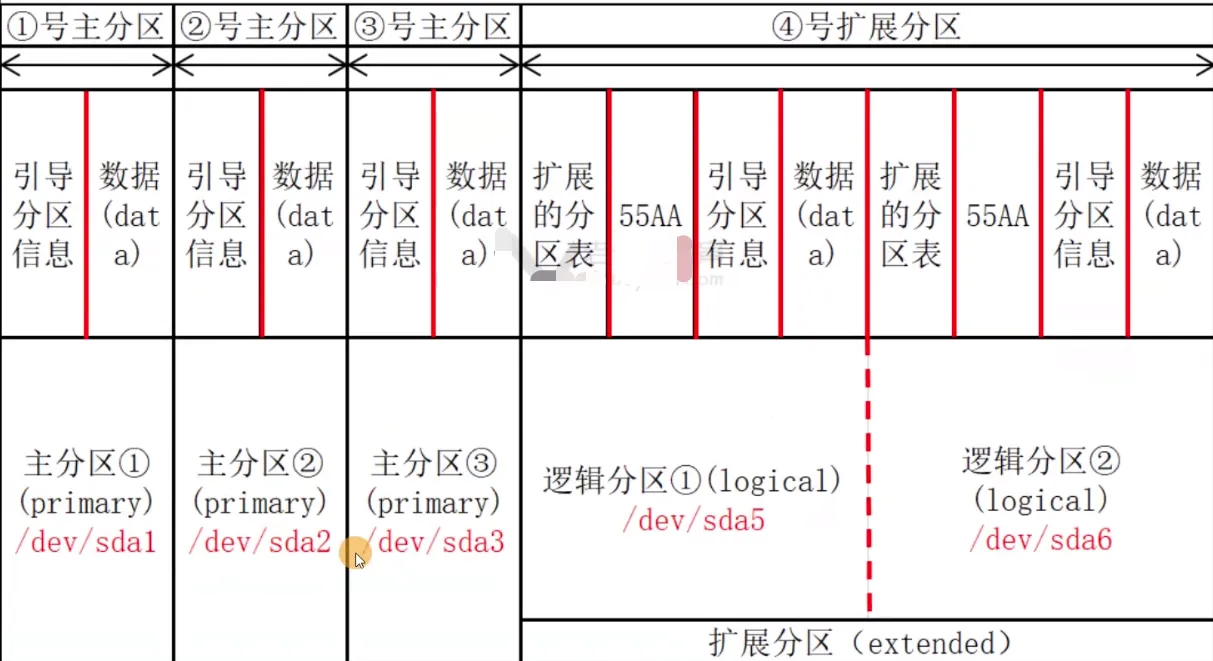
磁盘与分区命令
磁盘文件或分区文件放在/dev/下面
磁盘命令如下
- 磁盘接口
sas/sata/scsi接口的硬盘,硬盘名称以sd开头- 虚拟机(kvm)/ 公有云: 硬盘名称以
vd开头
- 第几块硬盘,通过字母表示(从字母a开头)
- 例:
/dev/sda
- 例:
- 第一块硬盘(SAS)接口
/dev/sda
分区命名
- 分区命名是根据分区类型进行命名的。
- 如果是主分区或者扩展分区则分区号从1-4范围。
- 如果是逻辑分区,逻辑分区的分区号从5开始。
示例:
- 第2块SATA硬盘的第1个主分区
/dev/sdb1 - 第3块SAS硬盘的第2个逻辑分区
/dev/sdc6 - 第5块公有云的云盘的第3个主分区
/dev/vde3
分区的流程是这样的,
- 如果拿到你拿到一块硬盘,如果是物理服务器你可能要做raid,
- 之后进行分区操作
- 接着创建文件系统(格式化)
- 最后挂载(通过命令或配置文件)
fdisk 是管理磁盘分区的命令
fdisk -l 查看系统磁盘及分区信息
示例: 创建20MB的分区
sh#1 操作硬盘
fdisk /dev/sdb
#2. 对硬盘分区进行增删改查
p print 输出磁盘分区信息
n new 创建分区
d delete 删除分区
w write 保存并退出
q quit 退出不保存
#3. 创建20MB分区
命令(输入 m 获取帮助):n #创建分区
Partition type: #提示选择 类型
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): 回车即可 #输入p或回车默认使用主分区
Using default response p
分区号 (1-4,默认 1):回车即可 #分区号回车使用默认的1号
起始 扇区 (2048-208895,默认为 2048):回车即可 #回车,使用默认的起点
将使用默认值 2048
Last 扇区, +扇区 or +size{K,M,G} (2048-208895,默认为 208895):+20M #+20M分区20MB
分区 1 已设置为 Linux 类型,大小设为 20 MiB
#4. 通过p查看
命令(输入 m 获取帮助):p
磁盘 /dev/sdb:1073 MB, 1073741824 字节,2097152 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x2af54b05
设备 Boot Start End Blocks Id System
/dev/sdb1 2048 43007 20480 83 Linux #这里有sdb1即可。
#5. 通过w保存退出
#6. 查看/dev/sdb*
提示
fdisk操作的时候,按删除键会出现无法删除现象,使用ctrl+u或ctrl+删除键 即可删除
格式化(创建文件系统)
- 创建 make 文件系统 filesystem,表示给磁盘分区进行格式化(初始化),给磁盘创建规则、一定量的inode、block
- mkfs(make filesystem) 创建文件系统(格式化)
通过mkfs可以对磁盘进行格式化,输入命令mkfs会有一些提示使用哪种文件系统进行格式化
 CentOS 的文件系统
CentOS 的文件系统
- xfs文件系统,CentOS 7默认的文件系统类型。
- ext4文件系统,用于CentOS 6.x 或公有云使用
mkfs.xfs /dev/sdb1 对sdb1磁盘分区进行格式化,格式化为xfs文件系统
mkfs.xfs 等价于 mkfd -t xfx
提示
不要对 sdba 进行格式化,等同于rf -rf /,这是很危险的
挂载
- Linux中的设备,需要通过挂载命令,给设备指定入口(已经存在的空目录),否则将无法使用.
- 通过mount命令指定设备入口(目录)
mount 设备 目录 - 入口: 挂载点,一般是个空目录就行.
/mnt是 linux临时挂载点.
sh# 给/dev/sdb1设置入口。入口/mnt/
mount /de/sdb1 /mnt/
# 查看有没有挂载成功
df -h | grep mnt
这个是临时挂载,重启Linux系统后挂载会失效
挂载光盘(只读)示例
mount /dev/cdrom /media/
卸载
unmount + 挂载点 表示卸载,示例 unmount /mnt
永久挂载
实现磁盘永久挂载的方案有两个
- 方案1: 把挂载命令
mount /dev/sdb1 /data/写入到etc/rc.local,注意最好写为绝对路径 - 方案2: 修改 开机自动挂载的配置
/etc/fstab,把mount命令改为配置文件格式即可
/etc/fstab每一列的含义
| 第1列 | 第2列 | 第3列 | 第4列 | 第5列 | 第6列 |
|---|---|---|---|---|---|
| 设备名字/dev/sdb1或UUID形式 | 挂载点 | 文件系统类型: xfs,ext4,swap | 挂载选项 一般是defaults | 是否备份 | 是否检查 |
| /dev/sdb1 或 UUID="xx-x..x" | /data/ | xfs | defaults | 0 | 0 |
注: 设备的UUID可以通过
blkid命令查询
mbr vs gpt
之前提到的Linux主分区+扩展分区最多有4个,这个是MBR限制的,另外还有一些限制
| 分区表 | 特点 | 对应目录 |
|---|---|---|
| mbr | 支持2tb以内的硬盘,大于2tb则只识别2tb. 区别主分区,扩展分区,逻辑分区 | fdisk/parted |
| gpt | 支持大容量硬盘,主分区无限使用(100多个) | gdisk/parted |
gpt可以理解为mbr的升级,支持更大容量硬盘,主分区数量不限制
sh# 创建gpt格式的分区大小10MB (/dev/sdc)
# 查看硬盘分区信息
parted /dev/sdb print
# 编辑/dev/sdc
parted /dev/sdc
# 创建分区表gpt格式
mktable gpt 或者mklabel gpt 一样 #注意mbr叫做msdos类型
# 创建分区10mb
mkpart primary 0 10
mkpart primary 10 20
# 删除分区
rm 1
# 退出编辑
q 或quit
注意
与fdisk创建或删除分区需要最后保存才生效,parted命令是立即生效,执行命令时要三思
创建swap
-
交换空间(Swap)是磁盘的一个分区
-
Linux物理内存满时,会把一些内存交换至Swap空间
-
Swap空间是初始化系统时配置的 (装系统时会提示 需不需要,需要多大)
-
window也有类似的功能叫做虚拟内存
-
相对于直接增加内存需要重启系统,增加Swap不需要重启系统。
案例: 服务器运行java程序,大量占用内存,以至于开始占用swap如何解决?
首先要保证网站正常,增加swap空间,其次联合开发一起排查
增加1g的swap.
- 创建指定大小的文件1g的文件.
- 把文件转换为swap.
- 激活这个swap,把它加入到linux中.
- 记得配置永久挂载.
具体操作过程
sh# 1.创建指定大小的文件1g的文件.
dd if=/dev/zero of=/tmp/1g bs=1M count=1000
# if === input file 数据从哪里来,输入文件,一般使用/dev/zero,不断输出空字符.
# of === ouput file 创建的文件,存放数据,输出文件
# bs === block size 每次读取多少,一般1MB大小.
# count === 读取次数
# 2.把文件转换为swap(格式化).
mkswap /tmp/1g
-----------------------
root@myServer ~]# file /tmp/1g
/tmp/1g: data # 刚刚创建的文件data普通数据文件
[root@myServer ~]# mkswap /tmp/1g
正在设置交换空间版本 1,大小 = 1023996 KiB
无标签,UUID=0c072a5f-5ec2-4590-acd3-cae1e1926029
[root@myServer ~]# file /tmp/1g #成为了swap 文件
/tmp/1g: Linux/i386 swap file (new style), version 1 (4K pages), size 255999 pages, no label,
UUID=0c072a5f-5ec2-4590-acd3-cae1e1926029
--------------------------
# 3. 激活这个swap,把它加入到linux中.
[root@myServer ~]# free -h
total used free shared buff/cache available
Mem: 1.9G 201M 596M 9.6M 1.2G 1.6G
Swap: 2.0G 0B 2.0G
chmod 600 /tmp/1g
swapon /tmp/1g
free -h
total used free shared buff/cache available
Mem: 1.9G 202M 595M 9.6M 1.2G 1.6G
Swap: 3.0G 0B 3.0G
# 4.记得配置永久挂载.
# 方法01 : swapon /tmp/1g写入到rc.local
# 方法02: 写入/etc/fstab
# /tmp/1g swap swap defaults 0 0
企业分区方案
公有云一般不用考虑,物理服务器和虚拟云(私有云)需要根据具体情况设置
/,/boot/,swap分区大小。
如果服务器存放的数据不重要
/boot/引导分区 引导系统启动与存放引导文件,存放系统内核镜像. 推荐1G即可swap根据实际内存配置,大于8G,swap配置8G即可. 低于实际内存低于8G, 1.5倍或2倍 ,最大8G- 补充:公有云可以不配置, 如果是java建议配置一 些.
/根分区 所有剩余空间给根.
如果服务器存放重要的数据.
/boot/引导分区 引导系统启动与存放引导文件,存放系统内核镜像. 推荐1G即可swap根据实际内存配置,大于8G,swap配置8G即可. 低于实际内存低于8G, 1.5倍或2倍 ,最大8G./根分区 给40G-200G,主要安装一些软件.重要数据单独存放/data/剩余所有空间
如果不知道是否重要,可以不创建/data/即 剩余空间先不划分 未来谁使用谁划分
创建分区的好处
如果系统突然挂了,可以通过重装系统手动配置分区,系统安装完成重新挂载分区,数据就恢复了
raid+lvm 给磁盘扩容略
案例-磁盘空间不足
一般要对磁盘空间进行监控,如果超过60%就要告警了,达到70~80%就要处理了,如果磁盘空间100%就没救了。
一个文件由inode和block两部分组成,通常磁盘空间不足是有block空间不足引起的。
- 错误提示:
no space left on device - 现象:
df -h某个磁盘分区使用率达到100%,如何排查,如何处理? - 模拟: 创建1个大文件(小伙伴完成)
dd if=/dev/zero of=/var/log/nginx.log bs=1M count=2000du -sh /*查看/下面所有目录大小
排查过程
sh# 1. df -h 查看哪里空间不足,哪个分区
# 2. du -sh详细查看目录所占空间
du -sh /* 排查占用空间大的目录
du -sh /var/*
du -sh /var/log/*
# 3. 最终通过du -sh 排查到具体的大文件或大的目录
# 4. 找出后确认是否可以删除
解决:通过du -sh排查到具体的大文件或目录,找出后确认是否可以删除
温馨提示: /sys/ /proc/ 等目录是虚拟目录,不要在里面创建文件,/dev/是设备目录,也不要在里面创建.
案例-磁盘空间不足-inode
inode存放文件属性信息,block存放文件内容.inode在磁盘格式化后,数量是固定的- 工作中可能出现大量小文件,导致占用
inode速度快于block,inode不足了,也会导致磁盘空间不足
- 现象: 操作的时候,提示
no space left on device,df -h查看发现磁盘空间没有满,问什么原因导致的? - 原因: 磁盘空间不足,不是block导致的,还有一种情况是inode数量不足
- 排查:
- df -h查看磁盘空间没有满,df -i查看inode使用情况.
- 找出这个分区中,大目录(目录本身大小大于1MB,du -sh目录所占空间)就行.
- 找出有大量小文件的目录
- 解决: 确认是否可以删除或处理
模拟: 需要见一个空间小的分区,这样inode空间小,方便模拟
sh# 创建指定大小文件(用于成为磁盘分区)
dd if=/dev/zero of=/tmp/1g-new bs=1M count=1000
# 磁盘格式化
mkfs.xfs /tmp/1g-new
# 创建挂载点
mkdir -p /aa/inode-error/
# 进行挂载
mount /tmp/1g-new /aa/inode-error/
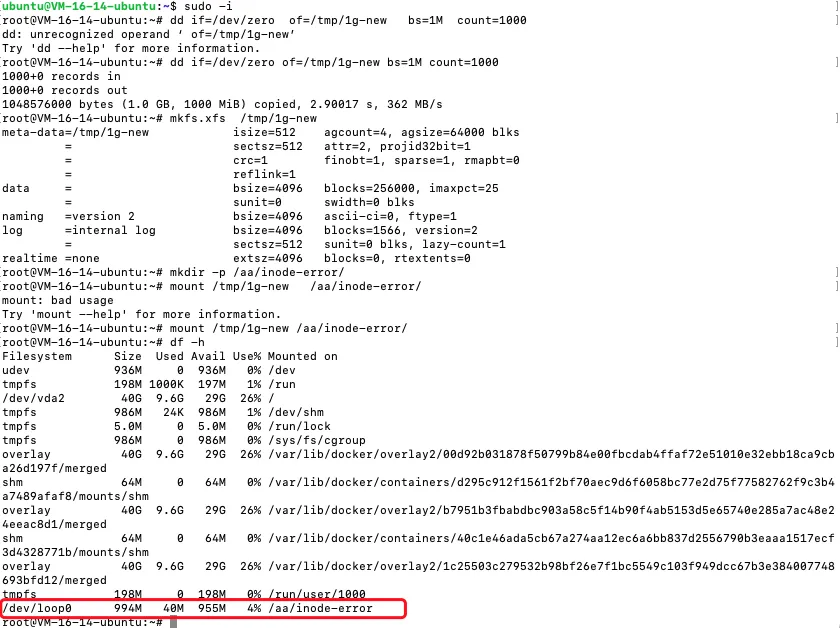
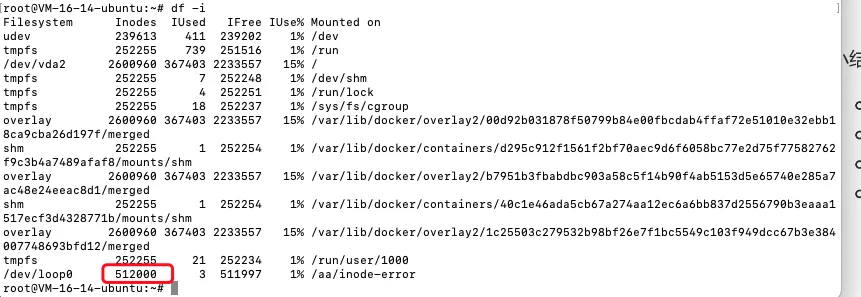
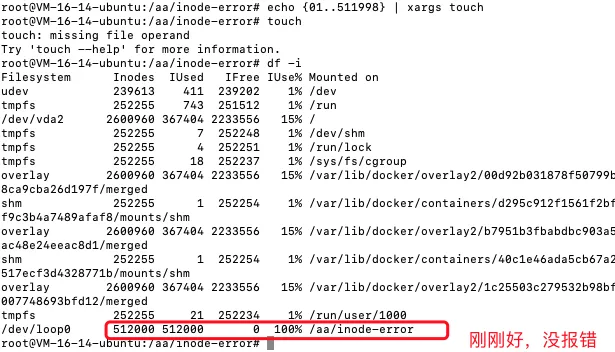
再次创建文件 就报错了
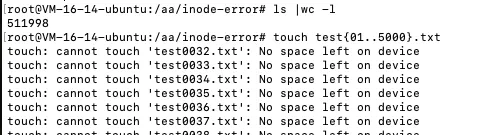
由于磁盘会预留一些inode, 所以>512000

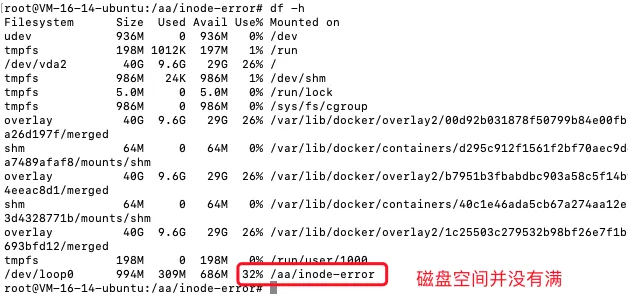

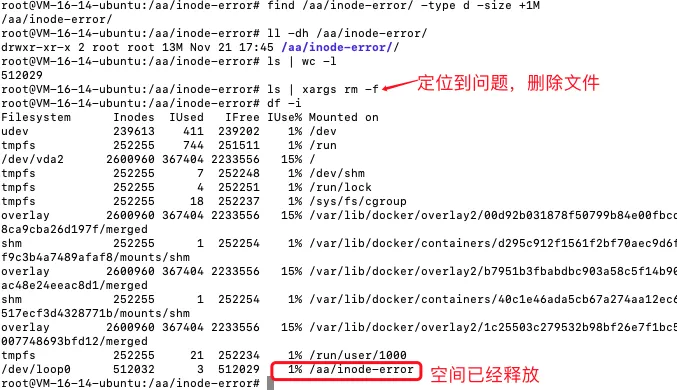

查找有大量小文件目录的技巧
find /aa/ -type d -size +1M#只有一个空白文件目录的占4k,先假定小文件目录大于1Mfind /aa/inode-error -type f | xargs dirname |sort | unique -c
磁盘空间不足-未彻底删除导致故障
linux一个文件被彻底删除的条件
- 删除文件,硬连接数为0,文件相当于被删除了。
- 文件调用次数为0,需要检查文件是否被使用中(命令、服务)
如何知道硬链接数是否为0 ?
一般rm后,通过ls、find查看,没有则为0
如何知道进程调用数是否为0?
lsof(list open files)命令显示打开的文件 lsof |grep 文件名
shtail -f /etc/passwd # 在第一个窗口执行这个命令
# 新开一个窗口执行
root@VM-16-14-ubuntu:/etc# lsof |grep passwd
tail 2592906 ubuntu 3r REG 252,2 2246 269589 /etc/passwd
root@VM-16-14-ubuntu:/etc#
| lsof每一列 | 说明 |
|---|---|
| 第1列 | 命令或服务名字 |
| 第2列 | pid |
| 第3列 | 用户 |
| 第7列 | 文件大小(字节) |
| 第8列 | 文件inode号码 |
| 最后1列 | 文件名 |
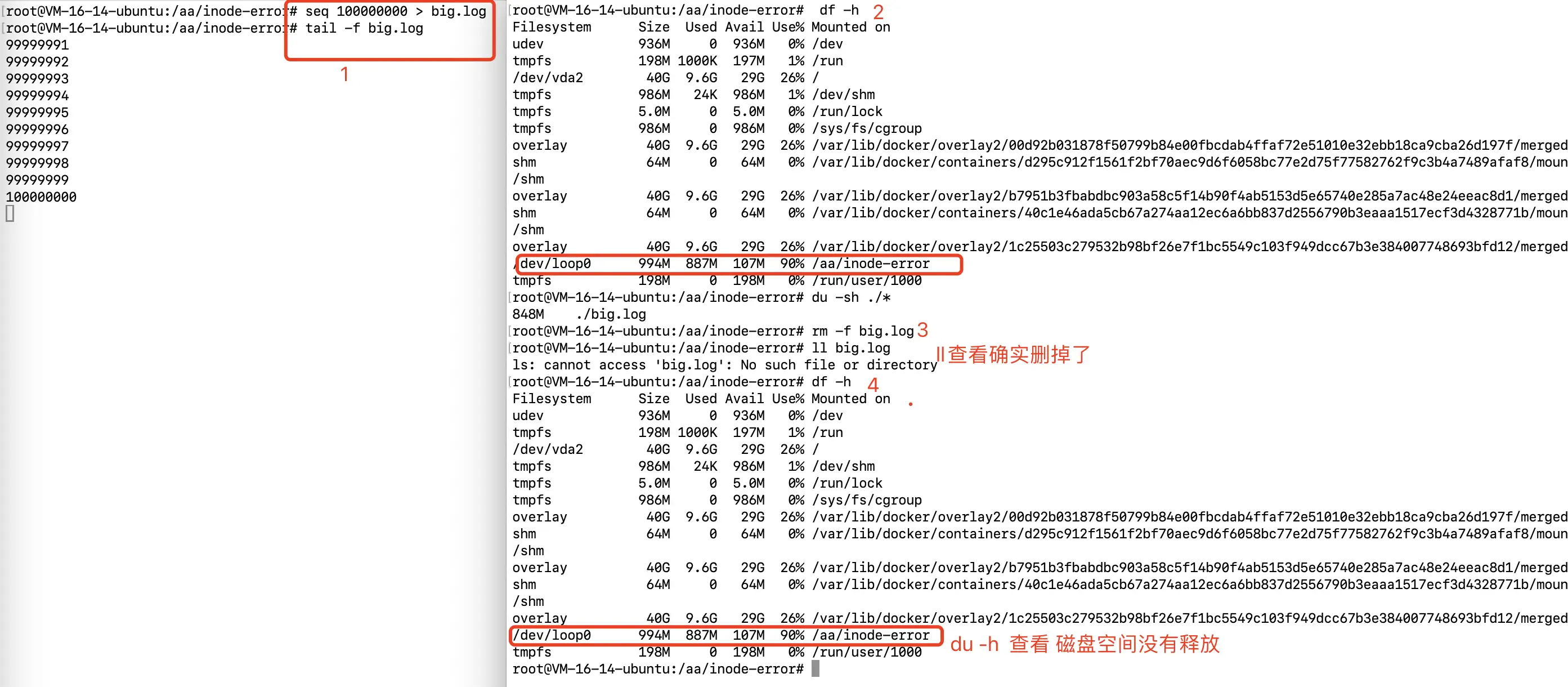
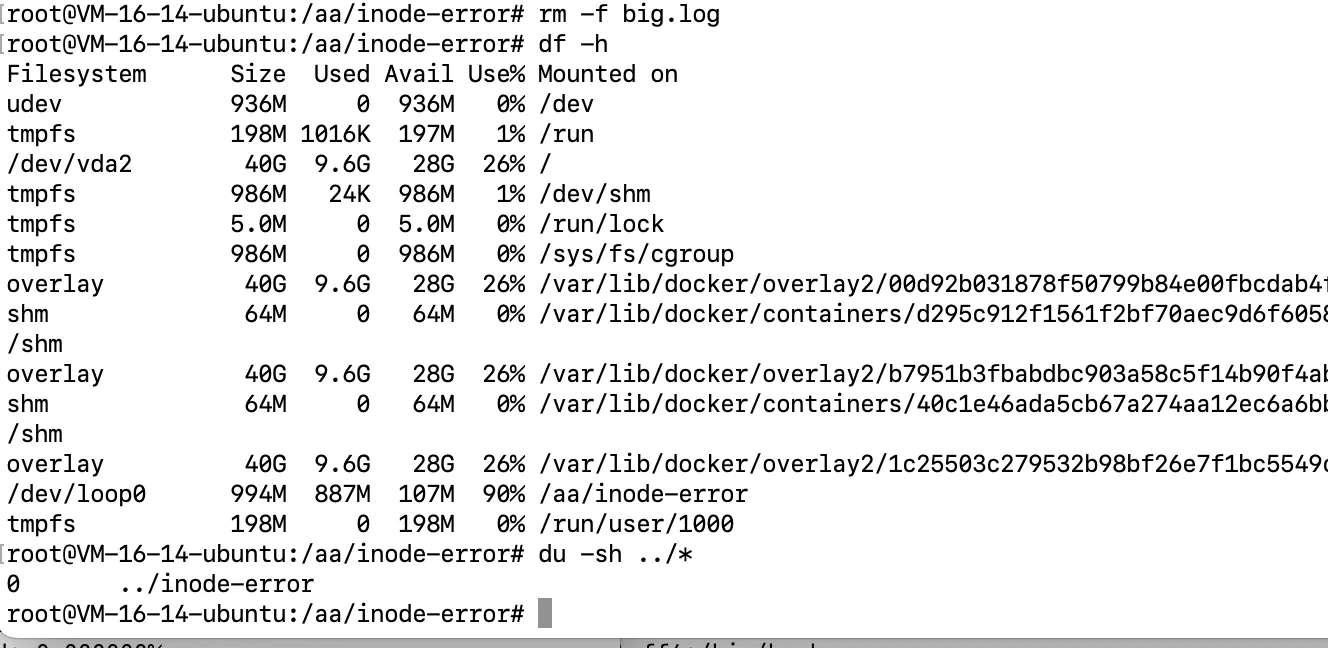
sh#1. 模拟故障(文件被调用中,但是没有入口)
seq 100000000 >big.log
通过tail -f 调用
rm -f big.log
# 2. 另一个窗口排查
# 使用`df -h`和`du -sh`排查
# 3. 发现问题
# 4. 继续排查
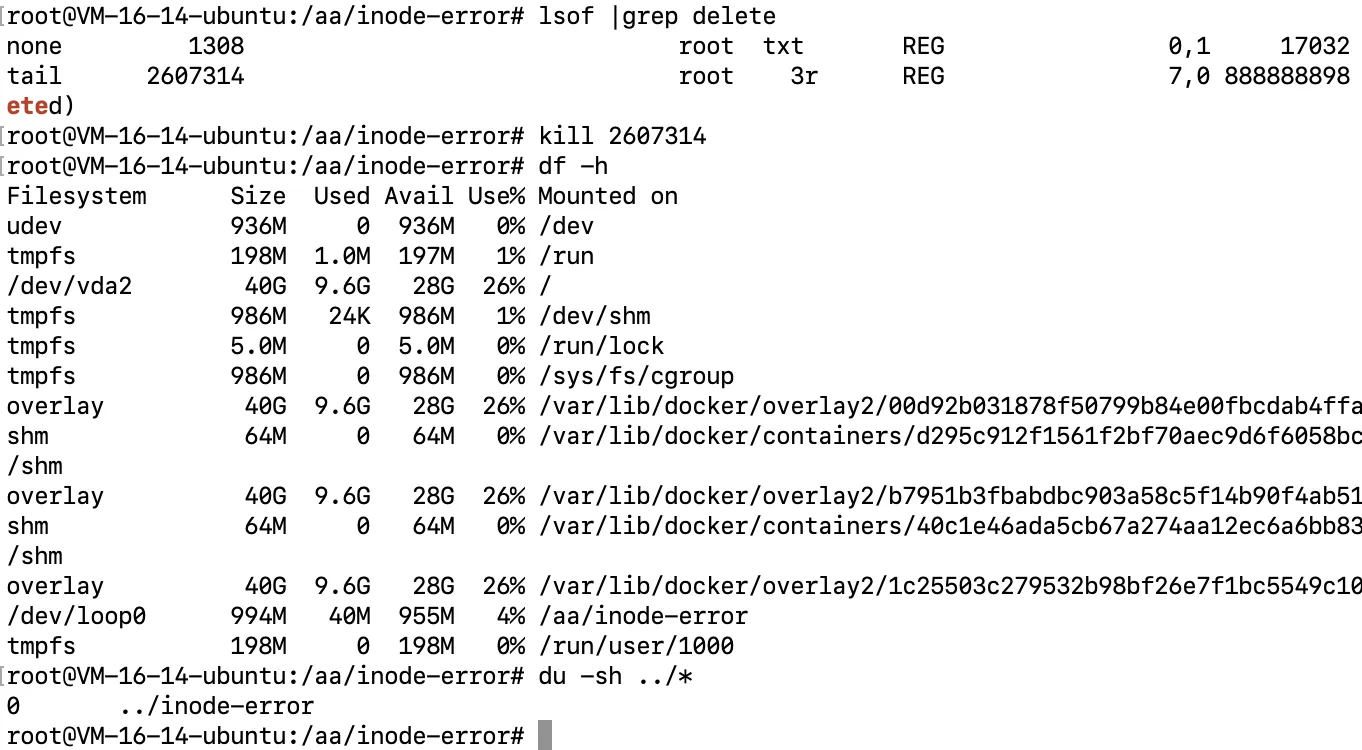
lsof |grep delete # 处理此类问题的固定命令
# 5. 解决问题
结束这个进程(服务),重启服务.
总结
- 文件硬链接数为0了,但是进程调用数不为0导致的问题
- 现象:
df -h查看磁盘满了,实际使用du -sh查看发现没有满 losf |grep delete,找出对应的服务或命令- 重启服务或结束命令,重启后被占用的空间会被释放
文件系统
window的文件系统
- 最初是 FAT32 , 缺点是文件最大为4G,优点是linux支持
- 后来升级到NFTS 更安全一些
- exFAT U盘式用这个
linux的文件系统
- xfs
CentOS 7默认的文件系统 - ext4
CentOS 6.x和ubuntu默认的文件系统 - ext3
CentOS 5.x默认的文件系统
swap 交换分区,也算是个文件系统
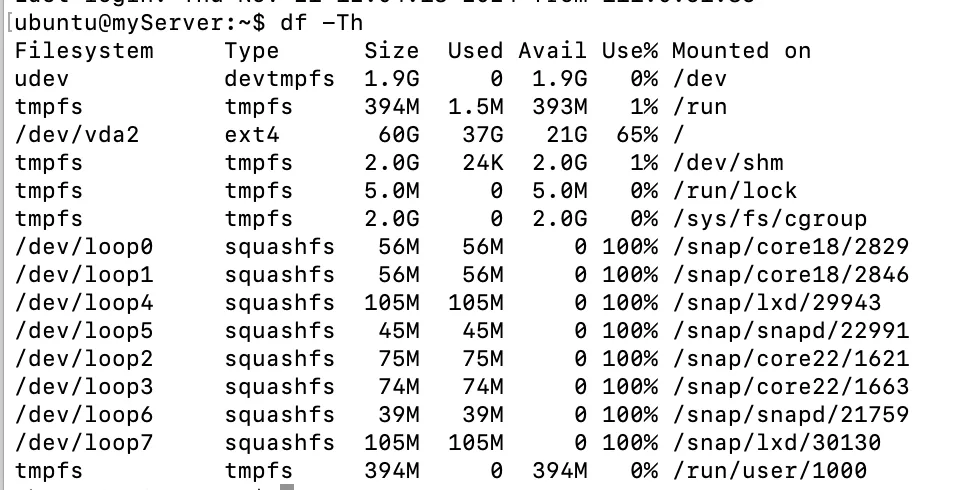
文件系统类型可以通过df -Th查看
参考资料 《大话存储》
查看系统信息cat /etc/os-release
磁盘的性能指标
- 吞吐量(读写速度) 顺序读取(最高) 顺序写入(最高)
iopsio per second每秒可以进行读写次数- 延迟 进行读写的时候操作延迟
- MTBF 平均能够运行多长时间会出故障(固态硬盘都是百万小时)
- 连续读写 : 通过dd命令测试
- 随机读写: fio测试
- fio可以测试这些指标
定时任务
定时任务: 用于执行在Linux中的重复性工作.eg:命令(同步系统时间),脚本(备份,系统巡检)。可类比为生活中的闹钟。
- 定时任务软件包名字:
cronie- 查看软件信息
rpm -qa cronieorrpm -ql cronie - Ubuntu系统
dpkg -l | grep cron
- 查看软件信息
- 服务名字(进程)
crond/var/spool/cron/
| 目录结构 | 说明 |
|---|---|
/var/spool/cron/ | 用户的定时任务的配置文件的目录 |
crontab | 定时任务管理的命令 |
/var/log/cronUbuntu 20.04 及以后: 查看 syslog 日志文件 | 定时任务日志 |
/etc下面有一些定时任务的配置文件

但是工作中一般不用这个配置文件,因为我们的需求可能是每两天执行,每4小时执行,这几个配置文件就不满足,这里通常是放系统的定时任务。
检查定时任务是否运行
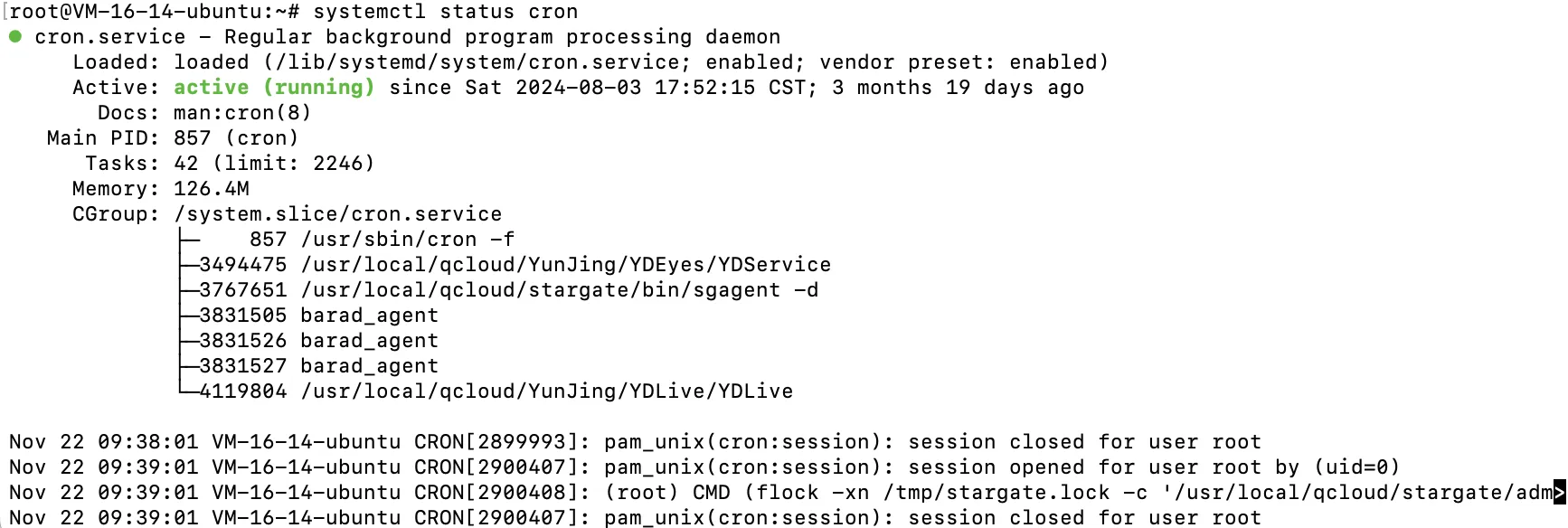
- Centos
System status crond - Ubuntu
System status cron
cron使用指南
- 配置的命令
crontab 用于对定时任务的规则进行增删改查
| crontab选项 | 说明 | |
|---|---|---|
crontab -e | edit编辑当前用户的定时任务 | vi /var/spool/cron/root #root当前用户的名字 |
crontab -l | list查看当前用户的定时任务 | cat /var/spool/cron/root #root当前用户的名字 |
注意,配置定时任务一般是root用户,普通用户没那么多权限
大部分软件修改后需要重启服务,定时任务修改后不需要
crontab -e 如果没有创建过定时任务 会新建一个空的定时任务文件
- 定时任务书写格式

五个星号的含义
- 第1个 分钟 0-59
- 第2个 小时 0-23
- 第3个 日期 1-31
- 第4个 月份 1-12
- 第5个 周几 0-6 0或7表示周日
写一些案例理解下定时任务的配置
| 需求 | 定时任务配置 |
|---|---|
| 每天早上8:30分 go to school | 30 08 * * * go to school |
| 晚上12点 go to bed | 00 00 * * * go to bed #每天运行 * 00 * * * go to bed #每天的半夜12点00-59 每分钟运行 |
- 定时任务配置中的特殊符号
| 符号 | 说明 | 案例 |
|---|---|---|
/ | 每隔XXX时间 | */2 * * * *每隔2分钟00 2 * * * 每隔2个小时 |
- | 表示范围 | 00 08-22 * * * 08-22点的每个小时运行 00 08-22/3 * * * 08-22点的每3小时运行 |
, | 表示独立时间(没规律) | 00 08,11,14,17,20 * * * |
* | 每,全部/所有(没说具体时间) | *在分钟的位置上表示00-59,每分钟的意思 *在小时位置上表00-23,每小时的意思. |
sh# 每天的上午7点到晚上11点 每二个小时运行CMD命令
00 07-23/2 * * * CMD
#定时任务每天23点到第2天的7点运行.
00 23,00-07 * * *
定时任务案例
定时任务的作用
- 同步时间
- 进行备份
- 日常循环操作
- 巡检+发送邮件
来看几个案例
- 同步系统时间
先通过date -s 20240101修改系统时间,date测试
接着ntpdate ntp1.aliyun.com 恢复系统时间,date测试
crontab -e
sh#1. 同步时间 by guoguo at 20241122
1 * * * * /sbin/ntpdate ntp1.aliyun.com
>/dev/null 2>&1
通过tail -f /var/log/cron查看定时任务执行日志
但是/var/log/cron 这个文件只是记录定时任务的执行,不包含调用结果是否成功
关于定时任务的运行结果,可以安装postfix,配置邮件,执行结果会记录在/var/spool/mail/root目录下
- 定时备份
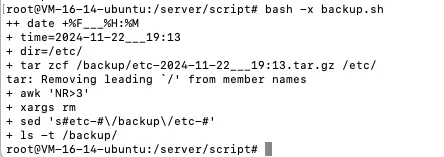
脚本文件 /server/script/backup.sh
sh#!/bin/bash
# auther guoguo
# time xxx
# desc 备份etc
## 定义变量
time=`date +%F___%H:%M`
dir='/etc/'
tar zcf /backup/etc-${time}.tar.gz ${dir} # 备份
ls -t /backup/ |awk "NR>3"| sed 's#etc-#\/backup\/etc-#' | xargs rm # 只保留前三条
配置定时任务 crontab -e增加内容
sh*/1 * * * * bash /server/script/backup.sh
这里补充个知识点,linux脚本变量
sh# 赋值 修改变量内容(创建)
text="xxx"
#取值
echo $text
echo ${text}
# 变量可以嵌套组合
text1='xxx'
text2='YYY'
text3=${text1}${text2}
echo "${text3}"
变量命名规则:
- 不能以数字开头
- 如果要用特殊符号,最好使用_
- 变量名字能够体现出变量作用.
补充:生产中可能有多台机器,备份时文件名要加上ip,这里补充了取IP的命令hostname -I | awk '{print $1}'
定时任务书写和注意事项
使用定时任务的注意事项
- 尽量使用脚本,定时任务中执行脚本
- 尽量增加注释,说明这条定时任务的作用
- 定时任务中的文件及命令尽量使用绝对路径
- 书写的命令或脚本定向到空或追加到文件
- 示例
* * * * * bash /server/scripts/backup.sh &>> /tmp/backup.log - 或者丢弃掉
&>> /dev/null - 如果邮件服务开启,执行命令的时候会时不时有提示,你有一个新邮件
- 如果邮件服务为开启,执行命令的时候不会有提示,保存临时目录中,存放大量小文件,占用
inode空间
- 示例
- 在定时任务中
%表示回车, 解决方案\%
shell脚本调试
sh -x 或 bash -x,显示脚本执行过程
- 不带 + 表示执行结果
- 带+ 表示执行过程
- +数量表示调用的优先级
为什么定时任务中的命令要使用绝对路径?
假如定时任务要执行test-info.sh这个脚本
sh#!bin/bash
hostname
ip a s ech0
会发现错误 Command 'aaa' not found
这是因为在定时任务运行命令的时候只能识别/bin或/usr/bin目录下面的命令。
我们正常运行脚本命令会在
 这些目录下寻找。
这些目录下寻找。
那么,只要不在/bin或/usr/bin这两个命令下的命令就不能运行.
解决方案
- 使用命令的绝对路径
- 在脚本的开头重新定义下PATH环境变量
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/snap/bin: No such file or directory
- 在脚本的开头重新加载在PATH环境变量
source /etc/profile
在终端连接ssh后会发现 一个奇怪的问题,
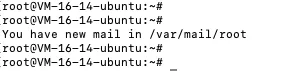
这个是定时任务配置引起的, 配置下定时任务丢弃输出结果即可 &>>/dev/null
定时系统巡检
定时系统巡检(定时输出系统基本信息)写入到/tmp/sys.log中,/tmp/sys.log文件的格式如下
sh#################################
主机名: myServer ip地址: 10.0.0.200
#################################
负载信息
最近1分钟: 0
最近5分钟: 0
最近15分钟: 0
#################################
内存信息(单位kb)
总计内存: 2000000
内存使用了多少: 200000
内存使用率: 10%
#################################
swap信息
swap总大小: 200000
swap使用大小: 0
swap使用率: 0
#################################
磁盘信息
几块硬盘: 1
根分区大小: 20G
根分区使用率: 10%
################################
进程信息
进程总数: 100
运行中进程: 2
挂起进程数量: 0
僵尸进程数量: 0
################################
答案如下
sh#!/bin/bash
#auther: guoguo
#desc: 系统巡检基本脚本
#version: v1
#1. 基础信息
hostname=`hostname`
ip=`hostname -I`
echo "################################"
echo "#############基本信息###########"
echo "主机名: $hostname"
echo "ip地址: $ip"
echo "################################"
#2. 负载
load1=`uptime |awk -F'[ ,]+' '{print $(NF-2)}'`
load5=`uptime |awk -F'[ ,]+' '{print $(NF-1)}'`
load15=`uptime |awk -F'[ ,]+' '{print $(NF)}'`
echo "#############负载信息###########"
echo "最近1分钟负载: $load1"
echo "最近5分钟负载: $load5"
echo "最近15分钟负载: $load15"
#3. 内存
mem_total=`free |awk 'NR==2{print $2}'`
mem_used=`free |awk 'NR==2{print $3+$6}'`
mem_used_percent=`free |awk 'NR==2{print ($3+$6)/$2*100"%"}'`
echo "#############内存信息###########"
echo "总计内存:$men_total"
echo "已用内存:$mem_used"
echo "内存使用率:$mem_used_percent"
echo "################################"
#4. swap
swap_total=`free | awk 'NR==3{print $2}'`
swap_used=`free | awk 'NR==3{print $3}'`
swap_used_precent=`free | awk 'NR==3 && $2 != 0 {print $3/$2*100"%"} NR==3 && $2 == 0{print "无swap"} '`
echo "#############swap信息###########"
echo "总计swap:$swap_total"
echo "已用swap:$swap_used"
echo "swap使用率:$swap_used_percent"
echo "################################"
#5. 磁盘
disk_total=`fdisk -l | grep '/dev/[sv]d[a-z][::]' | wc -l`
root_size=`df -h |awk '$NF=="/"{print $2}'`
root_used_percent=`df -h|awk '$NF=="/"{print $5}'`
echo "#############磁盘信息###########"
echo "几块硬盘:$disk_total"
echo "根分区大小:$root_size"
echo "根使用率: $root_used_percent"
echo "################################"
#6. 进程
proc_total=`top -bn1 | awk 'NR==2{print $2}'`
proc_running=`top -bn1| awk 'NR==2{print $4}'`
proc_stopped=`top -bn1| awk 'NR==2{print $8}'`
proc_zombie=`top -bn1| awk 'NR==2{print $10}'`
echo "#############进程信息###########"
echo "进程总数:$proc_total"
echo "运行的进程:$proc_running"
echo "挂起进程: $proc_stopped"
echo "僵尸进程: $proc_zombie"
echo "################################"
发送邮件
echo 'hello guoguo' | mail -s '你网站又挂了' 2315162186@qq.com
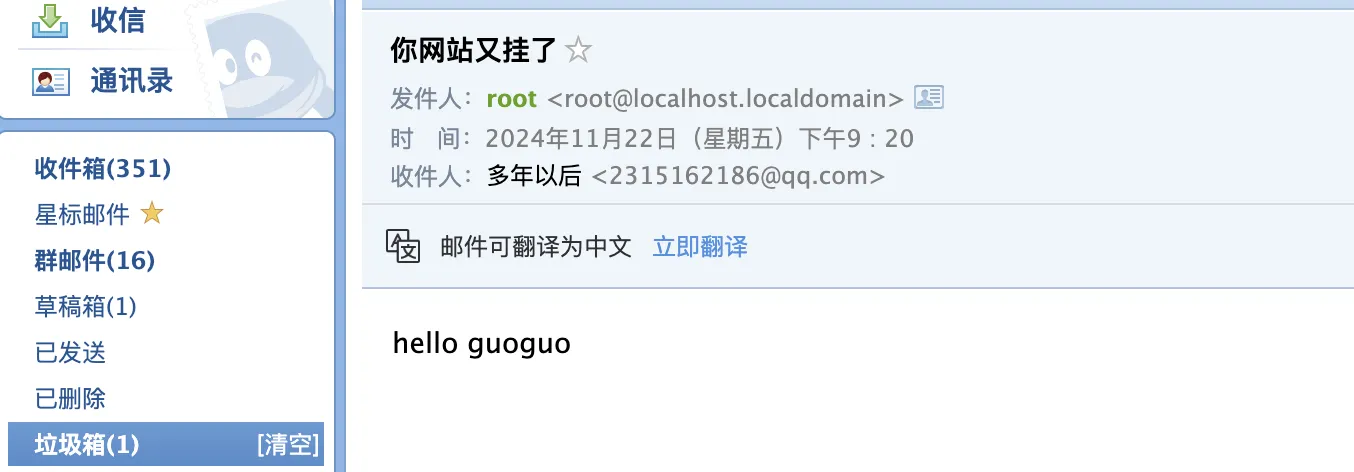
如果不想进入垃圾邮件,就需要配置一下收件人。
linux服务器发送邮件以163邮箱为例
- 登录163邮箱,配置允许代理发送邮件
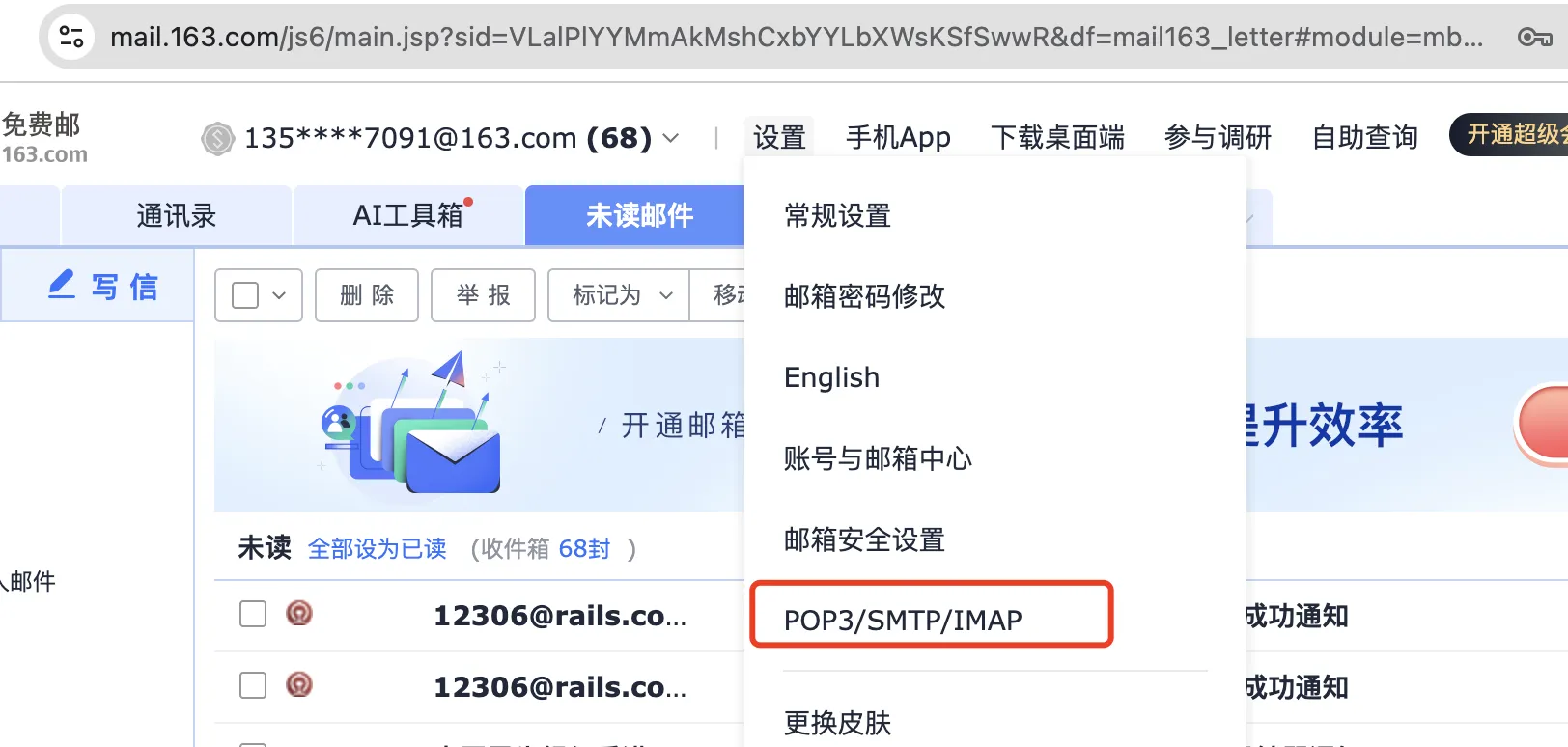
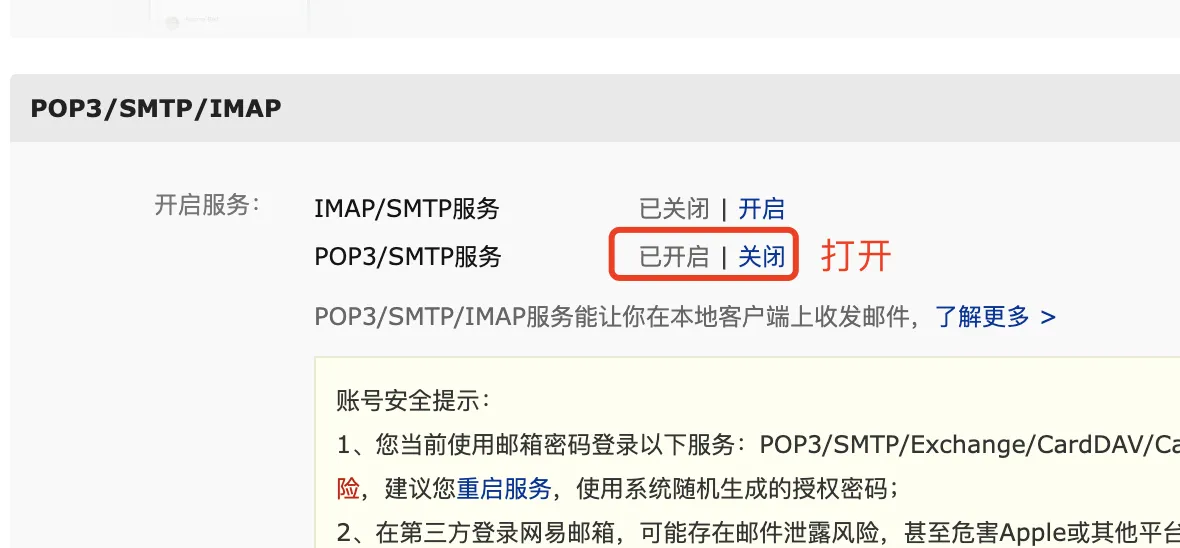
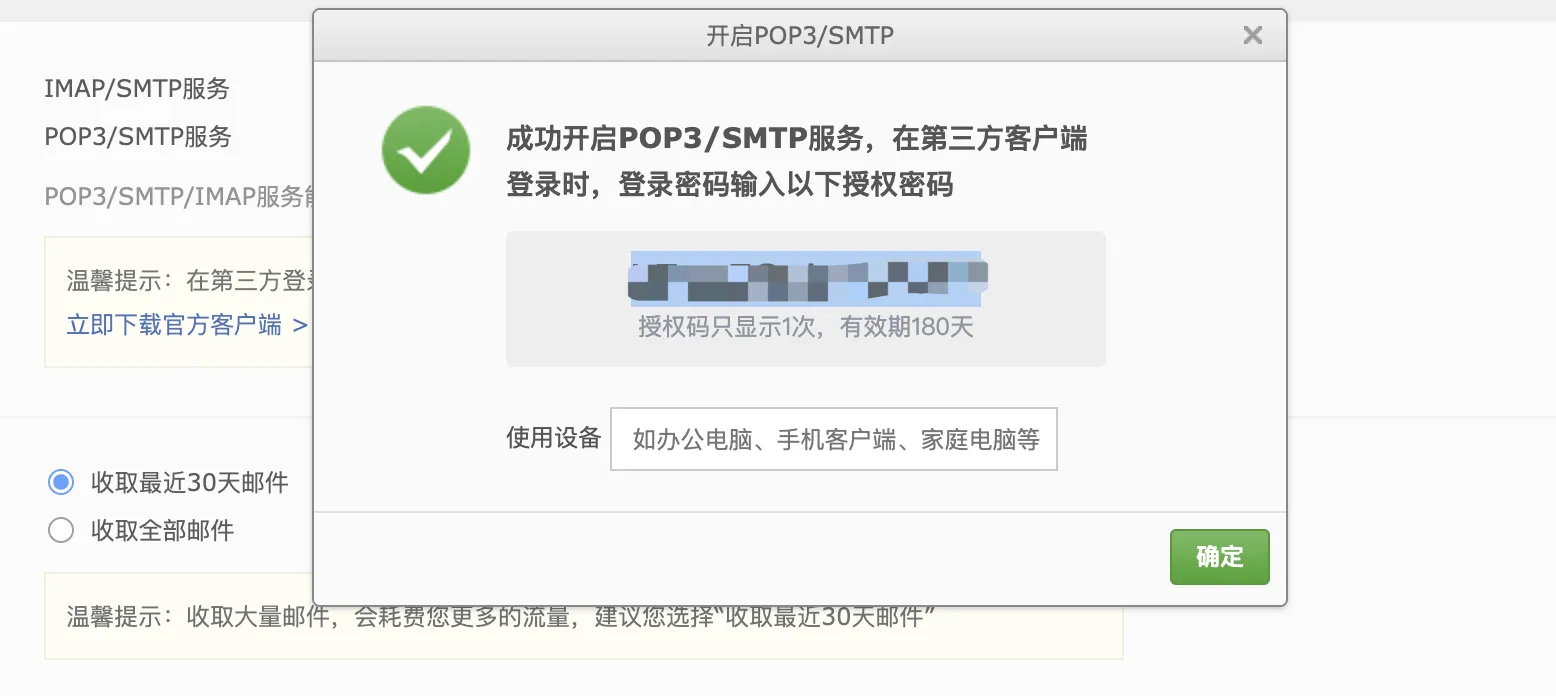
- linux配置
- Ubuntu 参考这篇文章
- Centos 是配置
/etc/mail.rc
sh# Centos 邮箱配置 /etc/mail.rc
#未加密的发送方式通过25端口,会被公有云封掉.
cat /etc/mail.rc EOF
set from=youmail@163.com
set smtp=smtp.163.com
set smtp-auth-user=youmail@163.com
set smtp-auth-password=刚才的授权码
set smtp-auth=login
EOF
#加密的方式465端口
cat /etc/mail.rc EOF
set nss-config-dir=/etc/pki/nssdb/
set smtp-user-starttls
set ssl-verify=ignore
set from=youmail@163.com
set smtp=smtps:smtp.163.com:465
set smtp-auth-user=youmail@163.com
set smtp-auth-password=刚才的授权码
set smtp-auth=login
EOF
# 配置加密方式发送邮件错误: Error in certificate: Peer's certificate issuer is not recognized
# 解决方法:
echo -n | openssl s_client -connect
smtp.163.com:465 | sed -ne '/-BEGIN
CERTIFICATE-/,/-END CERTIFICATE-/p' >
/etc/pki/nssdb/163.crt
certutil -A -n "GeoTrust SSL CA" -t "C,," -d
/etc/pki/nssdb/ -i /etc/pki/nssdb/163.crt
certutil -A -n "GeoTrust Global CA" -t "C,," -d
/etc/pki/nssdb/ -i /etc/pki/nssdb/163.crt
certutil -L -d /etc/pki/nssdb/
cd /etc/pki/nssdb/
certutil -A -n "GeoTrust SSL CA - G3" -t
"Pu,Pu,Pu" -d ./ -i 163.crt
网络管理
关于网络这一块,之前系统的写过几篇网络协议的的文章,这里就不重复写了。首先推荐看一下我的第一篇文章《计算机网络(一)网络接口层与网际层》。这篇文章比较清晰的讲明白了客户端与服务器通信的过程,网络是如何运转的。这篇文章的最后一段路有协议可以了解下,不用过分深入。其次(如果你还有时间)推荐看一下我的第二篇文章《计算机网络(二)传输层协议》,这里的TCP和UDP协议很重要, 无论是运维还是前后端都要懂一些。
下面我用一个问题“URL请求的过程”总结对第一篇文章的理解
URL请求的过程
- 应用层 --> 传输层 TCP+HTTP数据包 --> 网络层 IP +TCP数据包 --> 数据链路层 MAC + IP数据包 (这里需要arp协议将IP转换为MAC地址)
- 根据mac地址表,往交换机和路由器发送
- -->交换机 --> 路由器 (路由表逐跳)。。。
- 路由表中找到下一条地址,如果没有请求网关
- ---> 找到目标IP机器,解包 数据链路层(RARP) ----> 网络层 ----> 传输层 ----> 应用层
数据包回来的过程
其实前面省略了一个细节,本地请求 源IP是局域网, 目标IP是公网,发送请求没问题,但数据包回来就有问题了!
其实前一步请求的过程,经过路由器时会通过Nat技术,将源IP替换为公网IP, 这样响应的数据包就能找到这个路由器路由器在将目标地址替换为原局域网IP。
NAT技术是什么?
由于IPv4地址有限,催生了局域网技术,但公网不能往局域网发送数据,Nat技术就是通过端口映射的方式,使得局域网内的机器通过共享路由器的公网IP从而解决公网不能往局域网发送数据的问题。
当然运维读前面的两篇内容还是不够的,我再补充一些网络相关命令以及一些零碎的知识点。
我为什么人多了wifi信号就不好,怎么解决?
wifi信号不好, 去wifi的设置里面找一个叫信道的地方,改成不同的频率,不同的信道即可,这个信道里人少,你去用就会快,这个信道里人用的多,相互干扰 信号就不好
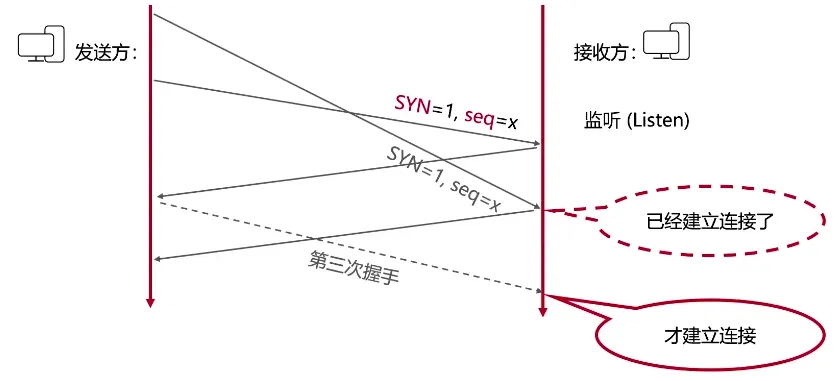
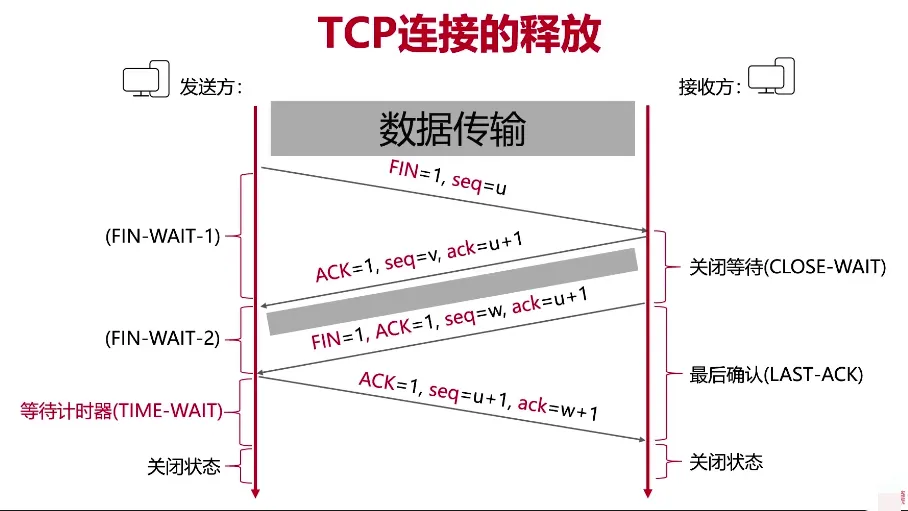
TCP的11种状态
先贴一下TCP三次握手,四次挥手的过程
| 三次握手 | 四次挥手 |
|---|---|
 |  |
文字描述如下
建立连接的过程
- 首先客户端服务端都处于
CLOSED状态 - 服务端开启Socket监听 服务端变成
LISTEN状态 - 客户端(谁先开始)发送请求(SYN=1,seq=x)客户端变成
SYN_SENT状态 - 服务端接收到请求回应(SYN=1,ACK=1,seq=y,ack=x+1), 服务端变成
SYN_RCVD状态 - 客户端收到请求,回复(ACK=1,seq=x+1,ack=y+1),客户端变成
ESTABLISHED状态(建立链接) - 服务端收到请求后也变为
ESTABLISHED状态
断开链接的过程
- 客户端(谁先开始)先向服务器发送FIN报文(FIN=1,seq=a)请求断开连接,其状态变为
FIN_WAIT1 - 服务端 收到FIN后像客户端发送了ACK(ACK=1,seq=b,ack=a+1),服务端状态变成为
CLOSE_WAIT, - 客户端收到ACK变成
FIN_WAIT2 - 服务端处理完手头任务接着发送FIN标志给客户端(FIN=1,ACK=1,seq=c,ack=a+1),状态变为
LAST_ACK - 客户端收到ACK后就进入
TIME_WAIT状态.此时连接已经断开了一半了。接着回复ACK给服务端(ACK=1,seq=u+1,ack=w+1) - 服务端收到消息变为
CLOSED状态 - 客户端等待2MSL,确认没有在收到服务端消息就断开连接,状态变为
CLOSED
上述过程共10种状态,还差一种异常状态,就是当断开连接的第2步,客户端没收到后服务端没发送,之后收到了服务端发的第四条消息,客户端会变成 CLOSING 状态,再等一会变成TIME_WAIT,然后再等2MSL变成 CLOSED 状态。
常见的网络协议
这里列一些重要的网路协议:以太网协议、ARP/RARP 协议、IP、DHCP、ICMP、TCP、UDP、DNS协议。相关内容推荐看我的网络协议的文章。
DNS解析补充内容
- window有dns缓存,linux下面没有
- hosts文件
- linux
/etc/hosts; - window
C:\Windows\System32\drivers\etc\hosts
- linux
Linux无法上网如何确认是否与DNS故障有关?
如果 ping baidu.com不通 但是ping ip可以,说明DNS有问题,要检查网卡配置了,可参考这篇文章
/etc/resolv.conf dns配置文件
网卡配置
网卡命令规则
在装系统的时候如果网卡名称不改是ens33,但后面可能遇到一些问题(因为有些软件只认eth0)
修改网卡名称为eth0有两种方式,
- 安装系统的时候修改
net.ifnames=0 biosdevname=0 - 系统安装完手动改
- 第1步: 修改
/boot/grub2/grub.cfg配置,linux16的行结尾加上net.ifnames=0 biosdevname=0 
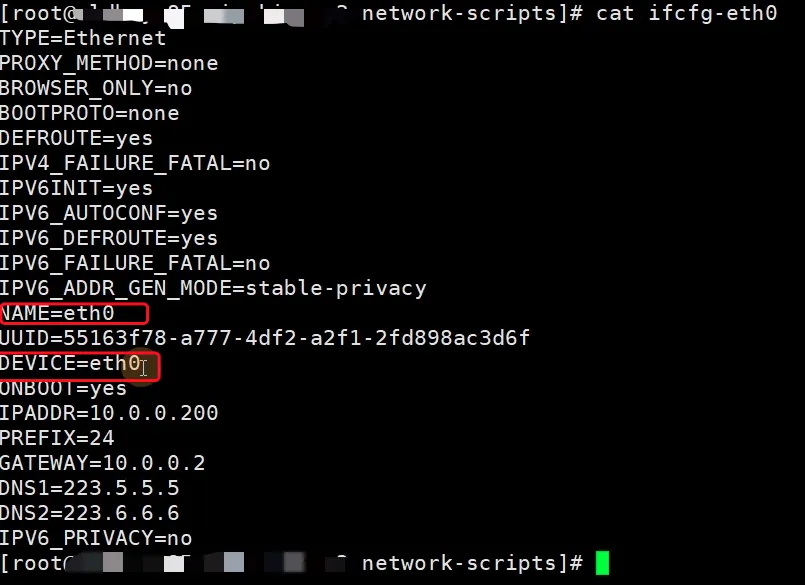
- 网卡配置文件名字改为eth0
cd //etc/sysconfig/network-scripts && mv ifcfg-ens33 ifcfg-eth0 - 接着修改文件内容
- 重启linux
- 第1步: 修改
重启网卡systemctl restart network
了解网卡配置文件格式
/etc/sysconfig/network-scripts/ifcfg-eth0
shTYPE=Ethernet #基本固定,网络类型: 以太网
BOOTPROTO=none #网卡固定ip还是自动获取ip(DHCP 自动分
配ip) dhcp自动获取 none或static#手动 设置Ip
NAME=eth0 #网卡名字
DEVICE=eth0 #设备名字
UUID=8e987179-762e-466e-aa40-fe38ebb012d0#统一设备符
#HWADDR=网卡的mac地址.
ONBOOT=yes #网卡是否自动运行(开机,重启网卡)
IPADDR=10.0.0.200 #ip地址
PREFIX=24 #子网掩码,设置这个局域网中最多有多少台机
器 #NETMASK=255.255.255.0
GATEWAY=10.0.0.2 #网关, 类似于大楼的出入口. 网络环境中
的流量出入口. 一般是3层路由
DNS1=223.5.5.5 #主配置dns地址
DNS2=223.6.6.6 #备DNS
常见的DNS DNS大全
网络管理命令
先来个总结
| 网络命令 | linux | windows |
|---|---|---|
| 查询ip地址 | ip/ifconfig | ipconfig |
| 检查端口号 | ss/netstat/lsof nc/telnet/nmap | ipconfig |
| 检查速度 | ss -ant /netstat -ant | netstat -ant |
| dns解析 | dig/host/nslookup | nslookup |
| 路径追踪 | traceroute | tracert |
| 查询当前系统配置的网关/路由信息 | ip ro /route -n | route print |
- 检查端口
检查端口根据是否登录进入服务器两种情况
如果已经进入了服务器
ss命令-l展示更详细信息-n展示端口而不是服务名-ttcp端口-uudp接口-p展示pid- 示例
ss -lntup |grep 22

netstat与ss效果一致,格式上有区别

如果网站访问量巨大 推荐 ss
lsof -ni :22查看某一个端口-n展示ip而非主机名-P展示端口而不是服务名
如果不在对应的服务器上
-
telnet 10.0.0.200 22# 检查是否有conneted标记 -
nc 10.0.0.200 22#同上-v展示过程telnet和nc作用一样,命令行推荐telnet,写脚本推荐nc
-
nmap网络扫描工具。nmap -p 22 10.0.0.200nmap -p1-100 10.0.0.0/24 jd.com taobao.com
- 网络速度
iftop
-n#显示ip而非主机名-i指定网卡. 默认eth0 第1个网卡.-P显示端口-N不要把端口解析为服务名字
示例 iftop -nNP -i eth0 #显示端口号,不要把ip解析为域名,不要把端口解析为服务, 监视指定网卡eth0

查看进程的流量情况.
- 方案1 iftop,ss,ps 一起使用
- iftop找出端口
- ss找出端口对应的进程号(pid)
- ps根据pid过滤进程名字
- 方案2
nethogs 网卡示例nethogs eth0
- DNS解析
dig命令 查找域名的ip dig www.baidu.com`
dig +trace jd.com 从根找
dig @8.8.8.8 www.baidu.com 查找域名的ip 限定dns服务器为8.8.8.8
dig/host/nslookup 三个命令差不多只是展示格式不同
- 追踪命令
检查线路是否通畅.
pingtracert(windows)traceroute(linux ) 路径追踪
traceroute -nI www.baidu.com
- -I默认使用udp协议,-I使用 icmp协议
抓包
通常window上使用wireshark抓包, linux上使用tcpdump抓包保存下载下来,导入wireshark进行分析。
linux tcpdump抓包保存示例脚本tcpdump -vvv -nn -i eth0 port 80 or port 53 -w http-dns.pcap
| 抓包工具 | 特点 |
|---|---|
wireshark | 可视化抓包工具. win/mac/linux |
fiddler | 代理,所有流量走fiddler,然后出去. |
tcpdump | linux自带 |
burpsuite | 抓包,修改数据包 |
| 过滤条件 | wireshark | tcpdump |
|---|---|---|
| 指定协议 | icmp/tcp/http | icmp/tcp/udp |
| 指定端口 | tcp.port 80 或 udp.port 53 | port 80 tcp或 udp port 53 |
| 过滤出源端口 | tcp.srcport 80 | src port 80 |
| 过滤目标端口 | tcp.dstport 80 | dst port 80 |
| 指定ip的数据包 | ip.addr 10.0.0.200 | host 10.0.0.200 |
| 过滤出源ip | ip.src 10.0.0.200 | src host 10.0.0.200 |
| 过滤出目标ip | ip.dst 10.0.0.200 | dst host 10.0.0.200 |
| 正则 | 字段(指标)字符串 ~或matches 匹配正则,"正则" | 无 |
| 与 | && 或 and | and |
| 或 | ||
| 非 | ! | ! |
| 选项 | 无 | -w保存数据包 -i指定网卡-vvv -nnn |
关于wireshark和tcpdump的具体使用略(有时间再写吧)
本文作者:郭郭同学
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!